 「论文访谈间」是由 PaperWeekly 和中国中文信息学会青工委联合发起的论文报道栏目,旨在让国内优质论文得到更多关注和认可。
「论文访谈间」是由 PaperWeekly 和中国中文信息学会青工委联合发起的论文报道栏目,旨在让国内优质论文得到更多关注和认可。
论文作者 |
张檬,刘洋,栾焕博,孙茂松
(清华大学)
特约记者 | 赵艳(北京语言大学)
利用非平行双语语料构建双语词典是一项长期存在的跨语言任务。其实现过程一般需要跨语言信息(如种子双语词典)作为监督信号来建立双语词汇之间的翻译关系,但对于完全缺乏双语资源的小语种和专门领域来说,获取其跨语言信息十分困难,那么如何在不使用任何跨语言监督信号的情况下通过无监督方法构建双语词典呢?来自清华大学的张檬博士、刘洋老师、栾焕博老师和孙茂松老师发表在 ACL2017 上的论文“Adversarial Training for Unsupervised Bilingual Lexicon Induction”利用生成对抗网络(GAN)实现了双语词典构建任务,并取得了良好效果。
众所周知,词是构成语言的基本单元,词表示方法的改进对很多自然语言处理任务产生了显著影响,词向量(word embedding)因其能够获取语言中的规律而被广泛使用。前人的工作发现利用两种语言的单语语料训练的词向量空间存在近似同态性(如图 1 所示),因而可以使用一个线性映射把这两个向量空间联系起来。那么如何得到这个线性映射呢?在前人的工作中,往往需要使用大量种子翻译词对作为监督信号来学习这个线性映射,而这篇论文则是要针对完全不使用任何双语监督信号的场景,作者需要设计方法来对联系两个向量空间的线性映射进行有效学习,这是本文工作中最大的研究挑战。
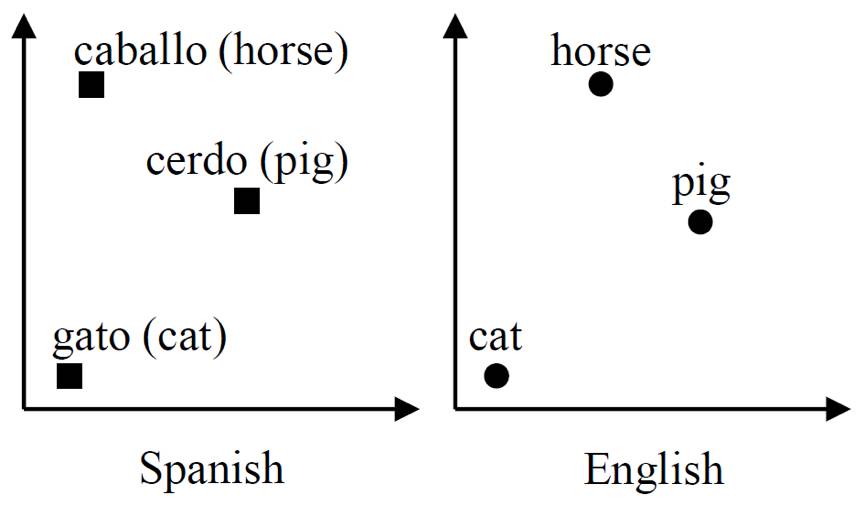 ▲
图 1:
西班牙语和英语
的词向量空间表现出的近似同态性
▲
图 1:
西班牙语和英语
的词向量空间表现出的近似同态性
这篇论文中的方法灵感来自于当前机器学习领域大热的生成对抗网络(GAN),作者针对本文任务设计了生成器 G 和鉴别器 D 之间的对抗游戏,其基本形式如图 2(a) 所示(unidirectional transformation model)。图中,方块代表源语言词向量,圆点代表目标语言词向量。源语言词向量通过 G 映射到目标语言的词向量空间后,如果鉴别器 D 无法分辨出映射过来的词向量与原本属于目标语言的词向量,则说明映射 G 成功把两种语言的词向量空间联系起来了,如果 D 能够分辨,则 D 可以指导 G 如何改善。G 和 D 这种互相竞争、共同进步的关系使得本文的方法不依赖种子双语词典。

▲
图 2:
对抗学习模型架构:(a) 为基本模型(unidirectional transformation model),(b) 为bidirectional transformation model,(c) 为adversarial autoencoder mode
