train? valid? or test?
机器学习(http://cn.udacity.com/course/machine-learning-engineer-nanodegree--nd009-cn-basic)最明显的一个特点是需要大量的数据。特别对监督学习来说,就是需要大量的带标签数据(labeled data)。
很多入门的朋友很快就会遇见模型训练和测试这两个阶段,进而也就了解到带标签数据是要被划分成两个部分的:训练集(training set)与测试集(test set)。这两个概念也很直观,大部分朋友非常快就能接受。
可是到后面,在我们需要为机器学习模型调参的时候,半路杀出来了个交叉验证(cross validation)阶段,这个对应的数据集也有个名字,叫做验证集(validation set)。
据我观察,很多机器学习(入门)的朋友在这个时候就会感到一头雾水,并且非常困惑:咋又冒出来了个验证集啊?我们不是有个测试集了吗?直接在那上面做实验不就好了么?又划分多一个数据集,那就使得能用于训练和测试的数据都变少了,验证集是那方神圣啊?...
这里我给你们来个非常形象的类比!别眨眼!
训练集 → 题解大全
验证集 → 模拟考试
测试集 → 高考!
是不是非常形象易懂呢?(得意脸)
呃?搞不懂为什么是这样的对应关系?别急我还没说完呢。
机器学习算法是个笨学生,他没法直接从人类教师那里学会抽象的概念,于是唯一有效的策略就是天赋不足勤来补:玩命刷题! 想想看带标签的训练数据,是不是很像你平时做的习题册呢? 数据本身是题目,标签是正确答案。所以机器学习算法能够通过大量做题来学会抽象概念(但是这个傻孩子实际上只学会了怎么解答与特定抽象概念相关的问题)。
你说你学会了东西,但空口无凭啊,你得通过考试来证明自己!于是就有了测试集。测试集相当于考试的原因是,你只能看到题目(数据)而无法得知答案(标签)。你只能在交卷之后等老师给你打分。
于是就有朋友发问了:“那我一遍一遍考试来证明自己不就好?我大学挂科补考还少么?”。首先心疼你一秒钟。然后请你思考这个问题,如果那场考试是高考怎么办?你耗得起吗?
所以我们需要模拟考试,也就是验证集。我们可以获得验证集的标签,但是我们假装得不到,让自己以考试的心态去面对,过后也就能通过自己对答案来了解自己到底学会了多少,而这种几乎没有成本的考试我们想进行多少次都行!这就是验证集存在的意义!你的模型只能在测试集上面跑一次,一考定终身!
我们需要验证集的真正原因是:防止机器学习算法作弊!我们训练一个机器学习模型不是为了让它在那有限的带标签数据high个够,而是要将模型应用于真实世界。绝大多数情况下,我们无法直接从真实世界获得答案,我们能收集到的数据是没有标签的裸数据,我们需要高效准确的机器学习模型为我们提供答案。不能直接使用测试集不是因为我们负担不起在测试集上跑模型的成本(事实上几乎为0),而是因为我们不能泄露测试集的信息。试想一下,假如你搞到了真正的高考题和答案,你一遍又一遍地去做这套题目,会发生什么?也许你会成为高考状元,可是你真的学会这些知识了吗?你能够再去做一套高考题并且拿高分吗?你能够去当家教向学弟学妹传授你的知识和解答他们的问题吗? 偷窥到了测试集的机器学习模型就是废品,没有人需要它,它也做不了任何有用的事情。
切记,你的机器学习模型只能在测试集上跑一次,一考定终身!
切记,你的机器学习模型只能在测试集上跑一次,一考定终身!
切记,你的机器学习模型只能在测试集上跑一次,一考定终身!
切记,你的机器学习模型只能在测试集上跑一次,一考定终身!
切记,你的机器学习模型只能在测试集上跑一次,一考定终身!
超级重要的事情说五次还嫌少,我得加粗了才行。哦还得加大字号,我怕你近视眼看不见!
都说到这个地步了,顺便借这个类比说说过拟合(overfit)和欠拟合(underfit)的事吧。过拟合的模型是个真正的书呆子,玩命刷题解大全(Demidovich ),但是只记住了所有的习题和答案,去做模拟考试就直接傻掉了。欠拟合的模型就是个不听课还懒惰的学渣,连习题册上的题目都搞不懂,别说模拟考试了。高考?呵呵呵。
accuracy? precision? recall?
accuracy 就是百分制的考试分数,我是想不到要怎么解释了。(抠鼻)
precision 和 recall 倒是有两个非常好的意象。
这里先说一下 precision 和 recall 哪来的。想象你在做一套全都是判断题的考试题,你的答案总会跟正确答案有些出入(学神,学霸和 overfit 的书呆子一边去)。
真阳性、假阳性、假阴性和真阴性
对比上面的表格很容易看出,你做对的题会对应着 真(True) 这个前缀,对了就对了,不管啦。而你做错的题则带了 假(False) 的前缀,做错的题分两种:你回答真但答案是假,这是假阳性;你回答为假但是答案为真,则为假阴性。很明显,阳性阴性是对应着你的回答。
那我们为啥需要这乱七八糟的东西?直接用 accuracy 来衡量不就好了?
