点击上方“朱小厮的博客”,选择“
设为星标”
后台回复”
1024
“获取公众号专属1024GB资料
来源:rrd.me/fLHvf
1.引言
分支预测是计算机科学中一个有趣的概念,它对我们的应用程序性能会产生深刻的影响。然而,
这个概念通常没有得到很好地理解,大多数开发者对此很少关注。
本文中,我们将探索分支预测的确切含义,如何对软件产生影响,以及我们可以采取的行动。
2.什么是指令流水线?
开发计算机程序,本质上是编写一组期望计算机顺序执行的命令。
早期的计算机一次仅执行一条命令。这意味着每个命令都会加载到内存中,执行完成后再加载下一个命令。
指令流水线是一种改进。处理器会将工作分解成多个部分,对不同的部分并行执行。这样,处理器能够在加载下一条的同时执行一条命令。
处理器内部的指令流水线越长,不仅可以简化还能并行执行更多的部分。这样能够提高系统的整体性能。
例如下面这个简单的程序:
int a = 0;
a += 1;
a += 2;
a += 3;
程序会按照下面的流水线处理:Fetch(提取)、Decode(解码)、Execute(执行)、Store(存储):
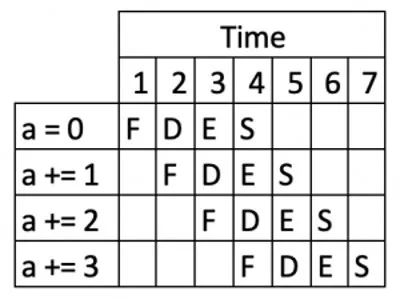
这里可以看到四个命令如何并行处理,整体执行速度更快。
3.有什么危害?
处理器执行某些命令时会导致流水线问题
。
流水线中部分指令执行时依赖于之前的指令,但是前面的指令可能还没有执行。
分支是一种危险。分支会挑选两个执行方向之一执行,但只有在解析后才能确定是哪个方向。这意味着
通过分支加载命令都是不安全的,因为无法知道从哪里加载命令
。
修改上面的程序加入分支:
int a = 0;
a += 1;
if (a < 10) {
a += 2;
}
a += 3;
运行结果与之前相同,但其中加入了 if语句。
在解析前,虽然计算机能看到这些指令,但不能加载 if 后面的指令
。因此,执行的顺序看起来像下面这样:
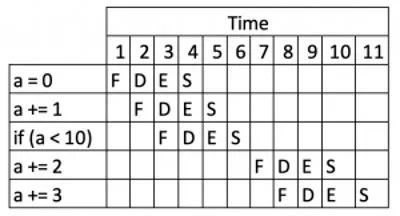
现在可以立刻看到加入分支对程序执行造成的影响,得到相同结果所需的时钟周期。
4.什么是分支预测?
