本文转载自网络。转载编辑过程中,可能有遗漏或错误,请以原文为准。
原文作者:水墨寒湘
原文链接:https://juejin.im/post/582dfcfda22b9d006b726d11
正则表达式对于我来说一直像黑暗魔法一样的存在。手机正则去网上搜,邮箱正则去网上搜,复杂点的看看文档拼凑一下,再复杂只能厚着脸皮让其他同事给写一个,从来没有系统的学习过。关于作者这几句话,我是深有感触,有幸畅游网络看到这篇博文和对应的慕课网视频,让我收获颇多,在此转载,希望给更多需要的朋友带来帮助。
视频地址:http://www.imooc.com/learn/706
一、学习目标:
二、什么是正则表达式
正则表达式,又称正规表示式、正规表示法、正规表达式、规则表达式、常规表示法(英语:Regular Expression,在代码中常简写为regex、regexp或RE),计算机科学的一个概念。正则表达式使用单个字符串来描述、匹配一系列匹配某个句法规则的字符串。在很多文本编辑器里,正则表达式通常被用来检索、替换那些匹配某个模式的文本。
通俗的讲就是按照某种规则去匹配符合条件的字符串。
三、利用图形化工具理解正则表达式
辅助理解正则表达的在线工具(https://regexper.com/)我们利用这个工具辅助理解,正则表达式。语法没懂表着急,后面会有,这里只是学会用工具帮助我们学习。
手机号正则
/^1[34578][0-9]{9}$/
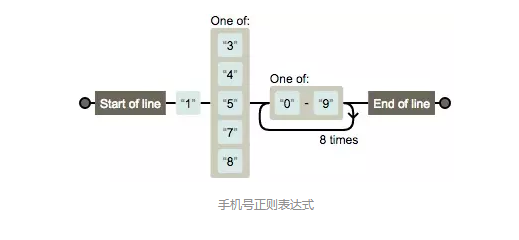
tips:以1开头,第二位为3 4 5 7 9 其中一个,以9位(本身1次加重复8次)0-9数字结尾。
单词边界
/\bis\b/

tips:is前后都是单词的边界,比较晦涩难懂?感受下两者的区别,\b 会方道语法部分讲解
URL分组替换
/http:(\/\/.+\.jpg)/
看不懂的不要慌语法部分后面会有介绍,这里只是展示利用可视化的图形帮助我们理解正则表达式,可以回来再看木有关系。

