论文名称:MaGGIe: Masked Guided Gradual Human Instance Matting
文章地址:
https://arxiv.org/abs/2404.16035
项目地址:
https://maggie-matt.github.io/
摘要
人体抠图是图像和视频处理中的一项基础任务,旨在从输入中提取人体前景像素。马里兰帕克分校和Adobe研究院的研究人员提出新框架MaGGIe,即掩码引导人体实例抠图。该框架在保持计算成本、精度和一致性的同时,逐步预测人体实例的alpha通道。该框架由Transformer注意力和稀疏卷积构成,其在保持计算成本、精度和一致性的同时实现了更高质量的抠图mattes,并创建了新抠图数据集。
 图:MaGGIe(该研究)与InsMatt对比
图:MaGGIe(该研究)与InsMatt对比
引言
在图像抠图中,一个简单的解决方案是预测像素的透明度- alpha通道,以精确地去除背景,考虑具有前景和背景两个主要成分的显著性图像。由于检测前景区域的模糊性,例如,一个人的物品是否属于人体前景的一部分,许多研究利用trimaps定义前景、背景和未知或过渡区域,但是在视频中创建trimaps需要消耗大量资源。相比于trimaps,替代的二进制掩码更容易通过绘图或现成的分割模型获得,提供更大的灵活性。
在处理视频输入时,随着视频长度的增加,trimap图的传输性能下降。在trimap预测中,由于错误的预测,比如前景-未知-背景区域之间的对齐,会导致不正确的alpha通道。相比之下,对每一帧使用二进制掩码可以得到更鲁棒的结果。然而,帧输出之间的一致性对于视频抠图方法仍然很重要。许多研究约束了帧间特征映射的时间一致性。在视频分割和抠图中,一些研究通过计算不相干区域来跨帧更新值。本研究(MaGGIe模型)提出了一个时间一致性模块,可以在特征和输出空间中工作,以产生一致的alpha通道。
InstMatt模型在进行实例细化之前,通过从二进制引导掩码中分别预测每个alpha通道来处理多实例图像。尽管该方法性能良好,但该模型的效率和准确性在视频处理中尚未进行分析。上图反映了MaGGIe和InstMatt在处理视频时的性能比较,MaGGIe不仅提高了精度,而且提高了各帧之间的一致性。