分支预测是对上面的一种改进,计算机会尝试预测分支的执行路径,然后采取相应的动作。
在上面的示例中,处理器会预测if(a <10)为 true,因此把 a += 2 作为下一条待执行指令。这将导致执行的顺序变成这样:
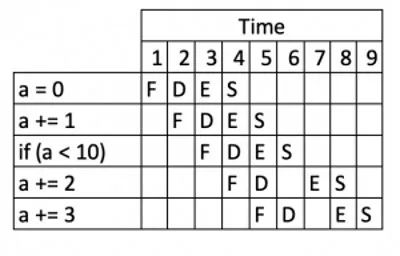
可以看到程序的性能立即得到了提升:
现在只要9个时钟周期而不是之前的11个,速度提升了19%。
但是,这样做也并非没有风险。如果分支预测出错,那么将对不应该执行的指令排队。发生这种情况时,计算机要丢弃这些指令重新开始。
修改判断条件改为false:
int a = 0;
a += 1;
if (a > 10) {
a += 2;
}
a += 3;
可能会像下面这样执行:
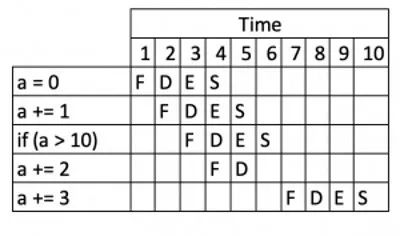
现在,即使处理的指令更少,执行却比之前慢!处理器错误地预测分支等于 true,把 a += 2 指令排队。接着发现分支等于 false,必须丢弃已排队的指令,然后重新执行。
5.对实际代码的影响
现在我们知道分支预测的概念及优点,那么对实际代码有什么影响?毕竟,
这里讨论的是在高速运行的计算机上损失几个时钟周期,影响肯定不会那么明显。
有时候的确如此。但也有一些情况会对应用程序性能带来显著影响。很大程度上取决于进行的工作。具体来说,与在短时间内需要完成的工作有关。
5.1.统计列表条目
让我们试着统计列表中的条目。接下来会生成一个数字列表,然后统计其中有多少个数字小于临界值。与上面的示例类似,但是用循环取代了单个指令:
List numbers = LongStream.range(0, top)
.boxed()
.collect(Collectors.toList());
if (shuffle) {
Collections.shuffle(numbers);
}
long cutoff = top / 2;
long count = 0;
long start = System.currentTimeMillis();
for (Long number : numbers) {
if (number < cutoff) {
++count;
}
}
long end = System.currentTimeMillis();
LOG.info("Counted {}/{} {} numbers in {}ms",
count, top, shuffle ? "shuffled": "sorted", end - start);
请注意,这里只对计数循环计时,因为这才我们感兴趣的工作。那么需要多少时间呢?
如果生成的列表较小,那么代码执行很快,无法统计:10万条数据的列表执行结果为0毫秒。但是当列表足够大时,可以看到计时结果中 shuffle 条件对结果有显著影响。包含1000万个数字的列表:
-
Sorted – 44ms
-
Shuffled – 221ms
也就是说,即使计算的数据相同,随机(shuffled)列表用时是排序后的5倍。
但是,排序操作本身的开销比计数要大得多。我们应该分析自己的代码,确定是否有性能提升的空间。
5.2.分支顺序
从上面的内容可以看出,
if/else 语句的分支顺序很重要
。也就是说,下面这样的分支安排性能会更好:
if (mostLikely) {
// Do something
} else if (lessLikely) {
// Do something
} else if (leastLikely) {
// Do something
}
然而,
现代计算机可以通过分支预测缓存来避免这个问题
。实际上,也可以对此进行测试:
List numbers = LongStream.range(0, top)
.boxed()
.collect(Collectors.toList());
if (shuffle) {
Collections.shuffle(numbers);
}
long cutoff = (long)(top * cutoffPercentage);
long low = 0;
long high = 0;
long start = System.currentTimeMillis();
for (Long number : numbers) {
if (number < cutoff) {
++low;
} else {
++high;
}
}
long end = System.currentTimeMillis();
LOG.info("Counted {}/{} numbers in {}ms", low, high, end - start);
计算1000万个数字时,无论 cutoffPercentage 如何设置,代码执行的结果基本一致:排序数字约35毫秒,随机数字约200毫秒。
这是因为
分支预测器会平等地处理两个分支
,并正确猜测我们将采用其中哪一个。
5.3.合并条件
使用一个条件和两个条件有什么区别?
相同的结果可以用不同方式重写实现逻辑,是否应该这样做?
例如,可以用两个数字分别与0比较,也可以用两个数字的乘积与0比较。用乘法代替条件。这种做法是否值得?
让我们考虑下面这个例子:
long[] first = LongStream.range(0, TOP)
.map(n -> Math.random() < FRACTION ? 0 : n)
.toArray();
long[] second = LongStream.range(0, TOP)
.map