在介绍扩展模型之前,需要明确生成器 G 的构成。这篇论文中的生成器是一个矩阵,而将其约束为正交矩阵有助于训练成功。为了更大程度地节省训练时间,降低训练难度,作者设计了图 2(b)(bidirectional transformation model)和图 2(c)(adversarial autoencoder model)所示的两种扩展模型,这两种模型放宽了正交约束。在如图 2(b) 所示的双向转换模型(bidirectional transformation model)中,生成器 G 将源语言词向量映射到目标语言的词向量空间中,G 的转置也能够将目标语言词向量映射回源语言的词向量空间中去。在如图 2(c) 所示的对抗自编码模型(adversarial autoencoder model)中,生成器 G 将源语言词向量映射到目标语言的词向量空间中输出后,利用 G 的转置将映射回去以重构源语言词向量。将源语言词向量与重构的词向量进行相似度计算(cosine 夹角)加入到生成器的损失函数中。
在实验设计上,作者分别与基于解密的 MonoGiza 系统和基于种子翻译词对的Translation matrix (TM) 和 Isometric alignment (IA) 方法进行了比较,在实验过程中需要保证的是,这些方法输入的词向量与本文中模型的输入一致,均为利用 word2vec 的 CBOW 模型训练得到的词向量。结果发现,MonoGiza 系统的准确率很低,对抗自编码模型(adversarial autoencoder model)则能达到较高的准确率,而基于种子翻译词对的 TM 和 IA 方法若想达到与该模型相同的准确率,需要大量的种子翻译词对。除此之外,作者还探究了词向量维度对实验结果的影响以及大规模数据下模型的表现情况。
对话作者
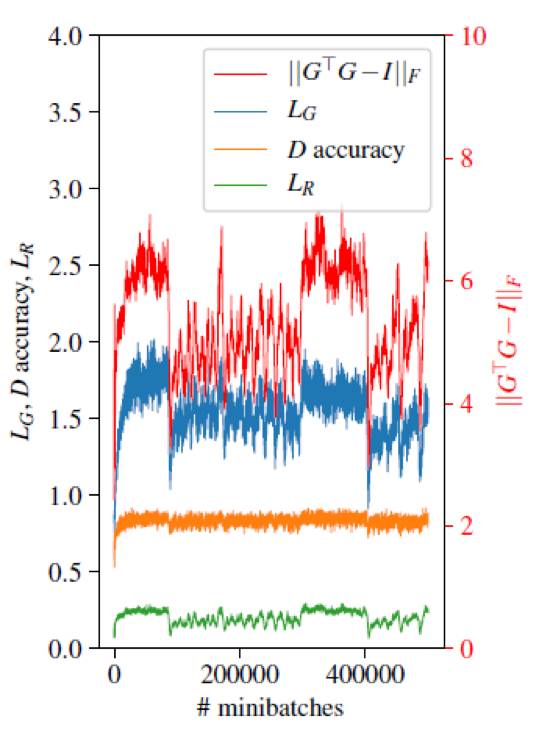
关于这篇论文的创新点,作者提到除了上述两个扩展模型的设计之外,另一个创新点是尝试探索了多种训练技术。首先是对鉴别器 D 进行正则化。鉴别器 D 采用标准前馈神经网络,作者尝试了为其输入加入不同类型的噪声,如 dropout、Additive Gaussian noise、Multiplicative Gaussian noise,最后发现最有效的方式是 Multiplicative Gaussian noise。另外,作者发现,在训练结束时保存的模型并不能达到良好的效果,所以为了选择效果最好的模型,作者观察了训练轨迹(如图 3 所示),发现生成器的损失呈现剧烈下降的位置对应的分类正确率下降,这说明该位置通常对应着效果好的模型。有趣的是,重构源语言词向量的损失和的值也呈现同步下降现象。作者表示在实验过程中最大的问题是训练不稳定,为解决这个问题,作者在模型设计和训练技术上进行了多种探索和尝试,并在训练过程中多输出信息以便观察,对一些特别的现象进行分析,这也是作者分享的心得体会。
▲
图 3:对抗自编码模型的典型训练轨迹
关于模型的应用场景与意义,作者提到,双语词典本身有很多应用场景,一方面它可以直接供人参考,另一方面它是计算机许多跨语言处理任务的重要资源,如机器翻译、跨语言检索、跨语言模型迁移等。而本方法的无监督性质为完全缺乏双语资源的小语种和专门领域开辟了与其他语言连接的可能。此外,只使用单语语料就能构建双语词典意味着语言在词汇层面的某种同态性,佐证了人类语言在概念表示上可能存在的一致性。
欢迎点击
「阅读原文」
查看论文:
Adversarial Training for Unsupervised Bilingual Lexicon Induction
关于中国中文信息学会青工委
中国中文信息学会青年工作委员会是中国中文信息学会的下属学术组织,专门面向全国中文信息处理领域的青年学者和学生开展工作。

关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击
「交流群」
,小助手将把你带入 PaperWeekly 的交流群里。







