这次分享介绍Flannel中的vxlan backend,包含两方面内容:
深入理解内核中的VXLAN原理:使用iproute2和bridge等原生工具来搭建一个基于VXLAN的Overlay网络。
理解Flannel使用vxlan backend时的工作原理: 有了前面对内核VXLAN原理的理解,通过分析Flannel部分源码来从根本上掌握其vxlan backend的原理。
Virtual eXtensible Local Area Network(VXLAN)是一个在已有的3层物理网络上构建2层逻辑网络的协议。
在2012年底的v3.7.0之后,Linux Kernel加入了VXLAN协议支持,作者:Stephen Hemminger,所以如果要使用Linux Kernel中的VXLAN支持,最低内核版本3.7+(推荐3.9+)。
Stephen Hemminger同时也实现了iproute2、bridge等工具,用以管理Linux中复杂的网络配置,目前在绝大多数Linux发行版中都是默认支持的。
VXLAN本质上是一种tunnel(隧道)协议,用来基于3层网络实现虚拟的2层网络。泛泛地说,tunnel协议有点像今天电话会议,通过可视电话连接不同的会议室让每个人能够直接交谈,就好像坐在一个会议室里一样。很多tunnel协议,如GRE也有类似VXLAN中VNI的用法。
tunnel协议的另外一个重要的特性就是软件扩展性,是软件定义网络(Software-defined Network,SDN)的基石之一。
Flannel中有两个基于tunnel协议的backend:UDP(默认实现)和VXLAN,本质上都是tunnel协议,区别仅仅在于协议本身和实现方式。
这里顺便提一句:tunnel协议在比较老的内核中已经有支持,我印象中v2.2+就可以使用tunnel来创建虚拟网络了,因此UDP backend适合在没有vxlan支持的linux版本中使用,但性能会相比vxlan backend差一些。
以上是一些背景介绍,下面开始介绍VXLAN的内核支持
图1. VXLAN可以在分布多个网段的主机间构建2层虚拟网络
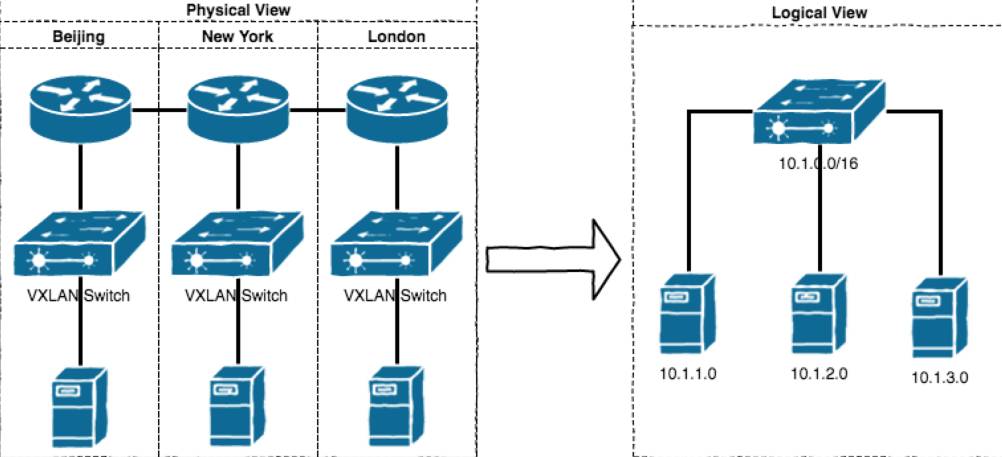
图2. VXLAN基本原理:套路还是tunnel那一套,区别仅仅在于tunnel协议本身的实现
为了说明图1和图2中谈到的VXLAN原理,这里在两台不同网段的VPS上手动搭建一个Overlay Network,并在两个节点上分别运行了Docker Container,当我们看到容器之间使用虚拟网络的IP完成直接通信时,实验就成功了。