正则表达式中括号用来分组,这个时候我们可以通过用$1来获取 group#1 的内容。
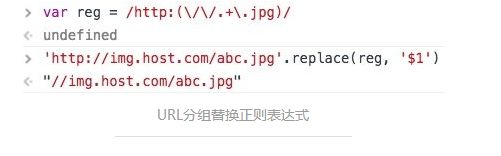
说下这个正则的意义,如果网站用了https,网站引用静态资源也必须是https,否则报错。如果写成 // 会自动识别 http 或者 https。
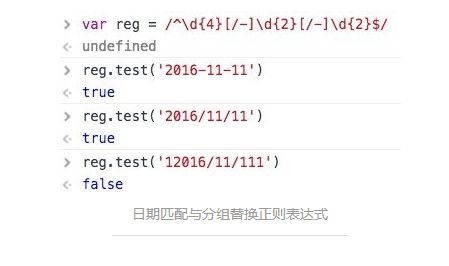
日期匹配与分组替换
/^\d{4}[/-]d{1,2}[/-]\d{1,2}$/
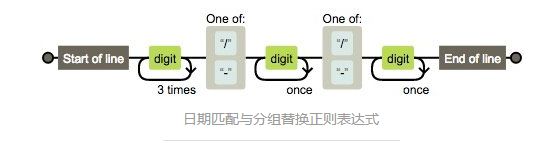
这个正则比较复杂,画符念咒的地方太多了,一一分析:
1、Start of line 是由^生效的表示以此开头
2、对应结尾End of line 由$生效表示以此结尾
3、接着看digit 由 \d 生效表示数字
4、3times 由{4} 生效表示重复4次
开始的时候有疑问,为什么不是 4times,后来明白作者的用意,正则表达式是一个规则,用这个规则去从字符串开始匹配到结束(注意计算机读字符串可是不会分行的,都是一个串,我们看到的多行,人家会认为是个 \t )这里设计好像小火车的轨道一直开到末尾。digit 传过一次,3times表示再来三次循环,共4次,后面的once同理。 自己被自己啰嗦到了。
5、接下来,是 one of 在手机正则里面已经出现了。表示什么都行。只要符合这两个都让通过。
好了这个正则解释完了,接下来用它做什么呢?
我们可以验证日期的合法性。结合URL分组替换所用到的分组特性,我们可以轻松写出日期格式化的方法。
改造下这个正则:
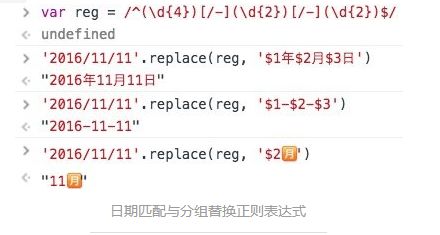
/^(\d{4})[/-](\d{1,2})[/-](\d{1,2})$/
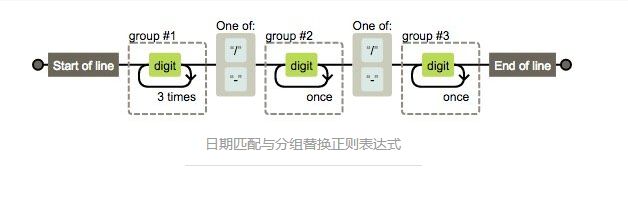
轻松的可以拿到 group#1 #2 #3 的内容,对应 $1 $2 $3。
到现在已经能结合图形化工具看懂正则表达式表达式了,如果想自己写,还要在正则语法上下点功夫
四、JS中REGEXP对象
Javascript 通过内置对象RegExp支持正则表达式,有两种方法实例化RegExp对象。
字面量方法
const reg =/\bis\b/g
构造函数
const
reg = new RegExp('\\bis\\b', 'g')
五、正则表达式语法
修饰符(三个 g 、i、m)
修饰符与其他语法特殊,字面量方法声名的时候放到//后,构造函数声明的时候,作为第二个参数传入。整个正则表达式可以理解为正则表达式规则字符串+修饰符。
修饰符可以一起用。
const reg =/\bis\b/gim
来说说他们有什么作用。
有g和没有g的区别

没有g只替换了第一个,有g 所有的都换了

有i和没有i的区别
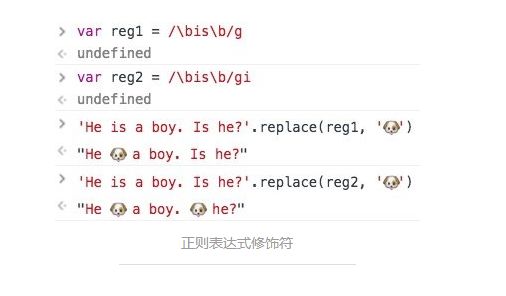
有i忽略大小写,没有i严格区分大小写

元字符
正则表达式由两种基本字符组成:
原义字符
这个没什么好解释的,我们一直在举例的 /is/ 匹配字符串'is'。
\
将下一个字符标记为一个特殊字符、或一个原义字符、或一个向后引用、或一个八进制转义符。例如,n”匹配字符“n”。“\n”匹配一个换行符。序列“\”匹配“\”而“(”则匹配“(”。
非打印字符
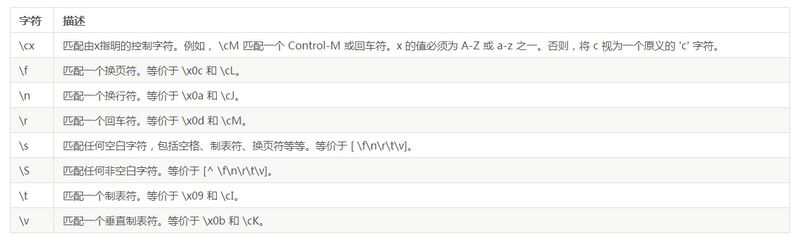
非打印字符,以\n为例。
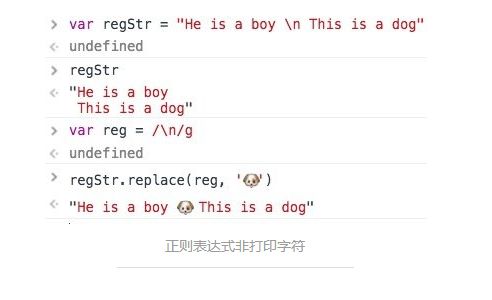
其他的在前端引用比较少,应该在后端处理文本文件的时候会用到。
字符类 []
在前面的手机号正则例子🌰中,我们已经使用过[] /^1[34578][0-9]{9}$/
[34578]表示34578任意一个数字即可。在日期匹配与分组替换例子🌰中 /^\d{4}[/-]\d{2}[/-]\d{2}$/ 表示符合 / - 都可以

