1 导读
论文《Neural Relation Extraction with Multi-lingual Attention》是我们之前ACL2016文章的一个扩展,将之前的 sentence-level selective attention的思想扩展到了多语言关系抽取上。
如今,神经网络模型已经可以在关系分类任务中取得了不错的效果。去年ACL2016上我们提出的句子级别选择注意力机制(sentence-levelselective
attention)较好的解决了远程监督(distantsupervision)数据中的噪音问题,使得神经网络模型也可以应用于关系抽取。然而,现有的关系抽取系统一般都只使用单语言数据,忽略了多语言数据可以带来的好处。
事实上,虽然世界各地的人们使用着不同的语言,但是他们对事物的认识是相似的。例如,虽然美国人说“New York is a city of United States”,而中国人说“纽约是美国的一座城市”,但是我们都肯定同一个事实(New York, city of, United States)。因此,我们可以利用多语言数据来帮助现有的关系抽取任务提升效果。
那么现在的问题在于我们存在两种不同的利用多语言数据的方式:a. 为不同的语言分别建立关系抽取系统;b. 建立一个联合的关系抽取系统。哪一种方式会更加合理呢?我们认为是后者,主要原因有以下两点:
(1)不同语言的数据之间拥有互补性。我们发现在我们利用Wikidata和New YorkTimes构建的多语言关系抽取数据中,中英文数据分别拥有41.6%和42.2%的单独的事实。另外,我们发现数据中超过一般的关系在中英文中拥有的数据量差异非常大。因此我们认为建立一个联合的关系抽取系统可以提高不同语言的关系抽取效果,尤其是对于一些数据比较少的语言来说更是如此。
(2)不同语言的数据之间拥有一致性。我们发现远程监督标注的表达事实的句子都非常长,在我们使用的语料中有近乎一半的句子长度都超过了20。而对于表达同一个事实的句子,在不同语言中一般只有精确表达这个事实语义部分会有一致性。例如下面的例子:

我们发现基本只有表达“纽约是美国的一座城市”的部分是语义上相似的。因此,我们可以利用这一性质找到表达事实语义更精确的句子进行学习和预测。
本文我们对之前的模型进行了扩展,在多语言数据上提出了单语言选择注意力机制(mono-lingual attention)和跨语言选择注意力机制(cross-lingual attention),建立了一个基于多语言选择注意力机制的关系抽取模型。
2 模型
我们提出的基于多语言选择注意力机制的关系抽取主要包括以下几个部分:
1.句子编码器(Sentence Encoder),可以是现有的CNN、PCNN和LSTM等常用的句子编码器,相信大家都非常熟悉了,这里就不具体展开讲了
2.单语言选择注意力机制和跨语言选择注意力机制。如下图所示:
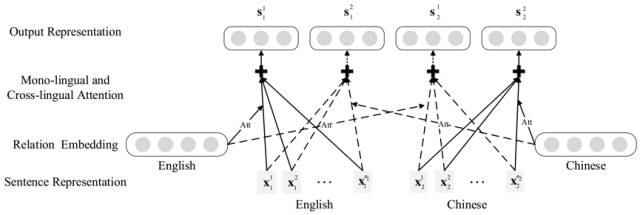
其中:
a. 实线部分为单语言选择注意力机制,实现方式为对于一种语言的某一对实体的所有句子表示向量,使用本语言的关系表示向量对其进行选择最终加权获得该实体对的表示;
b. 虚线部分为跨语言选择注意力机制,实现方式为对于一种语言的句子表示向量,依次使用所有语言的关系表示向量对其进行选择最终加权获得该实体对的表示
这样如果有m种语言,我们最终可以获得m*m种对于实体对的表示,分别表示为{Sjk|j,k∈{1,…,m}}
3.关系预测器,这里我们采用了两种关系矩阵来对关系进行预测,分别是用于刻画关系的全局语义的全局关系矩阵M和用于刻画关系在特定语言下特性的特定语言关系矩阵Rk,最终关系r的评分函数如下:
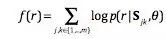
其中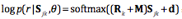 ,Θ表示模型的所有参数。
,Θ表示模型的所有参数。
论文链接:
http://thunlp.org/~lyk/publications/acl2017_mnre.pdf
原文链接:
https://mp.weixin.qq.com/s/upAnMVAsHE4GmWWvRpwgHA








