本文来自作者
秦子敬
在
GitChat
上分享 「Neo4j 图数据库在社交网络等领域的应用」,
「
阅读原文
」
查看交流实录。
「
文末高能
」
编辑 | 哈比
一、前言
Neo4j 是一种基于图论实现的新型 NoSQL 数据库。这种数据库,在处理社交网络,物流运输,推荐系统,欺诈检测等,关系分析等领域有着巨大优势。本场 Chat,我将为你介绍:
-
Neo4j 与关系型、其他非关系型数据库的优势比较
-
哪些领域适合 Neo4j,哪些领域不适合
-
Neo4j 的安装
-
介绍 Cypher 查询语言
-
案例实战:
-
银行欺诈环分析
-
文献索引
-
寻找垃圾邮箱源头
-
企业关系构建
-
社交关系分析,实现一个简单的好友推荐功能
二、正文
我想,大家对 Mysql 这种关系型(SQL 型)的数据库肯定很熟悉。对 MongoDb 这种非关系型(NoSQL 型)数据库也不会陌生。今天我们要介绍一种新型数据库—图数据库。这种数据库是基于图论实现的。
一提到图论,可能有的小伙伴就会倒吸一口冷气,如果你曾涉及过一些数据结构的知识,会发现图几乎是最难学的,涉及到许多晦涩难懂的算法。这里不用担心,今天介绍的 Neo4j 把很多算法已经封装好了。不需要你涉及底层,很方便。
下面我们开始对比一下图数据库和其他关系型、非关系型的数据库的优劣。
与传统数据库不同的是,图数据库存的是节点(对象)和边(对象与对象之间的关系)。当数据存在错综复杂的关系时,使用这类数据库是最好的选择。
1. Neo4j 与关系型、其他非关系型数据库的优势比较
(1)Neo4j 与关系型数据库的比较
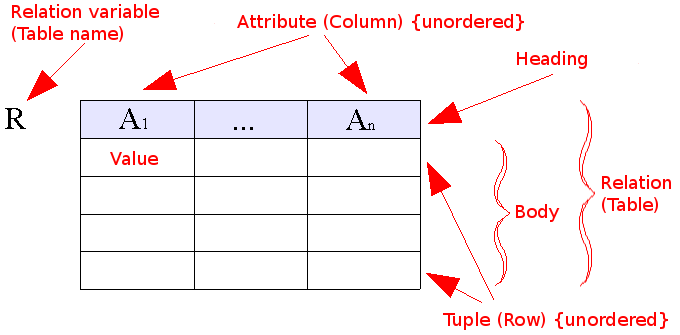
以 Mysql 为代表的关系型数据库已经诞生了很久了,一直是数据库领域的动力,他们将高度结构化的数据储存在一张张二维表格里,必须严格地按照相关约定对数据进行操作(比如外键约束)。你可以把它理解成一张张账本。
但是,正是因为关系型数据库在建表之前就需要制定相关约定,常常会出现表与表之间有相互制约、相互引用的关系。随着数据库的不断增大,相互制约的关系会不断增多,执行搜索匹配的操作次数将呈现指数增加,进而消耗大量的资源。
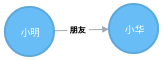
举一个例子,当你要查询 “小明的朋友” 这样的问题,关系层数据库会涉及到一些代价高昂的间接层,比如用索引表查询:
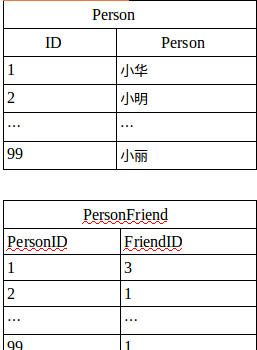
从表里可以发现,小明(ID:2)的朋友是小华(ID:1),你也许会说这并不复杂呀,才一张表而已。
但是要是我问 “小明的朋友的朋友的朋友…” 这样的深度不断增加,每增加一层就要加一张索引表,这样间接层不断增加。查询就越来越慢,而且所需的内存开销就越来越大。
还有一点,如果我反向问,“谁的朋友是小明”,你可能会说,当然是小华呀。但是你仔细看看索引表,可小华的 FriendID 是 3 不是 1(小明)。也就是说,对于这种反向提问,关系型数据库也不能很好处理。
这种反向提问有意义吗?当然有意义,而且很有用,打个比方,小明喜欢编程,那么反向问,谁还喜欢编程。找到喜欢编程里的大神(通过紧密度中心性等属性评判)推荐给小明关注。这样一个简单的推荐功能就出来了。
对比起来,图数据库就有着得天独厚的优势,它储存节点,节点的属性,节点的关系。而这些关系是按类型和方向组织起来的。关系的访问是直接通过节点完成的。问 “小明的朋友的朋友的朋友…”,即使深度增加也只是增加节点而已。在复杂连接的查询上,能达到毫秒级别。
怎么理解节点,关系,属性这些概念呢?
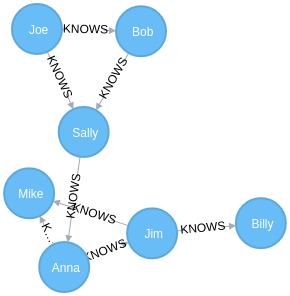
这里举个例子,创建一个节点,标签是人,他的名字叫小明。小明就是一个节点。小明喜欢看电影(节点的属性),他和小华是朋友(关系)。这样一个简单的关系就建立了。
(2)Neo4j 与其他非关系型数据库比较
目前,大部分的 NoSQL 数据库都是基于集合和文档的,这些数据被储存在不连贯的集合里,那么这样使得数据间的相互联系,建立关系变得更加困难。也就是说数据是离散的,如果要建立关系,通常会将一个集合嵌到另一个集合里,再来实现关系。
这样的开销也很大。但是,这种数据没有太多 “ 关系 “,使用这种数据库效率特别高,有很好的读写功能。

这篇文章对比了 8 种不同的 NoSQL 数据库可以参考(http://blog.jobbole.com/1344/)
2. 哪些场所适合 Neo4j, 哪些场所不适合?