字符类取反 [^]
表示不属于此类

空格也不属于,好多狗
范围类[-]
正则表达式支持一定范围规则比如 [a-z] [A-Z] [0-9] 可以连写[a-z0-9] 如果你只是想匹配-在 范围类最后加-即可。请看实例。

预定义类
常用为了方便书写。
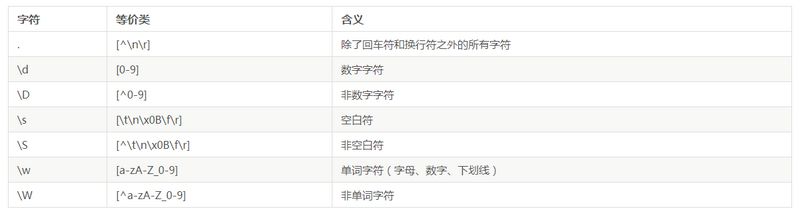
有了这些预定义类,写一些正则就很方便了,比如我们希望匹配一个 ab+数字+任意字符 的字符串,就可以这样写了 /ab\d./。
边界

边界顾名思义即定义匹配的边界条件,上面基本都在前面的例子碰到了,这里演示下\b与\B 的区别。

量词

如果没有量词,要匹配4位数字这样写就可以/\d\d\d\d/, 如果匹配50位100位呢?那不是要疯掉了?
有了量词,就可以这样写/\d{100}/, 量词的使用我们在手机号中使用过,表现在可视化中就是循环多少次。
凑一个上面都包含的实例/\d?@\d*@\d+@\d{10}@\d{10,20}@\d{10,}@\d{0,10}/。

贪婪与懒惰(非贪婪)
正则表达式默认会匹配贪婪模式,什么是贪婪模式呢?如其名尽可能多的匹配。我们看个例子。
/\d{3,6}/

贪婪模式下,匹配的了最多的情况。
与贪婪对应就是懒惰模式,懒惰对应的就是匹配的尽可能少的情况。如何开启懒惰模式? 在量词后面加?。继续上面的例子。
/\d{3,6}?/
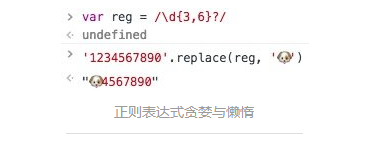
如果想知道,正则表达式是如何匹配量词的,请看进阶正则表达式文中有介绍,正则是如何回溯的。
分组与反向引用
分组,又称为子表达式。把正则表达式拆分成小表达式。概念枯燥,说个例子为嘛用分组:
不分组
/abc{2}/
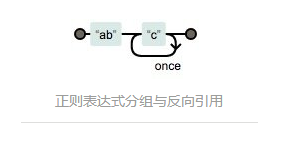
量词仅作用到最后的c。
分组
/(abc){2}/
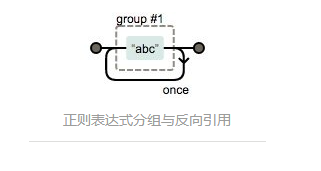
注意这里 group #1,分组虽然和运算符() 很像,但是分组在正则表达式中,注意理解组的含义。经常有人滥用分组。