图3 手动搭建vxlan虚拟网络的网络拓扑
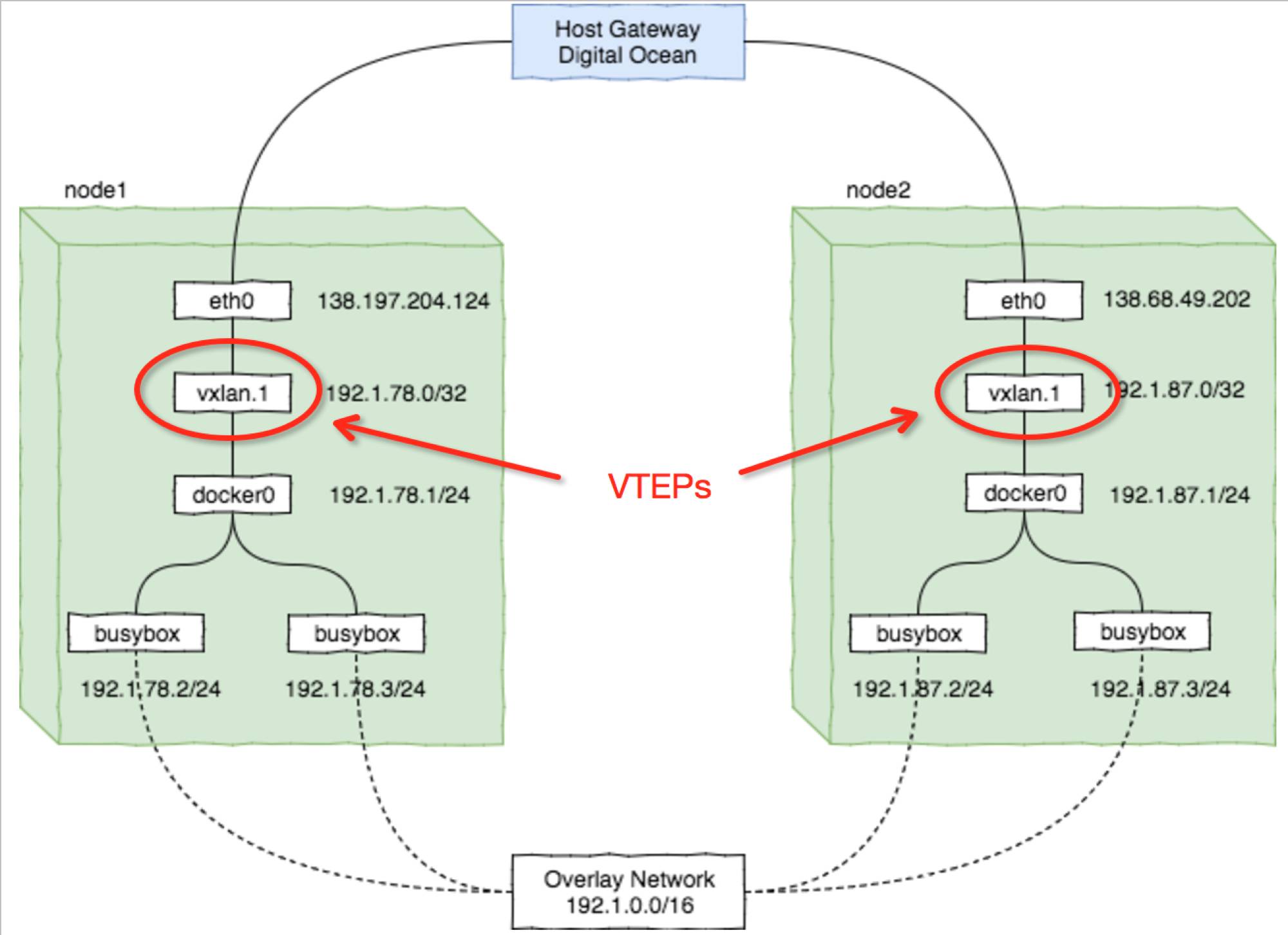
图3中提到一个VTEP的概念,全称VXLAN Tunnel Endpoint,本质上就是前面提到的tunnel中的endpoint
现在正式开始手动搭建图 3中的虚拟网络
第一步、创建docker bridge
默认的docker bridge地址范围是172.17.0.1/24(比较老的版本是172.17.42.1/24), 而本实验中两个节点node1和node2的子网要求分别为: 192.1.78.1/24,192.1.87.1/24 。
修改docker daemon启动参数,增加以下参数后重启docker daemon:
node1: --bip=192.1.78.1/24
node2: --bip=192.1.87.1/24
这时node1和node2的容器之间还不能直接通信, node1也不能跨主机和node2上的容器直接通信,反之node2也无法直接和node1上的容器通信.。
第二步、创建VTEPs
在node1上执行以下命令:
PREFIX=vxlan
IP=$external-ip-of-node-1
DESTIP=$external-ip-of-node-2
PORT=8579
VNI=1
SUBNETID=78
SUBNET=192.$VNI.0.0/16
VXSUBNET=192.$VNI.$SUBNETID.0/32
DEVNAME=$PREFIX.$VNI
ip link delete $DEVNAME
ip link add $DEVNAME type vxlan id $VNI dev eth0 local $IP dstport $PORT nolearning
echo '3' > /proc/sys/net/ipv4/neigh/$DEVNAME/app_solicit
ip address add $VXSUBNET dev $DEVNAME
ip link set $DEVNAME up
ip route delete $SUBNET dev $DEVNAME scope global
ip route add $SUBNET dev $DEVNAME scope global
node2上执行以下命令:
PREFIX=vxlan
IP=$external-ip-of-node-2
DESTIP=$external-ip-of-node-1
VNI=1
SUBNETID=87
PORT=8579
