
原文来源
:
medium
作者:Harshvardhan Gupta
「机器人圈」编译:嗯~阿童木呀、多啦A亮
 众所周知,现如今,诸如神经网络这样的数据驱动算法已经风靡全球。而随着技术价格的降低、硬件的强大和数据的海量级增多,算法的应用领域也在逐渐扩张。目前,神经网络是涵盖图像识别和自然语言理解等“认知”任务领域中的最先进技术,但并不局限于这些任务。 在这篇文章中,我将讨论一种使用神经网络进行图像压缩的方式,以更快的速度实现图像压缩的最先进性能表现。
众所周知,现如今,诸如神经网络这样的数据驱动算法已经风靡全球。而随着技术价格的降低、硬件的强大和数据的海量级增多,算法的应用领域也在逐渐扩张。目前,神经网络是涵盖图像识别和自然语言理解等“认知”任务领域中的最先进技术,但并不局限于这些任务。 在这篇文章中,我将讨论一种使用神经网络进行图像压缩的方式,以更快的速度实现图像压缩的最先进性能表现。
本文基于《一个基于卷积神经网络的端到端压缩框架》实现的。
下载论文
。
在开始之前,本文假设你对诸如卷积和损失函数等神经网络有一定的了解。
图像压缩是转换图像的过程,以便使其占用较少的空间。对图像进行简单存储将会占用大量空间,所以有一些诸如JPEG和PNG这样的编解码器出现,目的是减小原始图像的大小。
有损与无损压缩
图像压缩有两种类型:无损和有损。顾名思义,在无损压缩中,有可能返回原始图像的所有数据,而在有损压缩中,有些数据会在转换期间丢失。
例如,JPG是一种有损算法,而PNG是一种无损算法。
无损和有损压缩之间的比较(原图、50%有损压缩、80%有损压缩)
请注意,请注意右侧的图像有许多块状的人工制品。这就是信息丢失的方式。附近的类似颜色的像素被压缩为一个区域,虽然节省了空间,但同时也丢失了关于实际像素的信息。当然,像JGEG、PNG等编解码器的实际算法要复杂得多,但这确实是有损压缩的一个较为直观的例子。无损压缩是很好,但它最终在磁盘上占用了大量的空间。
