本文将以“帖子中心”为例,介绍“
1
对多”类业务,随着数据量的逐步增大,数据库性能显著降低,数据库水平切分相关的架构实践:
-
如何来实施水平切分
-
水平切分后常见的问题
-
典型问题的优化思路及实践
一、什么是
1
对多关系
所谓的“
1
对
1
”,“
1
对多”,“多对多”,来自数据库设计中的“实体
-
关系”
ER
模型,用来描述实体之间的映射关系。
1
对
1
这是一个
1
对
1
的关系。
1
对多
这是一个
1
对多的关系。
多对多
-
一个用户可以关注
多个
用户
-
一个用户也可以被
多个
粉丝关注
这是一个多对多的关系。
二、帖子中心业务分析

帖子中心是一个典型的
1
对多业务。
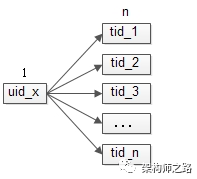
一个用户可以发布多个帖子,一个帖子只对应一个发布者。
任何脱离业务的架构设计都是耍流氓
,先来看看帖子中心对应的业务需求。
帖子中心
,是一个提供帖子发布/修改/删除/查看/搜索的服务。
写操作:
-
发布
(insert)
帖子
-
修改
(update)
帖子
-
删除
(delete)
帖子
读操作:
-
通过
tid
查询
(select)
帖子实体,
单行查询
-
通过
uid
查询
(select)
用户发布过的帖子,
列表查询
-
帖子
检索
(search),例如通过时间、标题、内容搜索符合条件的帖子
在数据量较大,并发量较大的时候,通常通过
元数据与索引数据分离
的
架构
来满足不同类型的需求:
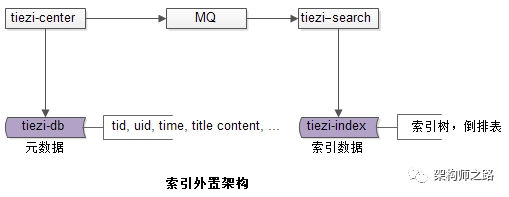
架构中的几个关键点:
其中,
tiezi-center
和
tiezi-search
分别满足两类不同的
读需求
:
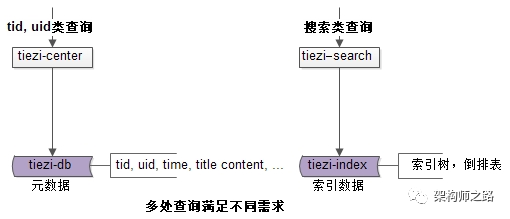
如上图所示:
对于
写需求
:
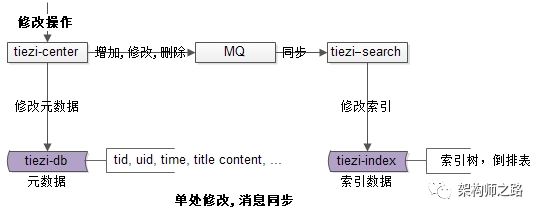
如上图所示:
tiezi-search
,搜索架构
不是本文的重点(外置索引架构设计,请参见
《
100亿数据1万属性数据架构设计
》
),后文将重点描述帖子中心元数据这一块的水平切分设计。
三、帖子中心元数据设计
通过帖子中心业务分析,很容易了解到,其核心元数据为:
Tiezi(tid, uid, time, title, content, …);
其中:
数据库设计上,在业务初期,
单库
就能满足元数据存储要求,其典型的架构设计为:
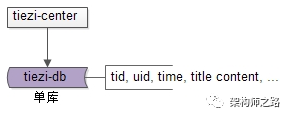
在相关字段上建立索引,就能满足相关业务需求:
select * from t_tiezi where tid=$tid
select * from t_tiezi where uid=$uid
四、帖子中心水平切分
-tid
切分法
当数据量越来越大时,需要对帖子数据的存储进行线性扩展。
既然是帖子中心,并且帖子记录查询量占了总请求的
90%
,很容易想到
通过
tid
字段取模来进行水平切分
:
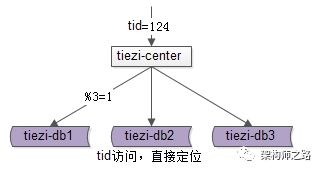
这个方法简单直接,
优点
:
-
100%
写请求可以直接定位到库
-
90%
的读请求可以直接定位到库
缺点
:
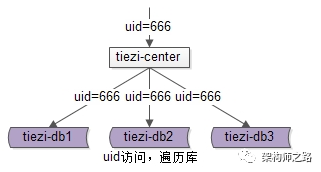
如上图,一个
uid
访问需要遍历所有库。
五、帖子中心水平切分
-uid
切分法
有没有一种切分方法,
确保同一个用户发布的所有帖子都落在同一个库上
,而在查询一个用户发布的所有帖子时,不需要去遍历所有的库呢?
答
:使用
uid
来分库
可以解决这个问题。
新出现的问题:如果使用
uid
来分库,确保了一个用户的帖子数据落在同一个库上,那
通过
tid
来查询,就不知道这个帖子落在哪个库上
了,岂不是还需要遍历全库,需要怎么优化呢?
答
:
tid
的查询是单行记录查询
,只要
在数据库(或者缓存)记录
tid
到
uid
的映射关系
,就能解决这个问题。
新增一个索引库:
t_mapping(tid, uid);
使用
uid
分库,并增加索引库记录
tid
到
uid
的映射关系之后,每当有
uid
上的查询:
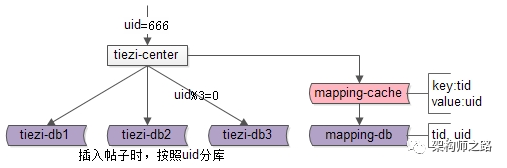
可以通过
uid
直接定位到库。
每当有
tid
上的查询:
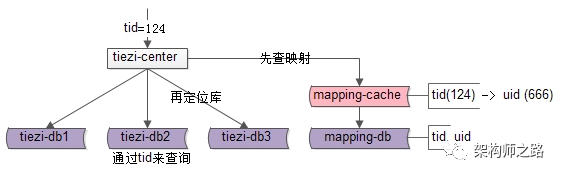
-
先查询索引表,通过
tid
查询到对应的
uid
-
再通过
uid
定位到库
这个方法的
优点
:
缺点
:
六、帖子中心水平切分
-
基因法
有没有一种方法,
既能够通过
uid
定位到库,又不需要建立索引表来进行二次查询
呢,这就是本文要叙述的“
1
对多”业务分库
最佳实践
,
基因法
。
什么是分库基因?
通过
uid
分库,假设分为
16
个库,采用
uid%16
的方式来进行数据库路由,这里的
uid%16
,其本质是
uid
的最后
4
个
bit
决定这行数据落在哪个库上,
这
4
个
bit
,就是分库基因
。
什么是基因法分库?
在“
1
对多”的业务场景,使用“
1
”分库,在“多”的数据
id
生成时,
id
末端加入分库基因,就能同时满足“
1
”和“多”的分库查询需求。
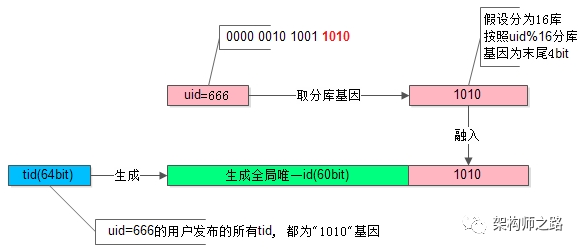
如上图所示,
uid=666
的用户发布了一条帖子(666的二进制表示为:101001
1010
):
-
使用
uid%16
分库,决定这行数据要插入到哪个库中
-
分库基因是
uid
的最后
4
个
bit
,即
1010
-
在生成
tid
时,先使用一种分布式
ID
生成算法生成前
60bit
(上图中绿色部分)
-
将分库基因加入到
tid
的最后
4
个
bit
(上图中粉色部分)
-
拼装成最终的