SUBNET=192.$VNI.0.0/16
VXSUBNET=192.$VNI.$SUBNETID.0/32
DEVNAME=$PREFIX.$VNI
ip link delete $DEVNAME
ip link add $DEVNAME type vxlan id $VNI dev eth0 local $IP dstport $PORT nolearning
echo '3' > /proc/sys/net/ipv4/neigh/$DEVNAME/app_solicit
ip -d link show
ip addr add $VXSUBNET dev $DEVNAME
ip link set $DEVNAME up
ip route delete $SUBNET dev $DEVNAME scope global
ip route add $SUBNET dev $DEVNAME scope global
第三步、为VTEP配置forward table
# node1
node1$ bridge fdb add $mac-of-vtep-on-node-2 dev $DEVNAME dst $DESTIP
node2
node2$ bridge fdb add $mac-of-vtep-on-node-1 dev $DEVNAME dst $DESTIP
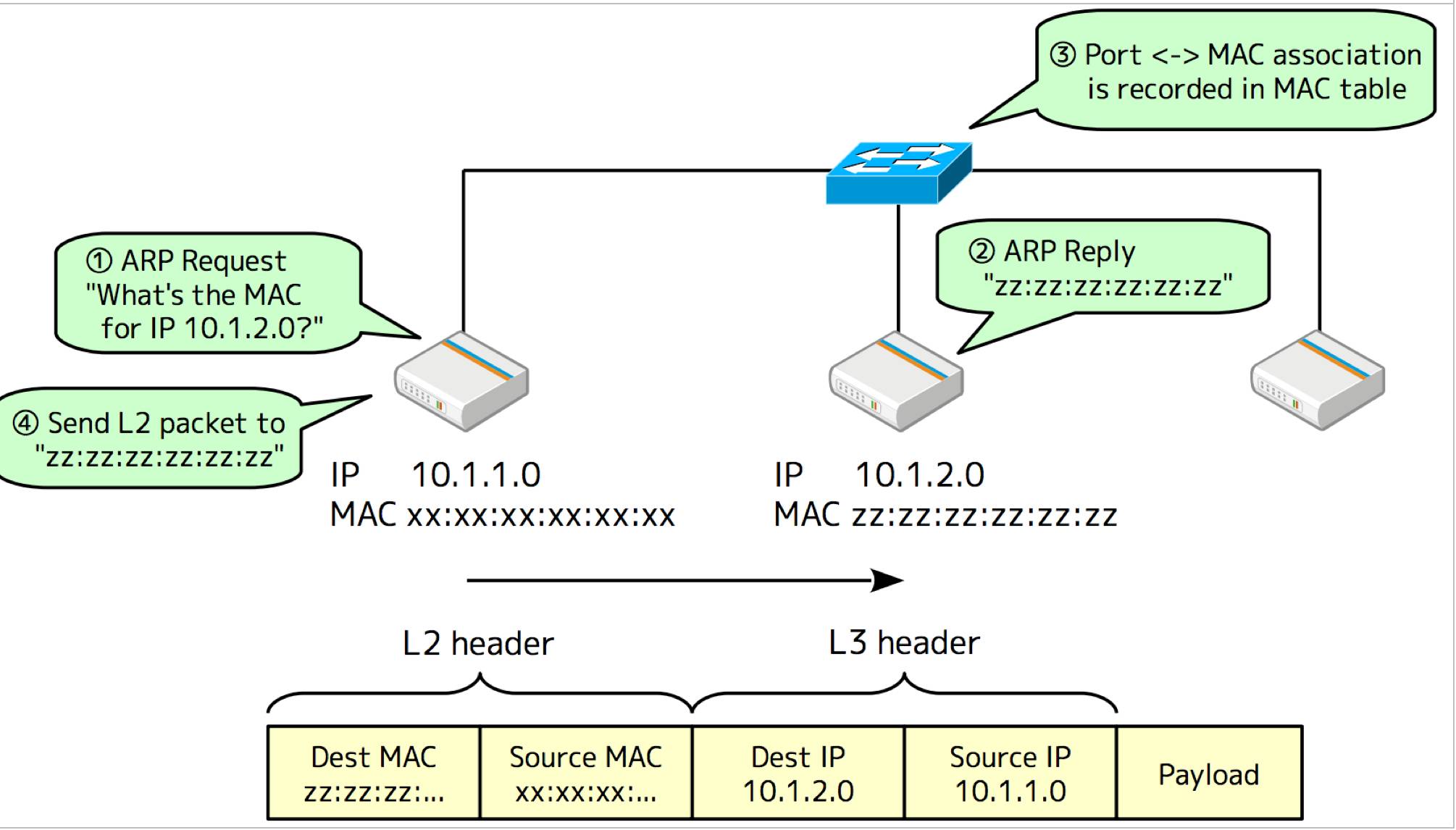
第四步、配置Neighbors,IPv4中为ARP Table
# node1
node1$ ip neighbor add $ip-on-node-2 lladdr $mac-of-vtep-on-node-2 dev vxlan.1
node2
node2$ ip neighbor add $ip-on-node-1 lladdr $mac-of-vtep-on-node-1 dev vxlan.1
注意
:ARP表一般不会手动更新,在VXLAN的实现中由对应的Network Agent监听L3 MISS来 动态更新;这里手动添加ARP entry仅仅是为了测试;另外,如果跨主机访问多个IP, 每个跨主机的IP就都需要配置对应的ARP entry。
以上操作都需要root权限,完成后整个Overlay Network就搭建成功了,下面通过测试两种连通性来总结本实验:
先看容器与跨主机容器间直接通信的测试。
现在node1和node2上分别起一个busybox:
node1$ docker run -it --rm busybox sh
node1$ ip a
1: lo: mtu 65536 qdisc noqueue qlen 1
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
6: eth0@if7: mtu 1500 qdisc noqueue
link/ether 02:42:c0:01:4e:02 brd ff:ff:ff:ff:ff:ff
inet 192.1.78.2/24 scope global eth0
valid_lft forever preferred_lft forever
inet6 fe80::42:c0ff:fe01:4e02/64 scope link
valid_lft forever preferred_lft forever
node2$ docker run -it --rm busybox sh
node2$ ip a
1: lo: mtu 65536 qdisc noqueue qlen 1
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
10: eth0@if11: mtu 1500 qdisc noqueue
link/ether 02:42:c0:01:57:02 brd ff:ff:ff:ff:ff:ff
inet 192.1.87.2/24 scope global eth0
valid_lft forever preferred_lft forever
inet6 fe80::42:c0ff:fe01:5702/64 scope link
valid_lft forever preferred_lft forever
接下来让我们来享受一下容器之间的连通性。
node1@busybox$ ping -c1 192.1.87.2
PING 192.1.87.2 (192.1.87.2): 56 data bytes
64 bytes from 192.1.87.2: seq=0 ttl=62 time=2.002 ms
node2@busybox$ ping -c1 192.1.78.2
PING 192.1.78.2 (192.1.78.2): 56 data bytes
64 bytes from 192.1.78.2: seq=0 ttl=62 time=1.360 ms
然后看主机和跨主机容器之间连通性的测试。
node1$ ping -c1 192.1.87.2
PING 192.1.87.2 (192.1.87.2) 56(84) bytes of data.