除了时间一致性外,在将实例抠图扩展到包含大量帧数和实例的视频时,如何精心设计网络以防止计算成本激增也是关键挑战。为解决该问题,该研究在网络设计上进行调整。首先,利用AOT启发的掩码引导嵌入,将输入大小减小到恒定的通道数。其次,根据各种视觉任务中Transformer注意力的进展,该研究继承了基于查询的实例分割,在一次前向传递中预测实例mattes,而不是分离估计,并通过注意力机制取代了以前复杂的细化工作。为了节省Transformer关注的高成本,该模型只在粗层次上进行多实例预测,并在多尺度上进行逐步细化。替换为稀疏卷积大大节省了推理成本,保持了算法的恒定复杂度。
网络模型
 图:MaGGIe模型架构
图:MaGGIe模型架构
1.有效的掩码引导实例抠图
该框架处理具有二进制实例引导掩码M的图像或视频帧I,并且预测每一个实例每一帧的Alpha通道。(1)输入构建:将输入图像I和引导嵌入E进行连接。(2)图像特征提取:利用特征金字塔网络,从输入图像I中提取特征映射Fs。(3)实例alpha 通道预测:本研究采用Transformer注意力来预测最粗糙特征F8上的实例问题,对点积注意机制进行变更。在解码器中,将缩小的引导掩码M8加入注意力过程。(4)逐级细化:利用MLP将密集特征F8转化为实例特征X8。运用Instance Guidance模块将特征X8与图像特征F4相结合,生成稀疏实例特征X4。然后将稀疏特征X4分别与其他密集特征F2、F1聚合,得到X2、X1。在每个尺度上,预测alpha通道A4和A1,实现逐级细化。(5)从粗糙到精细处理信息:将不同尺度的alpha通道按递进方式进行组合:A8→A4→A1得到A,每一步只细化不确定位置和属于未知掩码的值。(6) 训练损失:除了标准损失(L1,Laplacian Llap,Gradient Lgrad)之外,增加通过注意损失Latt来监督实例token和图像特征映射之间的亲和得分矩阵。此外,自定义权重W8以反映网络的逐步细化过程中粗级预测程度。
2. Feature-Matte 时间一致性