假设你有一个大小为1000的带布尔标签数据集, 里面的“真”样本只有100个不到,剩下的都是“假”样本。你说这没什么啊? 别急,想象你训练了一个模型,不管输入什么数据,它都只给出“假”的预测。这显然是个失败模型,也就比停了的钟好一点(哦不对,是五十步笑百步),但是它在你这个数据上可能能拿到90分以上哦? 很明显,这个时候 accuracy 已经失去它的作用了。是时候让乱七八糟的概念上场了。
precision 严谨认真的普通日本人(https://www.zhihu.com/question/26581962/answer/144572050)
多做多错 少做少错 不做不错
precision 和 recall 一般只在有倾斜数据集的时候出来玩。我们一般把数量较少的样本叫阳性样本,一般情况下我们也只关心阳性样本的预测结果。最常见的倾斜数据例子是癌症检查,得了癌症的不幸的人就是阳性样本,相对于健康的大众,他们是稀少的存在。

精确率 等于 真阳性 与 所有被预测为阳性的样本 之比。
为什么说多做多错少做少错的理由很明显了吧? 如果模型预测为阳性的样本越少,那么它犯错的可能性也就越小,也就是说精确率越高了。
思考题:一个精确率超级高的模型有什么问题?
recall 威武霸气的川普移民禁令
宁可错杀,不能放过
recall=True Positive / (True Positive + False Negaitive)
召回率 等于 真阳性 与 所有真正的阳性样本 之比
冤枉你就冤枉你咯,不服来咬我啊? —— 川普
川普爸爸近来又搞了个大新闻,多国移民禁止入境。理由当然是防止恐怖分子混入美利坚大地啦,你们这些国家的人素质太差动不动搞恐怖袭击,我实在没精力去一个个查,所以你们通通别来了,我乐得轻松。
recall 的公式里并没有假阳项,这说明它不关心自己冤枉了多少人,只要假阴的数量越少越好,恐怖分子一定不能漏了。
思考题:召回率与精确率是如何互相掣肘的?
Precision and recall 的配图也很棒,对比看看吧。
learning rate?
原本计划弄两个动图出来,可是 matplotlib 和 moviepy 死活导出不了 gif,想玩的自己复制代码吧。Github Gist (https://gist.github.com/filwaline/e487481efb0986b3dfca207e844fb14f)很简陋,不过这种东西也没必要做复杂是不是2333
学习率通常都会用步子的大小来形象比喻:
步子迈大了容易扯着蛋... 你会得到一个发散思维很强的模型...
步子走得太小啊... 你听说过闪电么?
好了正经点(一脸严肃)。计算完梯度以后,模型就需要更新它的参数了。loss函数的梯度指出了一个让 loss 函数提升最快的方向(没错是提升),学习率控制我们应该朝反方向走多远,学习率太大了可能会越过最低点,变得难以收敛甚至会发散。学习率调低一般就能避免走过头 (overshoot) 的问题了,但是调太低会让模型半天不挪窝,于是模型会收敛得很慢。这对小规模的机器学习问题影响不大,但是这个大数据时代是无法接受的。针对当前问题找一个合适的学习率很重要(机器玄学入门第一步),可惜一般只能靠猜靠试,现在有一些能帮你调整的学习率的算法,太超纲就不说了。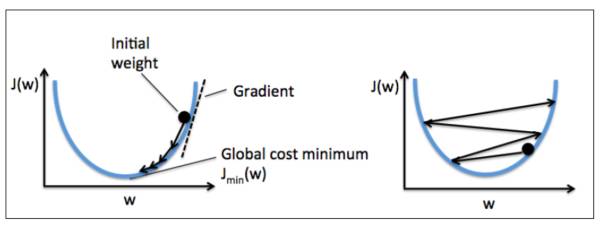
Hi,各位未来的机器学习工程师!
今晚有一场Udacity机器学习直播等你来看!
直播主题:
如何像升级打怪一样完成机器学习纳米学位!
直播内容:
1.如何评价吴恩达从百度离职
2.升级打怪一般搞定机器学习
3.Udacity 代码审阅有多狠
4.机器学习毕业项目巡礼
5.硅谷巨头机器学习面试题
6.Ask me anything
直播时间:
3/23(今晚) 8pm
直播地址:
https://zoom.us/j/198156310