其实,有很多更好的方法可以用来压缩图像而不丢失大量信息,但是它们的运行速度非常慢,而且其中有很多需要使用迭代方法,这意味着它们不能在多个CPU内核或GPU上并行运行。因此,将它们应用于日常使用中显得非常不切实际。
如果需要计算任何东西,且可以近似,那就在其上使用神经网络。作者使用了一个非常标准的卷积神经网络来改善图像压缩。他们的方法不仅能够与“更好的方式”(如果没有更好)相媲美,还可以利用并行计算,使速度提高到一个不可思议的水平。
而究其原因,主要是因为卷积神经网络(CNN)非常善于从图像中提取空间信息,然后以一种更为紧凑的形式表示(例如,仅存储图像的“重要”部分)。作者想利用CNN的这种能力来更好地表现图像。
作者提出了一个双重网络。第一个网络,接收图像并生成一个紧凑表示(ComCNN)。然后,该网络的输出将通过标准编解码器(例如JPEG)进行处理。经过编解码器的处理,图像将被传递到第二个网络,这它将“修复”来自编解码器的图像,试图恢复原始图像。作者将其称为重建CNN(RecCNN)。同时,这两个网络都将进行迭代训练,类似于生成式对抗网络(GAN)。
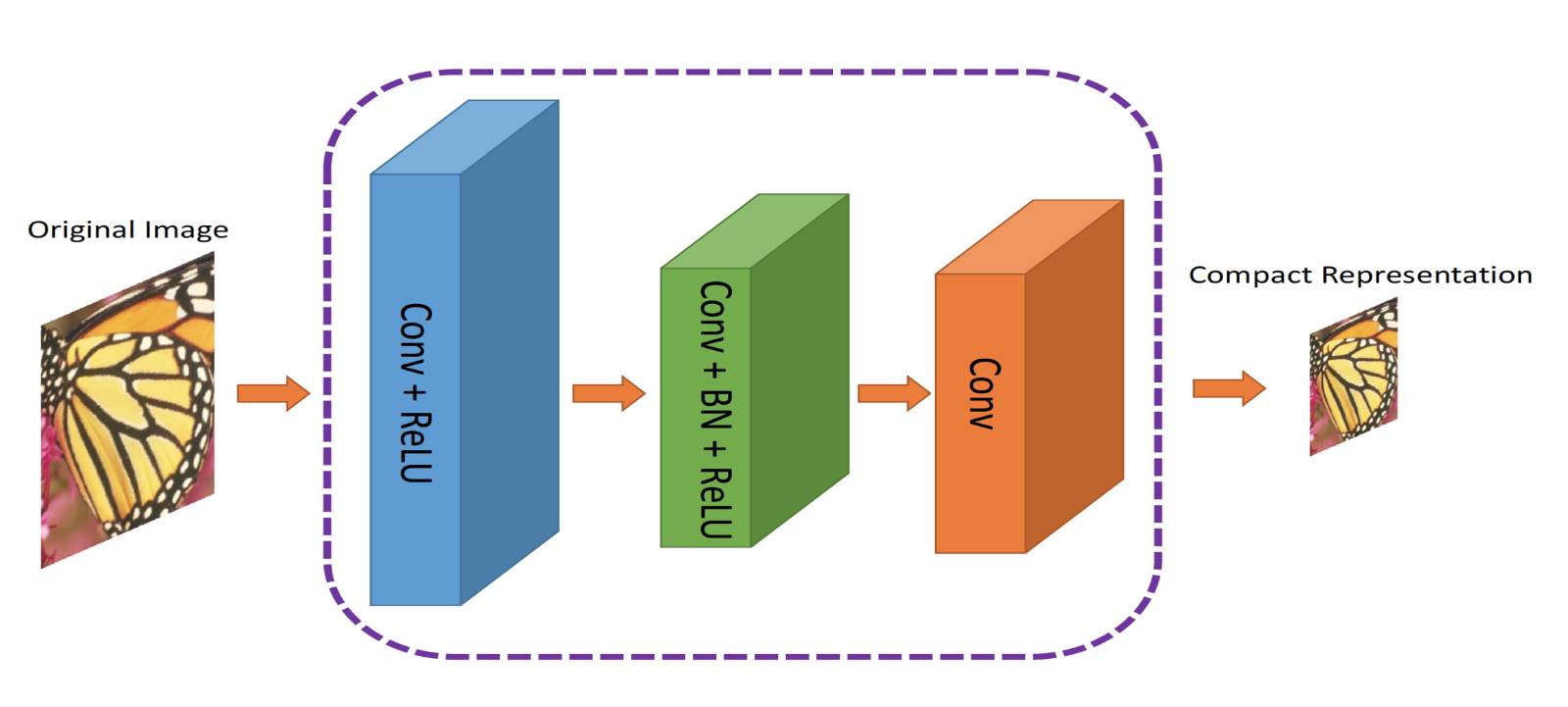
ComCNN ,将紧凑表示传递给标准编解码器
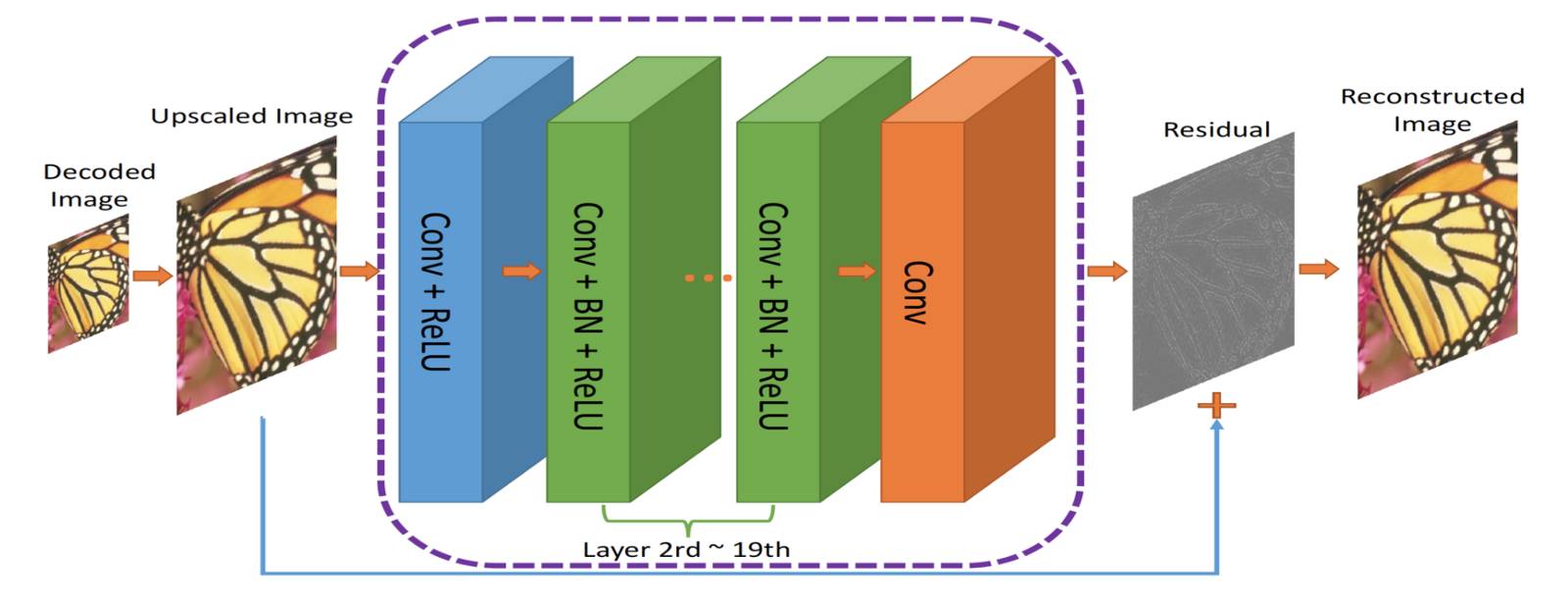
RecCNN,来自ComCNN的输出被放大并传递给RecCNN,它将试图学习残差
来自的编解码器的输出被放大,然后传递给RecCNN。RecCNN将尝试输出一个与原始图像相似的图像。

进行图像压缩的端到端框架,Co(.)表示图像压缩算法。作者使用JPEG、JPEG2000和BPG进行处理。
残差可以被认为是一个后期处理步骤,用以“改进”编解码器解码的图像。那些有着很多关于这个世界“信息”的网络,可以做出关于“修复”的认知决定。而这个想法的提出是基于残差学习的,更多有关更多信息可以参阅
此篇论文
。