(1)特性时间一致性:利用对视频输入运用Conv-GRU,网络保证了相邻帧的特征映射之间的双向一致性。(2)Alpha通道时间一致性:通过预测帧的时间稀疏度来融合帧抠图。(3)训练损失:引入时间一致性的dtSSD损失和Alpha通道差异的L1损失。
实验结果:
1. 图像数据训练结果
评估指标
:指标包括平均绝对差(MAD)、均方误差(MSE)、梯度(Grad)和连通性(Conn)。研究人员分别计算了前景和未知区域的上述指标,表示为MADf和MADu。因为图像包含多个实例,所以度量是为每个实例单独计算的,然后取平均值。
消融研究
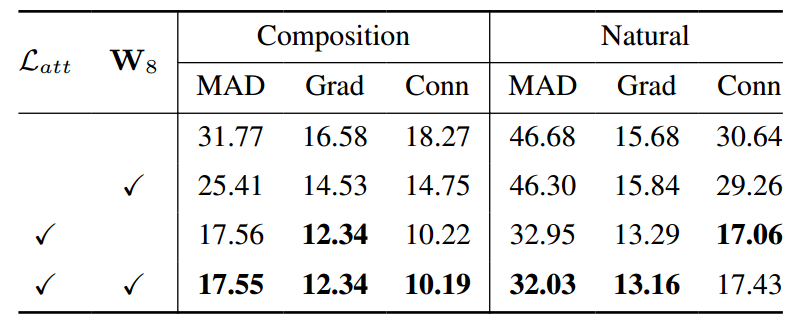
:每个消融研究设置训练了10,000次迭代,批大小为96。下表反映了嵌入层与堆叠掩码和图像输入的性能。嵌入层的性能得到了改善,当Ce = 3时效果尤为显著。下表评估了在训练中使用Latt和W8的影响。Latt显著提高了模型的性能,而W8的使用获得了轻微的提升。
表:HIM2K+M-HIM2K数据集上叠加掩码嵌入的性能对比
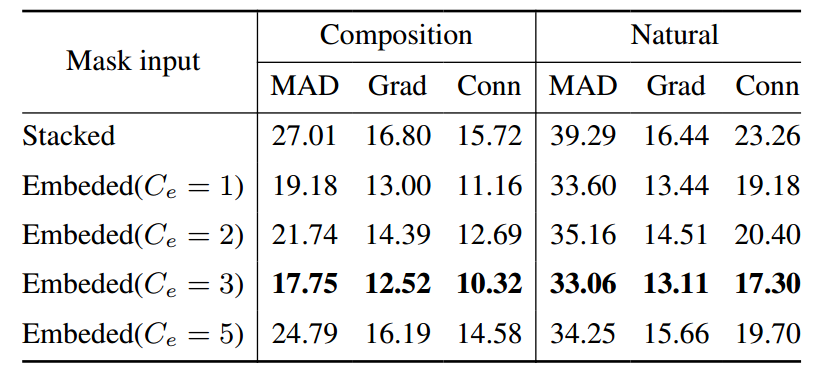
表:HIM2K+M-HIM2K数据集上Latt和W8参数性能对比
定量结果
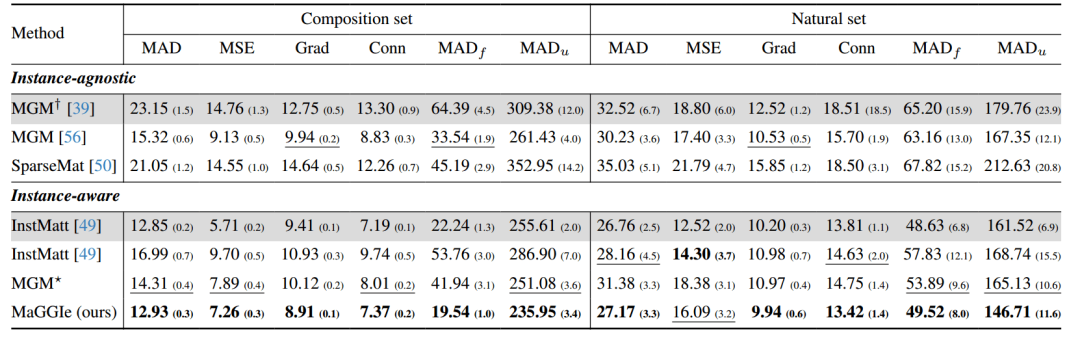
:在定量测试中,引入多个对比模型,例如,MGM ,MGM
,InstMatt等,如下表所示。MaGGIe模型在复合集和自然集上显示了较好的结果,在大多数指标上实现了最低的误差。同时,MGM
模型也表现良好,这表明同时处理多个掩码可以促进实例交互。同时,该实验在M-HIM2K数据集上测量了模型的内存和速度,InstMatt, MGM和SparseMat的推理时间随实例数量线性增加,但MGM -和MaGGIe模型在内存和速度上都保持稳定的性能。
表:HIM2K+M-HIM2K数据集上不同模型性能对比
定性结果
:MaGGIe捕捉细节和有效分离实例的能力如上表所示。在精确的分辨率下,MaGGIe模型可以与每个实例单独运行MGM模型的性能相媲美,并且超过了公开版本和重新训练版本的InstMatt。MaGGIe模型能够熟练地区分不同的实例,其实例分离功能突出了它在处理复杂的抠图场景时的有效性。