在这里,需要说明一下,图数据库不只有 Neo4j,但是 Neo4j 是一个非常优秀的图数据库,03 年就开始研发了,07 年发布。被许多公司使用,ebay, 阿迪达斯,沃尔玛等等。
Neo4j 是基于图论实现的,自然在处理地图方面有天然优势,所以,他适用于物流管理,交通大数据。
由于 Neo4j 的基本元素是节点和关系,它也特别适合处理有复杂关系的社交网络。另外在实现推荐系统上也很有优势,对于分析交易客户数据也很有帮助。它还能用于检测欺诈行为。下文会用一个例子说明。甚至在游戏方面也有运用。比如光荣公司的《三国志 13》。

稍微总结适合的领域:
-
社交网络
-
交通大数据(物流)
-
推荐系统
-
欺诈分析
-
Web 安全(垃圾邮件等等)
但是,也有不适合图数据库的领域。
-
记录大量基于事件的数据
-
需要大规模分布式数据处理
-
二进制数据存储
-
适合保存在关系型数据的结构化数据
3. Neo4j 安装
Windows 有 exe 安装文件,比较方便,一步一步按照可视化教程就行。Mac 安装应该也不难。这里也不做介绍了。这里为基于 Linux Ubuntu16.04,介绍安装教程。
(1)安装 JAVA 环境
Neo4j 是用 Java 实现的,所以你需要安装 Java Runtime Environment(JRE)。如果您已经启动并运行,请继续并跳过此步骤。打开指令框:
sudo apt update
sudp apt upgrade
sudo apt install default-jre default-jre-headless
如果指令不管用,先试试这两句,再使用。
sudo update-alternatives —set java / usr / lib / jvm / java-8-openjdk-amd64 / bin / java
sudo update-alternatives —set javac / usr / lib / jvm / java-8 -openjdk-amd64 / bin / javac
看一下 java 版本:

(2)安装 Neo4j
首先,我们将存储库密钥添加到我们的钥匙串。
wget --no-check-certificate -O -https://debian.neo4j.org/neotechnology.gpg.key| sudo apt-key add -
然后将存储库添加到 apt 源列表中。
echo 'deb http://debian.neo4j.org/repo stable/' | sudo tee /etc/apt/sources.list.d/neo4j.list
更新一下:
sudo apt update
sudo apt install neo4j
服务器应该已经自动启动,也应该在启动时重新启动。如有必要,服务器可以停止:
sudo service neo4j stop
并重新启动:
sudo service neo4j start
访问 Neo4j
现在应该可以通过 http:// localhost:7474 / browser / 访问数据库。
下面介绍一下打开后的面板。一开始有一个登录界面,让你输入帐号密码,第一次打开默认都是 neo4j, 进去后会自动弹出来让你改密码。登录后是这个样子的。
这里有一些示例代码:
你可以先尝试一下 Example Graphs 的教程 输入查询语句后得到这样的界面:
table 是这样的,可以看到节点的属性:name、born 等等。
Text 可以看到表格的数据:
Code 可以看到输入的 code 和 json 格式的数据:
4. 介绍 Cypher 查询语言
正如 Mysql 有 SQL 语言一样,Neo4j 也有对应的查询语言 Cypher。Cypher 借鉴了 SQL 语言的结构,会有许多熟悉的关键字。对于数据库操作无非是增删改查,下面一一介绍:
(1)增
所谓增,就是创建数据。在图形数据库里基本元素是节点,关系,属性。Neo4j 有两个关键字实现增加。一个是 CREATE(小写也可以):
<1> CREATE 创建节点
create (n:User {name:"Dav"})
这里 n 是变量名,User 是标签(在图数据库里,标签可以理解为关系型数据库里的表 table),花括号里面的是属性。
<2> CREATE 创建关系:
MATCH (n{name:"a"}),(m{name:"b"}) CREATE (n)-[r:KNOWS]->(m) return n,m
这里做几点说明:
另一个是用 MERGE 创建节点 MERGE 和 CREATE 不同之处在于 MERGE 等于 MATCH + CREATE 会先创建前会在数据库里检查有没有这个节点。
<3>MERGR 创建节点
MERGE (n:Test{name:"c"}) ON CREATE SET n.created = timestamp() return n
首先检查 Test 标签,属性为 name 的值的节点 c 是否存在,存在使用已有节点,否则创建一个新的节点。
这里就用到了 MERGE 创建节点,还用了一个 SET 关键字,这个是改变节点的属性,属于 “改” 的范围
<4>MERGR 创建关系
用合并的方式创建关系,先检测关系存不存在,若存在则不修改任何数据,否则创造新的关系
MATCH (a:Person{name:'Joel Silver'}),(b:Person{name:'J.T. Walsh'}) MERGE (a)-[r:LOVES]->(b)
匹配出名字叫 Joel Silver 的人和名字叫 J.T. Walsh 的人建立关系 LOVES。出现这个话,代表已经建立成功了。
Created 1 relationship, completed after 199 ms.
(2) 删
<1> DELETE 关键字可以删除数据:
MATCH (n)DELETE n
这个会报错,因为必须删除关系才能删除节点:
MATCH ()-[r:朋友]->(m) DELETE r,m
要这么操作,查找出朋友关系 r 以及朋友所指向的节点 m,并同时把 r 和 m 删除。出现这个就成功了:
Deleted 1 node, deleted 1 relationship, completed after 8 ms.
<2> REMOVE 也可以删除数据:
MATCH (n) REMOVE n:Test
用 REMOVE 来移除数据,移除带有 Test 标签的所有结点:
Removed 3 labels, completed after 9 ms.
用 REMOVE 来移除节点时要小心,REMOVE 不会像 DELETE,因为这个节点有其他关系而报错不删。
那么这个节点被删除后,关系会指向空节点。
(3)改
使用 SET 去更改节点。刚刚前文已经有例子就不赘述了。
(4)查
使用 MATCH 去查询节点。Cypher 还有其他的缩小查找范围的办法。
<1>
MATCH p=()-[r:LOVES]->() RETURN p LIMIT 25
用 LIMIT 关键字只拿指定数目的节点个数。
<2> WHERE 实现条件过滤
MATCH p=(n:Person)-[:LOVES]->() WHERE n.name <> "a" RETURN p
查询节点 n 的属性 name 不等于 a 的所有节点 <> 表示不等于。
<3> 使用 INDEX 索引
使用关键字 INDEX ON 为节点的属性 name 创建一个普通的索引:
CREATE INDEX ON :Person(name)
输出:
Added 1 index, completed after 46 ms.
使用索引来查询:
MATCH (n:Person) WHERE n.name IN ["a","b"] RETURN n as Person
得到图:

显式使用索引查询:
MATCH(n:Person)
USING INDEX n:Person(name)
WHERE n.name = ‘a’
RETURN n as Person
用 DROP 关键字删除一个已经存在的索引:
DROP INDEX ON :Person(name)
输出:
Removed 1 index, completed after 1 ms.
Cypher 还能使用一些函数来辅助查询 比如 size()、any()等等。具体其他的可以查阅相关的 API 文档。这里只提两个重要的,查询最短路径和所有最短路径。
<1> 最短路径 shortestpath()
以这个图为例子,从部分的图里找出 Joel Silver 到 Jonathan Lipnicki 的最短路径:
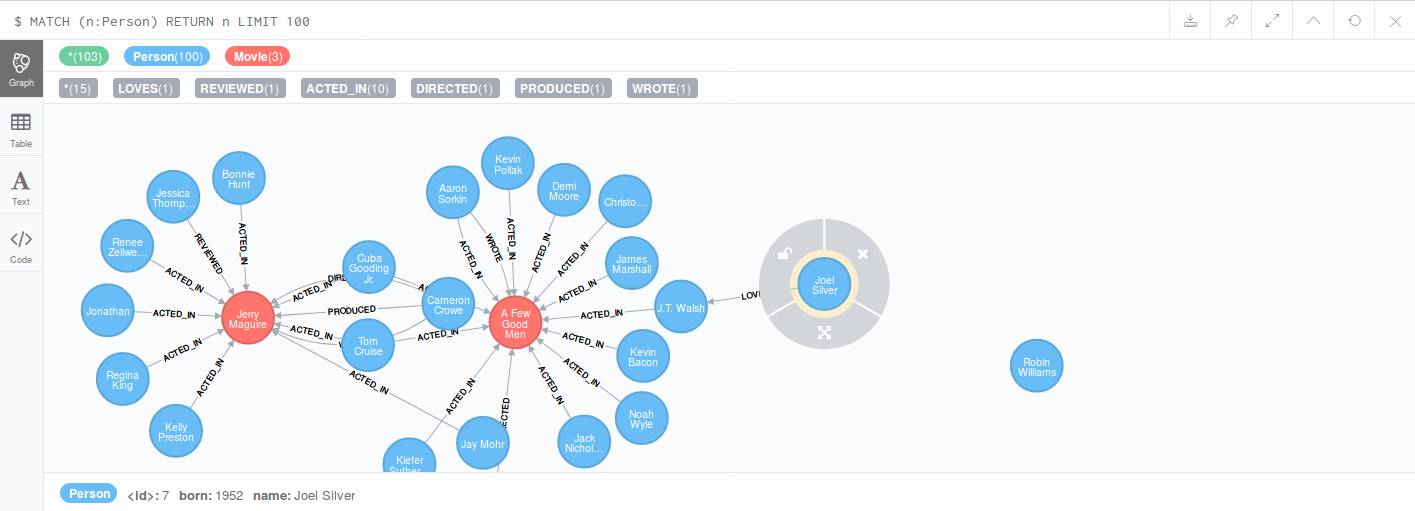
MATCH (p1:Person {name:”Jonathan Lipnicki”}),(p2:Person{name:”Joel
Silver”}), p=shortestpath((p1)-[*..10]-(p2)) RETURN p
这里 [*..10] 表示路径深度 10 以内查找所有存在的关系中的最短路径关系
得到图:
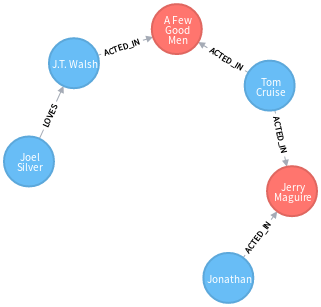
<2> 所有最短路径
MATCH (p1:Person {name:”Jonathan Lipnicki”}),(p2:Person{name:”Joel
Silver”}), p=allshortestpaths((p1)-[*..10]-(p2)) RETURN p
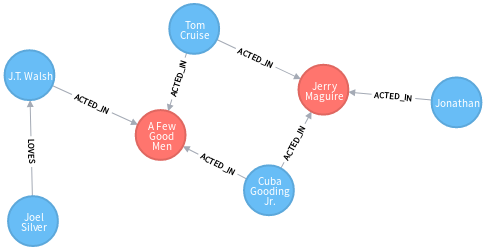
以上理论部分已经讲完,下面进入实战部分。
5. 案例实战
(1)银行欺诈环分析
这里引入一个概念,第一方银行欺诈,本质是使用他人真实身份编造和伪造身份进行欺诈。
有如下几个特点:
我们可以使用 Neo4j 来识别存在的欺诈环。
首先,我们创建欺诈环(由于篇幅限制,就不把代码贴在这里,可以参考这个教程 http://blog.sina.com.cn/s/blog_735f29100102wobk.html)。
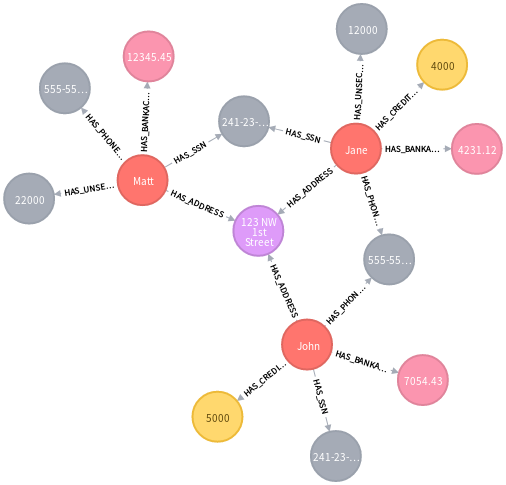
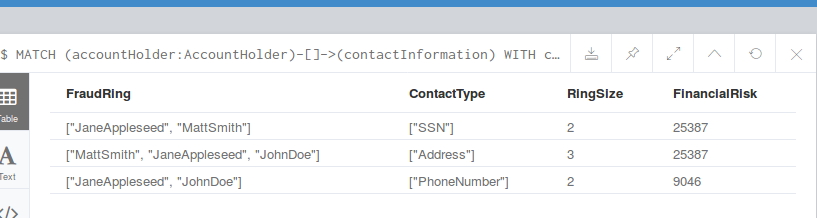
查询可疑的欺诈环:
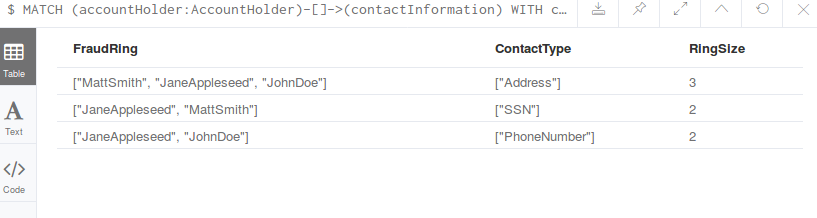
从左到右,欺诈环的成员,涉嫌欺诈的联系方式,欺诈环的大小。计算出欺诈的风险值:
(
2)文献索引
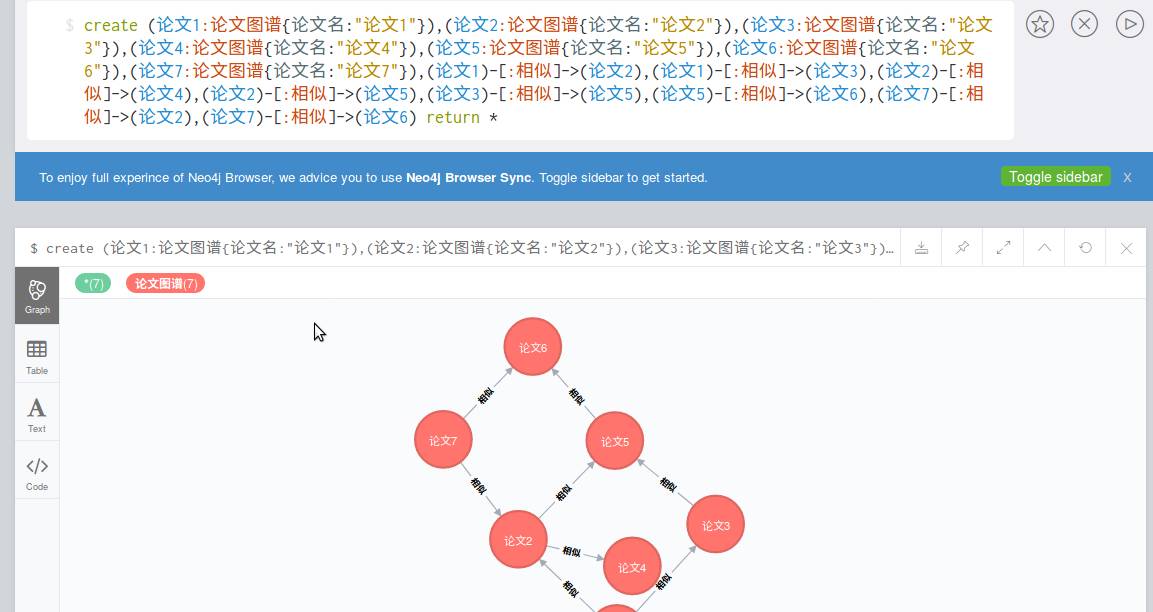
先举个小例子,在学术界需要查一些论文,通常是用全文搜索,这样的搜索效率不高。可以用 Neo4j 获取匹配度高的论文。这里先举个小例子。打开 Neo4j, 先手动插入数据。
create
(论文 1:论文图谱{论文名:” 论文 1”}),(论文 2:论文图谱{论文名:” 论文 2”}),(论文 3:论文图谱{论文名:” 论文 3”}),(论文 4:论文图谱{论文名:” 论文 4”}),(论文 5:论文图谱{论文名:” 论文 5”}),(论文 6:论文图谱{论文名:” 论文 6”}),(论文 7:论文图谱{论文名:” 论文 7”}),(论文 1)-[:相似]->(论文 2),(论文 1)-[:相似]->(论文 3),(论文 2)-[:相似]->(论文 4),(论文 2)-[:相似]->(论文 5),(论文 3)-[:相似]->(论文 5),(论文 5)-[:相似]->(论文 6),(论文 7)-[:相似]->(论文 2),(论文 7)-[:相似]->(论文 6) return *
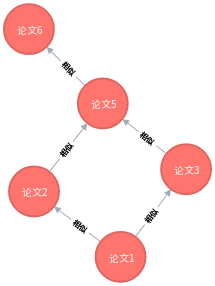
查找论文 1 到论文 6 之间相似的传递路径,这样就可以找出,论文的主要参考了那些论文。
MATCH n=allshortestPaths((论文 1:论文图谱{论文名:" 论文 1"})-[*..6]->(论文 6:论文图谱{论文名:" 论文 6"})) RETURN n
接下来,我想通过一个完整的例子实现文献索引,从数据获取,导入,再到分析。我将使用 Scrapy 爬取 1000 本书的信息。保存到 csv,导入 neo4j,再进一步分析。
首先是使用 Scrapy 爬取信息。数据爬下来后,是这样。
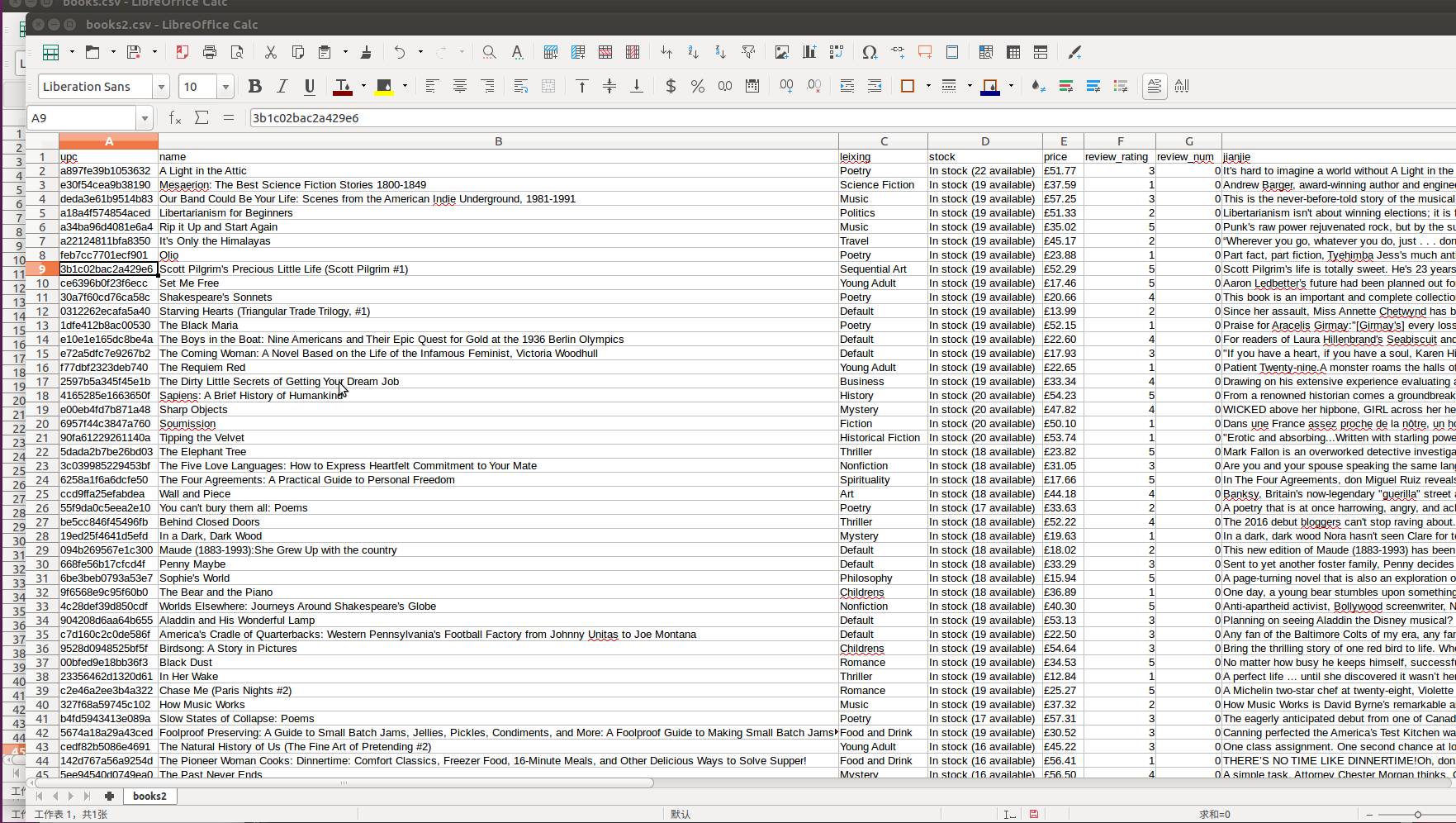
从左到右依次是书的 upc 编码,名字,类型,储存量,价格,评分,评分数目,简介目标网站是 http://books.toscrape.com/。先使用 scrapy shell 来操作一个爬虫,先简单进行爬取实验,把网页分析好。
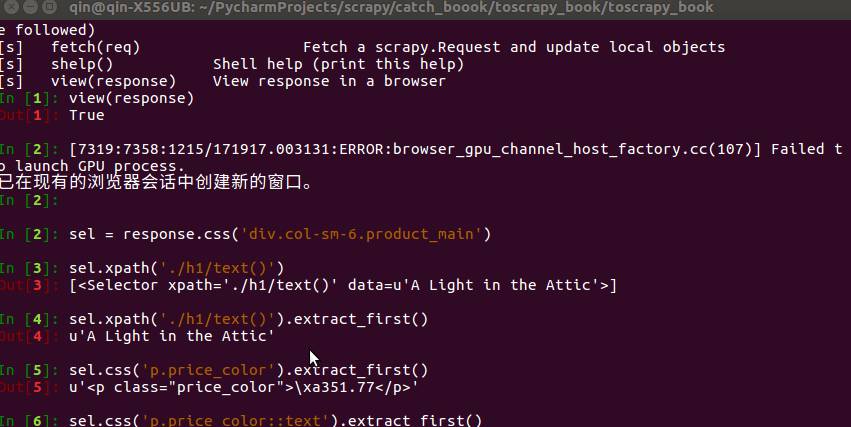
scrapy shell http://books.toscrape.com/catalogue/a-light-in-the-attic_1000/index.html
设计思路:
代码我已经上传到 git(https://coding.net/u/Qinxianshen/p/python-spider/git)。
通过 csv 文件,把数据导入 Neo4j。首先把 book2.csv 放到这个目录下:
/var/lib/neo4j/import
首先读取一下文件,看看是否能获取到:
LOAD CSV WITH HEADERS FROM "file:///books2.csv" AS line WITH line RETURN line
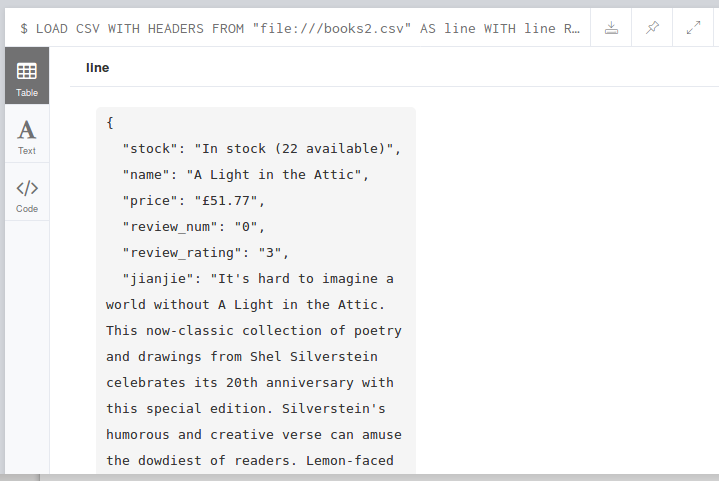
LOAD CSV WITH HEADERS FROM "file:///books2.csv" AS line CREATE (:Books { Id: line.upc, Name: line.name, Price: line.price,Rate:line.review_rating,content:line.jianjie,kinds:line.Kinds,stock:line.stock})
这样就把 1000 本书作为节点,存进去了。输出:
Added 1000 labels, created 1000 nodes, set 5998 properties, completed after 228 ms.
查询 25 个看看情况:

并且可以查看到各种属性。但是还没有关系。在创建几个书类节点:
create (n:书类名{n.Name=”Sequential Art”})
..
..
再建立关系:
MATCH (n:Books2),(m:书类名) where n.kinds = m.Name create(n)-[r:属于]->(m) RETURN n,r,m LIMIT 25
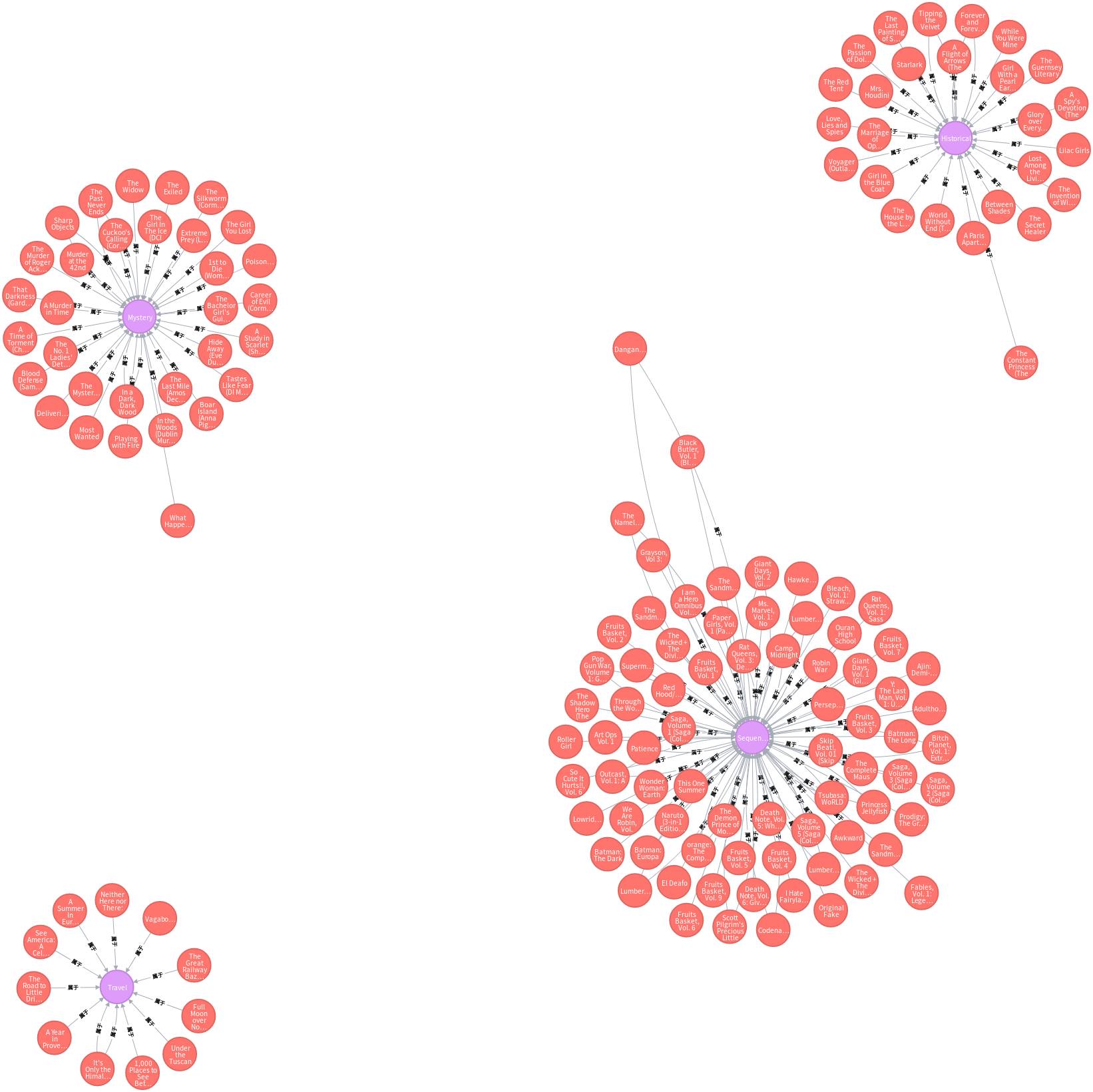
一个简单的书籍-门类图就建好了,现在我们可以通过书的评分,门类,价格进行索引。从而完成一个简单的书目推荐系统。在第五个案例我会合在一起做。
(3)寻找垃圾邮箱源头
如果你不想在本地下载 Neo4j,可以去可以登录微云数聚公司官网 在线尝试一下 Neo4j。这里我们就基于这个平台,来做一个垃圾邮件的案例。
在命令框输入:
MATCH m=(s:Person)-->(e:Email)-->(r:Person) WHERE e.title=~'.* 普通发票 .*' RETURN m LIMIT 15
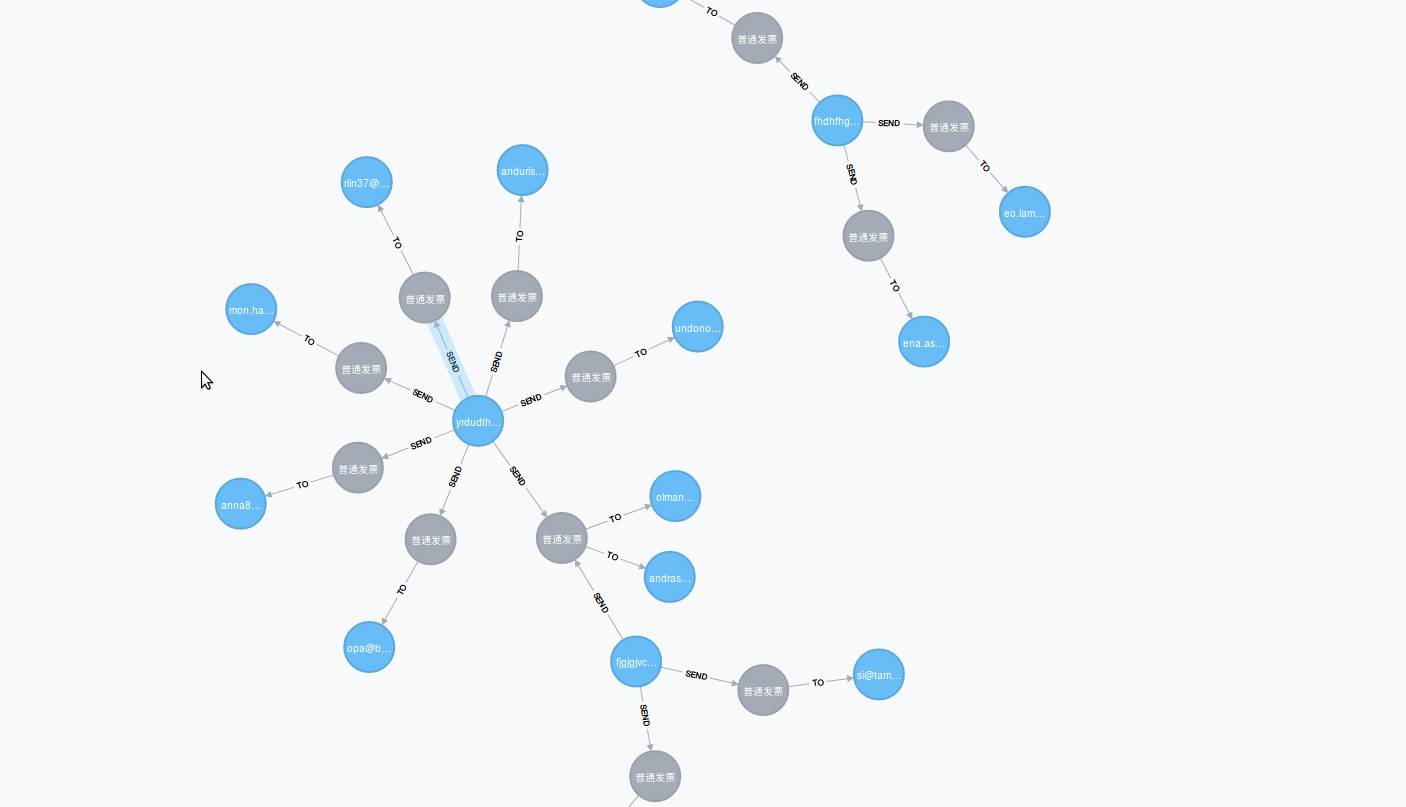
这里只返回了 15 个节点。如果我们要查到垃圾邮箱的源头,会怎么做?通常垃圾邮箱的标题或者内容会有关于促销,招聘等等字眼。
这里我们就通过对所有邮件的标题遍历,查找关键字 “发票”。如果经常发这种邮件的人,邮件数量一定很多。这里我们设置当有这种信件的数量超过 105,就输出他。
MATCH m=(s:Person)→(e:Email)→(r:Person)
WHERE e.title=~’.
发票 .
‘
WITH s,COUNT(e) AS num,COLLECT(e) AS emails,COLLECT(r) AS recevies
WHERE num > 105
RETURN s,emails,recevies
得到图:

很明显就发现,几乎所有发票都是来自这个邮箱 [email protected], 主犯找到了。
那么就可以发现这个主犯了。那么这样就结束了吗?不不,我在上文说过 “反向提问” 是很有价值的,既然找到了主犯,那么我们不妨多看看,
他还会经常发什么邮件,这类邮件有什么特征。从中挖掘出这类人,发垃圾邮箱的 “套路”。
MATCH m=(s:Person)→(e:Email)→(r:Person)
WHERE s.account=~’[email protected]’
RETURN s,e,r
得到图:
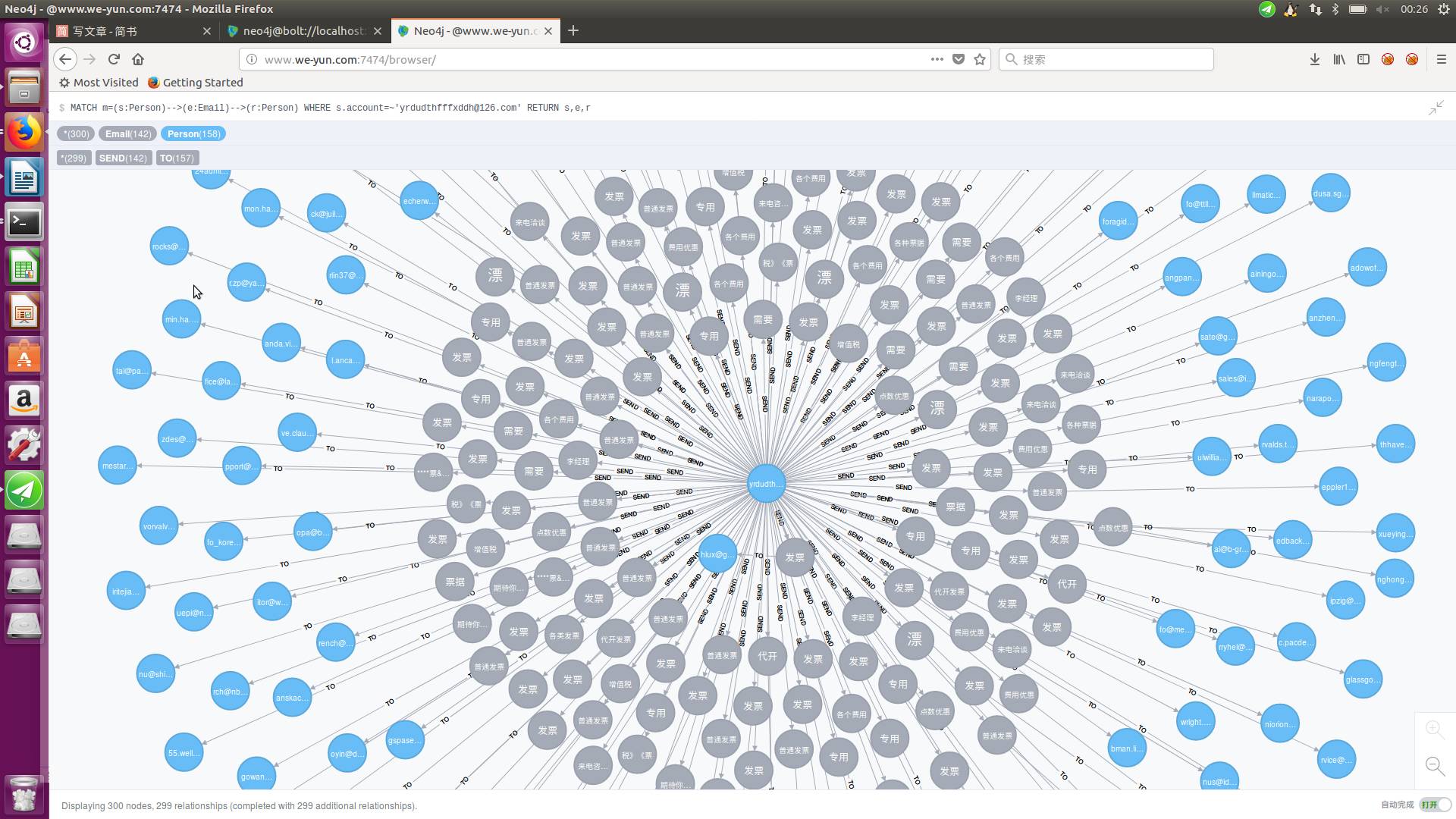
仔细观察,你会发现,这个主犯的邮件除了含 “发票” 的字眼,还有 “来电恰谈”,“费用优惠” 等字眼。那么这样我们就可以记住这样的字眼,下次就可以过滤这类字眼的邮件。
通过上面这个例子,应该能体会到,图数据库,在处理垃圾邮件,查找信息的优势了。特别是在处理 “反向提问” 的问题。并且查询效率都是在毫秒级别的。
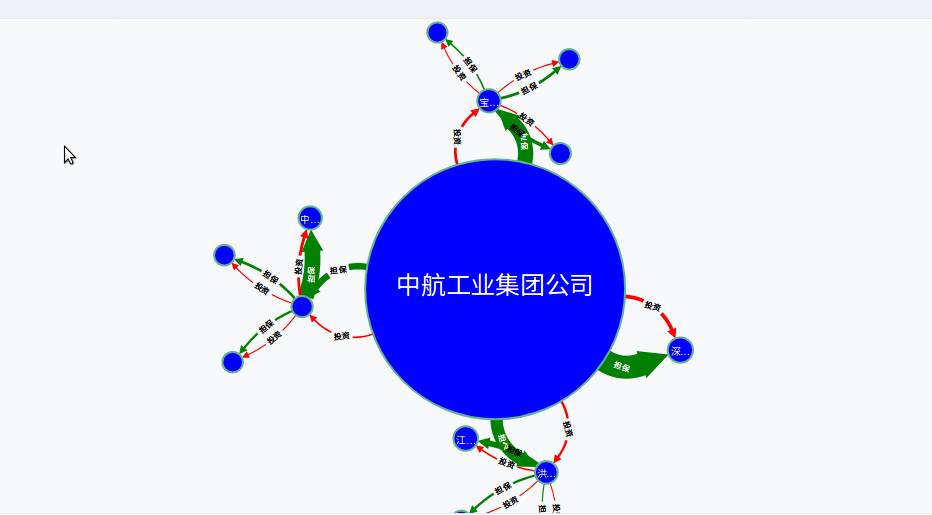
4)企业关系构建
这里还是基于微云数聚公司的平台。
MATCH (n:`公司`) RETURN n LIMIT 25
投资图:
MATCH a=(:公司 {名称:' 中航工业集团公司 '})-[r*]->() RETURN nodes(a)
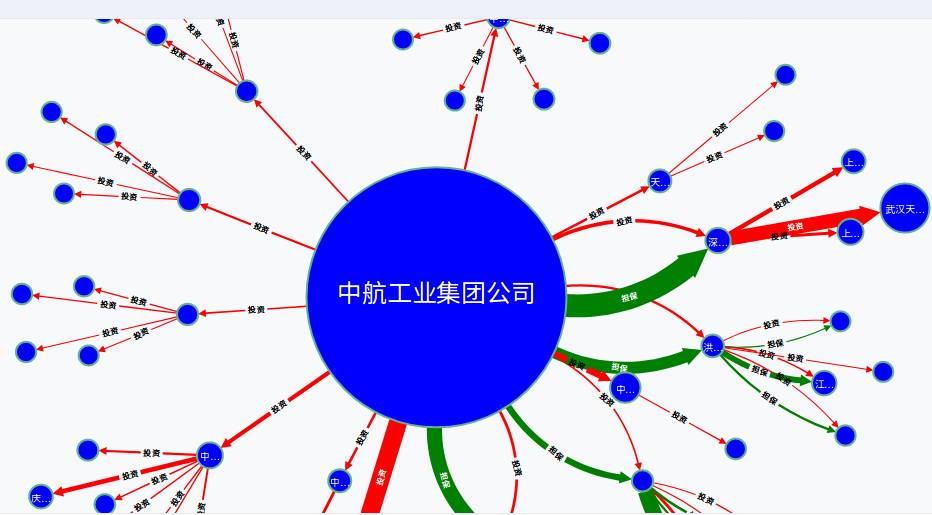
这样对于公司就有一个直观的把握。谁投资了谁,现金流的流向。对于公司的财务管理也有直观的展现。
担保图:
MATCH a=(:公司 {名称:' 中航工业集团公司 '})-[r:担保 *]->() RETURN nodes(a)