文章目录:
-
1 Dataset基类
-
2 构建Dataset子类
-
2.1 __Init__
-
2.2 __getitem__
-
3 dataloader
1 Dataset基类
PyTorch 读取其他的数据,主要是通过 Dataset 类,所以先简单了解一下 Dataset 类。在看很多PyTorch的代码的时候,也会经常看到dataset这个东西的存在。Dataset类作为所有的 datasets 的基类存在,所有的 datasets 都需要继承它。
先看一下源码:

这里有一个
__getitem__
函数,
__getitem__
函数接收一个index,然后返回图片数据和标签,这个index通常是指一个list的index,这个list的每个元素就包含了图片数据的路径和标签信息。
之后会举例子来讲解这个逻辑
。
其实说着了些都没用,因为在训练代码里是感觉不到这些操作的,只会看到通过DataLoader就可以获取一个batch的数据,这是触发去读取图片这些操作的是DataLoader里的
__iter__(self)
(后面再讲)。
2 构建Dataset子类
下面我们构建一下Dataset的子类,叫他MyDataset类:
import torch
from torch.utils.data import Dataset,DataLoader
class MyDataset(Dataset):
def __init__(self):
self.data = torch.tensor([[1,2,3],[2,3,4],[3,4,5],[4,5,6]])
self.label = torch.LongTensor([1,1,0,0])
def __getitem__(self,index):
return self.data[index],self.label[index]
def __len__(self):
return len(self.data)
2.1
Init
-
初始化中,一般是把数据直接保存在这个类的属性中。像是
self.data,self.label
2.2
getitem
-
index是一个索引,这个索引的取值范围是要根据
__len__
这个返回值确定的,在上面的例子中,
__len__
的返回值是4,所以这个index会在0,1,2,3这个范围内。
3 dataloader
从上文中,我们知道了MyDataset这个类中的
__getitem__
的返回值,应该是某一个样本的数据和标签(如果是测试集的dataset,那么就只返回数据),在梯度下降的过程中,一般是需要将多个数据组成batch,这个需要我们自己来组合吗?不需要的,所以PyTorch中存在DataLoader这个迭代器(这个名词用的准不准确有待考究)。
继续上面的代码,我们接着写代码:
mydataloader = DataLoader(dataset=mydataset,
batch_size=1)
我们现在创建了一个DataLoader的实例,并且把之前实例化的mydataset作为参数输入进去,并且还输入了batch_size这个参数,现在我们使用的batch_size是1.下面来用for循环来遍历这个dataloader:
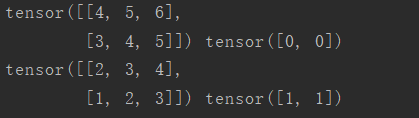
for i,(data,label) in enumerate(mydataloader):
print(data,label)
输出结果是:
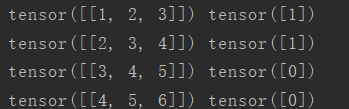
意料之中的结果,总共输出了4个batch,每个batch都是只有1个样本(数据+标签),值得注意的是,这个输出过程是
顺序的
。
我们稍微修改一下上面的DataLoader的参数:
mydataloader = DataLoader(dataset=mydataset,
batch_size=2,
shuffle=True)
for i,(data,label) in enumerate(mydataloader):
print(data,label)
结果是:
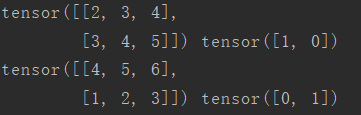
可以看到每一个batch内出现了2个样本。假如我们再运行一遍上面的代码,得到: