上篇
《样本训练》
介绍了很多常用的分类算法,实操我们中该如何评价不同分类器的质量呢?首先要定义,分类器的准确率,指分类器正确分类的项目占所有被分类项目的比率。通常使用回归测试来评估分类器的准确率,最简单的方法是用构造完成的分类器对训练数据进行分类,然后根据结果给出准确率评估。但这不是一个好方法,因为使用训练数据作为检测数据有可能因为过分拟合而导致结果过于乐观,所以一种更好的方法是在构造初期将训练数据一分为二,用一部分构造分类器,然后用另一部分检测分类器的准确率。所以一般会对原始数据进行分割,分割成训练集和测试集。这样做是为了方便验证在训练集上训练得到的模型,是否能在测试集中可取得理想的效果。通常(训练集:测试集)分割比例为
6:4
或者
7:3
。训练集用来训练算法,学习其中的变量,测试集用来查看或检验所选算法在测试集上的效果。目前,常见的开源算法类库现成的有很多,只要将这些类库装载到计算环境中使用即可。(数据科学(
data science
)领域较流行的运行机器学习算法的语言有
R
、
Python
。)
衡量算法效果。常见的评价指标有:正确率、召回率和
F
值:
-
正确率
=
正确识别的个体总数
/
识别出的个体总数
-
召回率
=
正确识别的个体总数
/
测试集中存在的个体总数
-
F
值
=
正确率
*
召回率
* 2 / (
正确率
+
召回率
)
举个例子:某池塘有
1400
条鱼,
300
只虾,
300
只蟹。现在以捕鱼为目的。撒一大网,网着了
700
条鱼,
200
只虾,
100
只蟹。那么,这些指标分别如下:
正确率
= 700 /(700 + 200 + 100) = 70%
召回率
= 700 /1400 = 50%
F
值
= 70% * 50% * 2 / (70% + 50%) = 58.3%
若把池子里的所有的鱼、虾和蟹都一网打尽,这些指标变为:
正确率
= 1400 /(1400 + 300 + 300) = 70%
召回率
= 1400 /1400 = 100%
F
值
= 70% * 100% * 2 / (70% + 100%) = 82.35%
由此可见,正确率是评估算法预测的成果中,目标样本所占的比例;召回率,主要是从关注领域中,召回目标类别的比例;而
F
值,则是综合这二者指标的评估指标,用于综合反映整体的指标。
对于二分分类,原始类分为
positive
、
negative
,我们可以标记为
p
、
n
。如图
9-9
所示,排列组合后得到
4
种结果。于是我们可以得到四个指标,分别为真正(
TP
)、伪正(
FP
);伪负(
FN
)、真负(
TN
)。
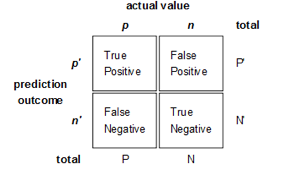
图
9‑9
二分分类典型四象限示意
对于正、负分类问题,一些分类器得到的结果往往不是
0,1
这样的标签,如神经网络,得到诸如
0.5
、
0.8
这样的分类结果。这时,我们可以人为取一个阈值,比如
0.4
,那么小于
0.4
的为负类,大于等于
0.4
的为正类,这样可以得到一个分类结果。同样这个阈值我们可以取
0.1
、
0.2
等等。取不同的阈值,得到的最后分类情况也就不同。例如图
9-10
所示
:
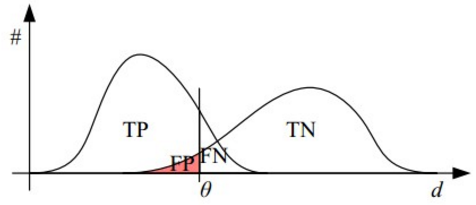
图
9‑10
正负样本图示例
图
9-10
中左部的曲线图表示样本为正类的分布图,右部的曲线表示样本为负类的分布图。那么我们从中取一条直线,若假设直线左边分为正类,右边分为负,这条直线也就是我们所取的阈值。可见若我们移动该直线,这样阈值的不同,可以得到不同的结果。但是由分类器推测出的样本分布图始终是不变的。这时候就需要一个独立于阈值,只与分类器有关的评价指标,来衡量特定分类器的好坏。还有在类不平衡的情况下,如正样本
90
个,负样本
10
个,直接把所有样本分类为正样本,得到识别率为
90%
。但这显然没有意义。这就是
ROC
曲线的主要动机。
ROC
空间将伪正率(
FPR
)定义为
X
轴,真正率(
TPR
)定义为
Y
轴。这两个值由上面四个值计算得到,公式如下
:
TPR
:在所有实际为正的样本中,被正确地判断为正的比率。
TPR=TP/(TP+FN)
FPR
:在所有实际为负的样本中,被错误地判断为正之比率。
FPR=FP/(FP+TN)
在实际应用中,我们当然希望尽量把正确的目标人群找出来作为主要任务,也就是第一个指标
TPR
越高越好。而把负的样本为误判,也就是第二个指标
FPR
要越低越好。不难发现,这两个指标之间是相互制约的。若我们对于负样本判别标准定义的特别细致严格,一点小的特征都判断为负的话,那么第一个指标就会很高,但是第二个指标也会相应地变高。最极端的情况下,若我们把所有的样本都看做负的话,那么第一个指标达到
1
,第二个指标也为
1
。
我们以
FPR
为横轴,
TPR
为纵轴,得到
ROC
空间:
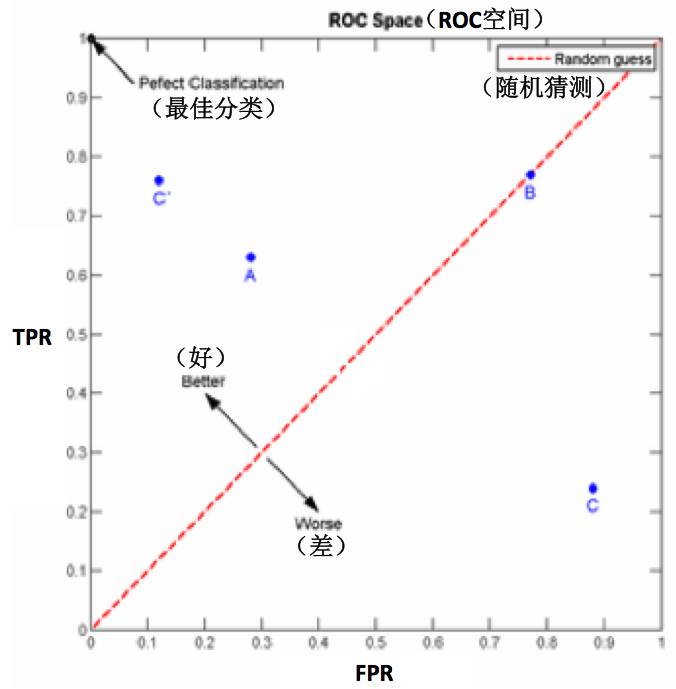
图
9‑11 ROC
空间示例图
我们可以看出,左上角的点
(TPR=1,FPR=0)
,为完美分类,也就是个高明全对的推断。左边离中线近一些的点
A(TPR>FPR)
,
A
的判断大体是正确的。中线上的点
B(TPR=FPR)
,也就是
B
可能全都是蒙的,对一半错一半;右下半的点
C(TPR
,这个推断很可能错误。上图中一个阈值,得到一个点。现在我们需要一个独立于阈值的评价指标,来衡量这个分类器如何,也就是遍历所有的阈值,得到
ROC
曲线。
还是以图
9-10
为例,我们可以遍历其中所有的阈值,能够在
ROC
平面上得到
ROC
曲线。如图
9-12
所示
ROC
曲线。
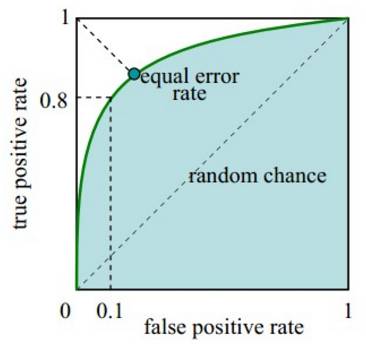
图
9‑12 ROC
曲线示例图
曲线距离左上角越近,证明分类器效果越好。
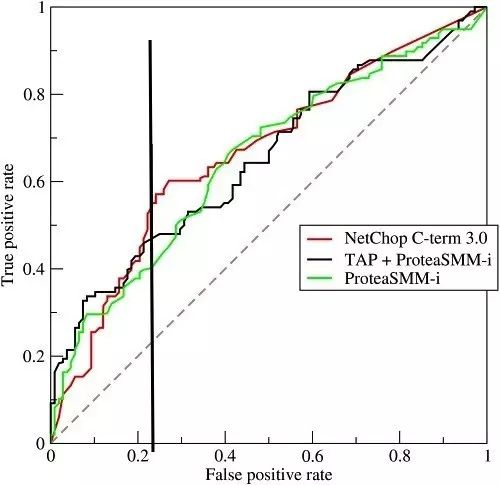
图
9‑13
三种分类器得出的不同
ROC
曲线示例图
如图
9-13
所示的示例,是三条
ROC
曲线,若在
0.23
处取一条直线。那么,在同样的低
FPR=0.23
的情况下,最外侧那条线的分类器得到更高的
TPR
。也就表明,
ROC
越往上,分类器效果越好。我们用一个标量值
AUC
来量化她。
如图
9-14
所示,
AUC
值为
ROC
曲线所覆盖的区域面积,显然,
AUC
越大,分类器分类效果越好。
AUC = 1
,是完美分类器,采用这个预测模型时,不管设定什么阈值都能得出完美预测。绝大多数预测的场合,不存在完美分类器。
0.5 < AUC< 1
,优于随机猜测。这个分类器(模型)若妥善设定阈值的话,能有预测价值。
AUC = 0.5
,跟随机猜测一样(例:抛硬币),模型没有预测价值。
AUC < 0.5
,比随机猜测还差;但只要总是反预测而行,就优于随机猜测。
图
9‑14 AUC
示例图
假设分类器的输出是样本属于正类的
score
(置信度),则
AUC
的物理意义为,任取一对(正、负)样本,正样本的
score
大于负样本的
score
的概率。
第一种方法:
AUC
为
ROC
曲线下的面积,那我们可直接计算面积。面积为一个个小的梯形面积之和。计算的精度与阈值的精度有关。
第二种方法:根据
AUC
的物理意义,可计算正样本
score
大于负样本的
score
的概率。取
N*M(N
为正样本数,
M
为负样本数
)
个二元组
,
比较
score
,最后得到
AUC
。时间复杂度为
O(N*M)
。
第三种方法:实际上和第二种方法是一样的,但可减小复杂度。直接计算正样本
score
大于负样本的概率。我们首先把所有样本按照
score
排序
,
依次用
rank
表示他们
,
如最大
score
的样本
rank=n(n=N+M)
,其次为
n-1
。那么对于正样本中
rank
最大的样本
rank_max,
有
M-1
个其他正样本比他
score
小
,
那么就有
(rank_max-1)-(M-1)
个负样本比他
score
小。其次为
(rank_second-1)-(M-2)
。最后我们得到
AUC
。时间复杂度为
O(N*M)
。即:
AUC=((
所有的正例
rank
相加
)-(M*(M+1))/2)/(M*N)
。详细计算公式见公式
9-3
。
公式
9‑3 AUC
公式
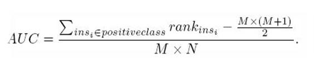
另外,特别需要注意的是,对于存在
score
相等的情况时,对相等
score
的样本,需要赋予相同的
rank
(无论该相等的
score
是出现在同类样本还是不同类的样本之间的,都需要这样处理)。具体操作就是再把所有这些
score
相等的样本的
rank
取平均。然后再使用上述公式。
当然实操中往往数据中不可避免的存在一些噪音,所以常会采用一些人工干预设置补偿因子及系数的方式。一方面这样做可以一定程度简化算法及模型,另一方面也大大降低对计算资源的消耗,从而降低成本提升效率。(这也是典型的二八原则做法:大部分
80%
的问题仅需要
20%
的投入及特征模型即可解决。)
(转载请注明出处:微信订阅号:ad_automation)
文字表现力有限,欢迎参加
《5.28线下大课堂》
面对面为您答疑解惑讲透您关心的问题。
相关推荐阅读:
《2016合集目录【程序化广告实战】》

长按二维码加入私密圈子
同时备有微信互动群,需在加群前先加微信
13121124046
(伍刀刀),拉您入群。
5月28日15点机械工业出版社3号楼10层会议室
流水课通知
“大数据基础(下)”
以下为5月份的活动安排,我们不见不散:
活动时间:
2017年5月28日 周六下午 15:00——17:00
活动详细安排:
14:50-15:00 签到与自我介绍
15:00-16:30 吴俊老师分享
16:30-17:00 全体同学自由social时间
在讲解过程中,如果你有任何问题,可随时提问。
活动地点
:北京 西城区 百万庄大街22号机械工业出版社3号楼10层会议室
乘车路线
:地铁6号线 车公庄西站 D西南口出。
报名方式:
第一步:添加微信号:13121124046(伍刀刀);
第二步:填写报名表,并缴纳200元报名费(单次体验票¥200,欢迎大家选购超实惠的¥1920年包套餐、或¥4188VIP年包套餐);
第三步:活动当天来到活动现场签到参与。
另外,为了满足无法亲临现场同学的需求,此次活动我们增加了线上同步直播及视频回看。
如何参加线上直播及视频回看?
第一步:添加微信号:13121124046(伍刀刀);
第二步:填写报名表,并缴纳200元报名费;(单次体验票¥200,欢迎大家选购超实惠的¥1920年包套餐、或¥4188VIP年包套餐);
移动端、PC直播地址(可点击文末“阅读原文”进入):
http://mudu.tv/watch/772943
第三步:我们会将以您手机号作为唯一识别码加入直播间,给您可以在线直播互动及视频回看的课程地址参与活动。
直播将以视频形式进行,而且能够进行互动,我们将回答您在直播间提出的每个有价值的问题。而且若您时间上冲突,依然可以等有空的时候回看即可。
如您在报名中遇到任何问题,请拨打电话或添加微信:13121124046(伍刀刀)随时联系我们。
吴俊老师简介:

吴俊老师是中国广告PDB(Programmatic Direct Buy 私有程序化购买)第一人。现任掌慧纵盈高级产品总监,专注于线下数据线上打通营销解决方案,推动数字营销新升级。
更多朋友们对于吴俊老师的了解来自于他此前在品友的工作经历。吴俊老师是原品友负责PDB/移动/流量的产品总监,拥有16年以上IT/互联网行业从业经验和超过5年的程序化广告工作经验。他在2014年负责推动了中国首个PDB广告投放项目(2014中国国际广告节长城奖金奖上海通用汽车私有程序化广告投放案例),通过PDB帮助广告主管理了数亿广告预算投放,在广告主包段的门户及垂直媒体PC和移动端黄金广告位以及视频媒体贴片黄金资源,实现了广告投放的跨媒体联合频控、千人千面;最终有效提升了广告主广告预算的ROI:CPUV降低至少30%以上(即相同的预算覆盖更多的受众);平均CPL降低20%以上(降低销售线索的获得成本,同时广告主反馈后续CPQL验证及后续转化效果也比较好)。
2014年底2015年初在市场反馈十分巨大的视频广告PDB领域持续发力,推动行业内视频广告PDB业务大规模迅速发展,目前市场上已有上海通用汽车、玛氏、欧莱雅、人头马、Burberry、高露洁、黑人、雅士利等等等等不同行业,近百广告主近千视频OTV项目通过PDB方式进行了投放。无论是对效果营销客户还是品牌营销客户,吴老师都有极为广博的经验。
以下为本两次活动——《
大数据
基础》讲解提纲:
——160页ppt
授课时间:分为2次课,分别放在4月份1次课、5月份一次课。
主要内容:
DMP价值意义
什么是DMP
Data类型
DataManagement 流程
DMP的系统构成
数据互通的核心 –ID mapping
------------以上为415课程已讲内容
-----------如下为528的课程内容:
移动设备ID专题
Cookie原理
什么是cookie
种cookie的流程
种cookie的指令
跨域名cookie不可被获取
CookieMapping的重要性
Cookiemapping率的重要性 –mapping率越高数据利用率越高
cookiemapping原理
单向cookie mapping
双向cookie mapping
cookie mapping发起方及时机点
DMP对程序化广告的指导
线下DMP
线下数据采集
消费者洞察
渠道效率分析
数字营销指导
Datahub
data交易市场
市面上常见的第三方数据供应商,及其特点
DMP系统案例分享
Trading Desk & DMP & PDB(PMP)案例:某知名乳品大数据驱动数字营销管理系统
线下DMP系统案例分享
某大型国际知名车企全国4S线下到店大数据管理系统
专有线下DMP+DSP案例
往期同学的一些反馈:


往期活动现场:








每次活动后都有例行的聚餐:



以往期经验来看,此次活动肯定会爆满,大家想报的话加紧,别活动前几天才想起报名,名额已经没有了!
锋暴研习社:由国内知名营销人士吴俊、宋星等人发起,致力于打造一个营销界内的学习社群,开设极具价值的营销系统课程,持续不断的输出原创营销干货,定期举办线下讲座、沙龙活动,使圈内的每个营销人得到快速成长与提升。
关于课程受众等详细信息请点击查看:
《2017程序化广告实战流水课》适合谁参加?