64 bytes from 192.1.87.2: icmp_seq=1 ttl=63 time=1.49 ms
node2$ ping -c1 192.1.78.2
PING 192.1.78.2 (192.1.78.2) 56(84) bytes of data.
64 bytes from 192.1.78.2: icmp_seq=1 ttl=63 time=1.34 ms
具体实验的截屏可以访问:https://asciinema.org/a/bavkebqxc4wjgb2zv0t97es9y 。
二、Flannel中vxlan backend实现

弄清楚了kernel中vxlan的原理后,就不难理解Flannel的机制了。
注意:
这里讨论的源码基于最新稳定版v0.7.0。
vxlan backend启动时会动态启动两个并发任务:
关于源码,请看:http://dwz.cn/5MXKuC
最后,Flannel的实现中有一个小细节,在0.7.0中刚刚加入,即VTEP的IP加上了/32位的掩码避免了广播,此前的版本都是/16掩码,解决了VXLAN网络中由于广播导致的“网络风暴”的问题。
-
Flannel中有多种backend,其中vxlan backend通过内核转发数据,而udp backend通过用户态进程中的proxy转发数据
-
Flannel在使用vxlan backend的时候,短暂启停flanneld不会造成网络中断,而udp backend会
-
很多第三方的网络测试表明,udp backend比vxlan backend网络的性能差大概1个数量级,一般来说只要内核支持(v3.9+),建议选择vxlan backend
-
Flannel中使用vxlan backend时,建议升级到0.7+,因为此前的版本都存在潜在的网络风暴问题
Q:Flannel 创建多个网络,并且实现网络之间隔离可以实现吗?
A:是的,最新的Flannel中已经加入管理多个网络的能力,你可以在启动时制定多个网络,etcd中配置信息的的格式略有不同,启动flanneld时有参数可以制定初始化哪几个网络。
Q:如果使用Flannel过程中发现,跨节点无法访问,该从哪些方便着手排错?
A:首先看一下你指定的虚拟网络是否和现有物理网路中的网段冲突了;然后检查节点之间的UDP端口是否可以连通,最后还需要考虑当前系统是否支持VXLAN,最低要求v3.7,建议v3.9+,CentOS7的默认内核已经可以满足要求。
Q:过一组测试数据两台VM to VM (vlan): 7.74 GBits/sec,使用flannel vxlan,两个container之间 1.71 GBits/sec,请问这个数据正常吗,vxlan的带宽损耗发生哪,有啥调优思路,谢谢。
A:首先我想确认一下你测试的结果是TCP还是UDP,建议实际测试一下,这个是我在Digital Ocean上2台VPS间的测试结果,仅供参考:http://dwz.cn/5MXNbV,性能评估搞清楚原理以后,相信很容易判断瓶颈位置:节点之间是通过UDP来转发L2的数据包的,我认为这部分可能有比较大的嫌疑。
Q:Flannel 在使用过程中,如果需要新增网段,如何让每个节点获取最新的路由表信息?需要更新所有节点的Flannel配置项,重启Flannel 吗?
A:这个问题其实还不错,比较接近实战了;首先你确实可以重启flanneld来更新网络配置;然后Flannel每24h会自动重新分配集群内的网络,所以你就算不重启,每24h也会自动刷新本地网络的,如果发现本地网络配置不符合Flannel在etcd中配置的要求,会重新生成网络配置。
Q:我在项目中用了flanne lvxlan backend。按照文中说法,转发由内核进行,Flannel挂掉并不影响通宵。但是实际使用中,Flannel挂掉确实导致外部其他访问不到Docker。请问这个可能是什么原因?
A:首先要澄清一下,并不是说挂掉网络没影响,flanneld挂掉会导致本地的ARP entry无法自动更新,但是已经生成的网络环境还是可用的,具体可以看我前面手动搭建overlay network的过程,根本在于ARP table。