2 视频数据训练结果
时间一致性评估指标
:增加了评估指标,包括dtSSD和MESSDdt,以评估跨帧实例抠图的时间一致性。
表:消融实验在时间一致性上的性能对比
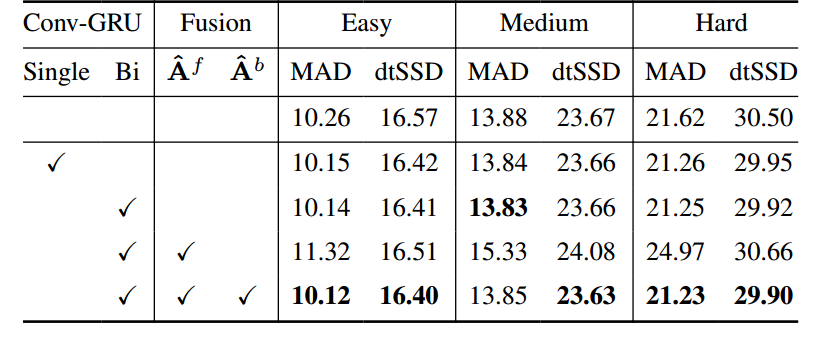
消融实验
:如上表所示,单向Conv-GRU的使用改善了结果,并通过添加反向融合获得了进一步的效益。单独的前向融合效果较差,可能是由于误差传播。最优的网络设置包括结合反向传播来减少误差,从而产生最佳结果。
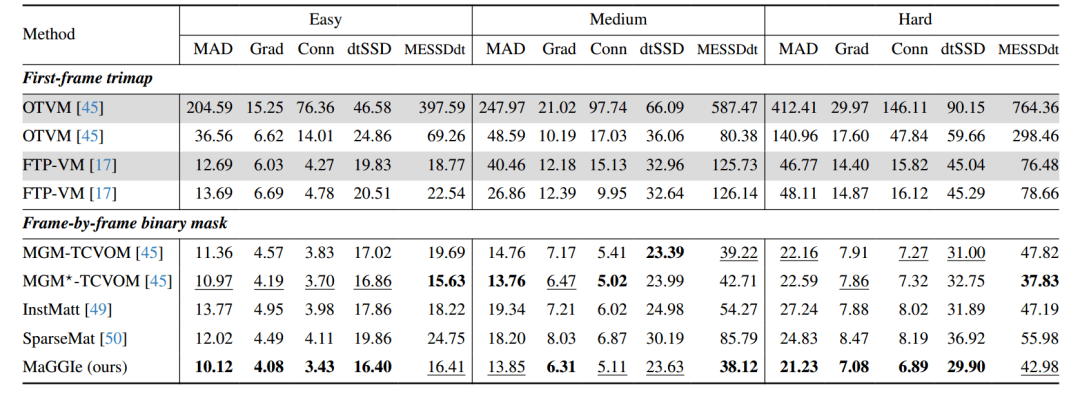
性能评估
:实验结果如下表所示,该研究提出的MaGGIe模型在大多数指标上表现优于其他对比模型,特别是在需要高时间一致性和细节保存的具有挑战性的场景中。该模型在dtSSD和MESSDdt指标上表现出色,具有良好的时间一致性。同时,该模型在Grad指标上优于其他对比模型,在捕获精细细节上性能卓越。
表:不同模组在V-HIM60数据集上的性能对比
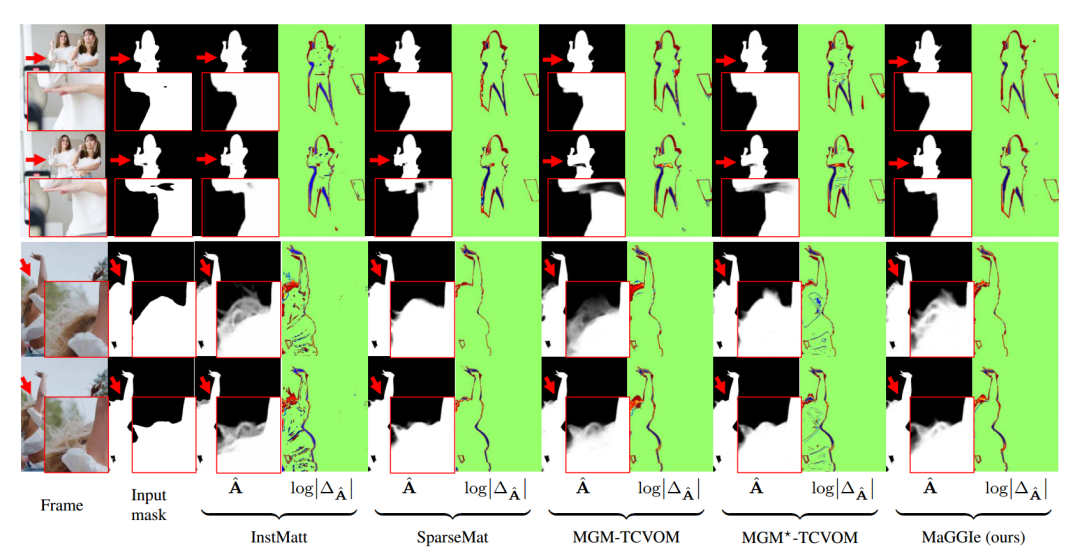
时间一致性和细节保存
:如下图所示,该模型在视频实例抠图上的性能亮点包括:
-
随机噪声的处理:有效处理了掩码输入中的随机噪声,优于其他与不一致的输入掩码质量处理的方法。
-
前景/背景区域一致性:跨帧保持一致,准确的前景预测,超过InstMatt和MGM⋆-TCVOM。
-
细节保存:模型保留了复杂的细节,与InstMatt性能相当,优于MGM模型变体。上述实验结果反映了MaGGIe在视频实例抠图中的鲁棒性和有效性,特别是在保持时间一致性和保留跨帧的精细细节方面。
总结:
通过结合Transformer注意力和稀疏卷积等先进技术,MaGGIe在图像和视频输入的细节准确性、时间一致性和计算效率方面都比以前的方法有了很大的改进。此外,该研究在综合训练数据和开发综合基准模式方面的方法为评估模型在实例抠图任务中的鲁棒性和有效性提供了一种新的方法。









