2017年6月10-11日,SDCC 2017·深圳站火热开启,拥有互联网应用架构实战峰会、大数据技术实战峰会两大峰会,秉承干货实料的内容原则,邀请业内顶尖的架构师和数据技术专家,共话高可用/高并发/高性能的系统架构设计、分布式缓存服务、Web App前端架构、消息引擎架构、弹性计算、大数据平台构建、优化提升大数据平台的各项性能、Spark部署实践、企业流平台实践,以及实现应用大数据支持业务创新发展等核心话题,旨在通过来自国内一线互联网公司的实践案例,为开发者提供一个最有价值的高效技术交流平台。干货自助时代,SDCC带你高台起步,走近技术圈的浮生万象。
日前主办方也公布了大会的完整版日程,加长版预告高能来袭,It’s all for you:

大牛云集,热点齐聚:以下是本次SDCC深圳站嘉宾+议题合集首次完整披露,精彩内容提前看。
徐海峰 阅文集团

徐海峰,阅文集团首席架构师,主要负责内容中心的网站架构和分布式存储、分布式计算工作。10年互联网开发经验,为开源分布式文件系统fastdfs提交过代码。曾历任Ctrip国际机票引擎架构师、5173分布式存储和分布式计算架构师。多年来一直致力于网站架构和分布式计算的研究与实现,对大型网站架构和分布式计算有丰富的经验。
冯嘉 阿里巴巴

阿里巴巴中间件架构师 冯嘉
个人简介:阿里巴巴中间件架构师,具有丰富的分布式软件架构、高并发网站设计、性能调优经验,拥有多项分布式、推荐领域的专利。开源爱好者,关注分布式、云计算、大数据领域。目前主要负责阿里巴巴消息中间件生态输出、MQ商业化 ,Apache RocketMQ联合创始人,社区布道者。
演讲主题:《万亿级消息引擎架构、核心技术与最佳实践-Apache RocketMQ》
演讲简介:分布式消息引擎涵盖并试图解决分布式领域的什么问题?消息领域常见的问题域以及业界开源与商业化产品的发展又是如何? 阿里巴巴捐赠给Apache的RocketMQ核心技术背后的设计思路是什么样的?哪些场景里用到了分布式消息引擎,如何正确的使用消息引擎,最佳实践如何?关于下一代消息引擎,我们的设计思路又是什么样的?Apache RocketMQ社区未来何去何从? 本次分享,尝试从以上问题着手,深入浅出的为大家讲述Apache RocketMQ背后的设计思路、典型场景、最佳实践以及社区运营与商业化之路。
听众受益:
1. 了解分布式消息领域以及相关产品、技术体系;
2. 学习Apache RocketMQ核心技术设计原理以及最佳实践;
3. 了解Apache RocektMQ开源社区演进历史,发展规划。
陈波 新浪微博

新浪微博研发中心平台架构技术专家 陈波
个人简介:新浪微博研发中心平台架构技术专家。08年加入新浪,参与IM系统的后端研发。09年之后从事新浪微博的系统研发及架构工作,在海量数据存储、峰值访问、规模化缓存服务及开放平台等方面参与技术架构改进,当前主要负责微博平台的基础设施、中间件的研发及架构优化工作,经历新浪微博从起步到成为数亿用户的大型互联网系统的技术演进过程。
演讲主题:《支持百亿级访问,微博Feed的缓存架构及其演进之路》
演讲简介: 2009年新浪微博上线,2013年日活用户6140万,2016年日活用户1.2亿。微博系统运行中,面对千亿级Feed、百亿级访问、80-100万的分钟峰值发表,良好架构且不断改进的Feed缓存体系起了非常重要的支撑作用。本次分享将基于微博的Feed系统架构,介绍微博的缓存模型、缓存体系架构及缓存体系在微博的扩展及演进。
听众收益:
1. 如何对海量数据访问进行高效、可靠的访问加速?可以借鉴微博的经验,根据系统特点构建不同的缓存体系;
2. 如何应对cache节点故障,使部分节点故障不影响整体缓存架构的读写性能、命中率? 可以参考微博的缓存架构;
3. 各种内容都Feed化的今天,在快速响应Feed请求的同时,如何做到Feed的各种状态、计数、扩展信息的实时更新?参考微博的计数器、存在性判断;
4. 如何应对突发峰值流量?面对业务快速增长,cache 节点变更频繁,如何做到容量的无痛扩缩? 参考微博的缓存架构,缓存服务化方案。
陈杰 腾讯

腾讯架构平台部高级工程师 陈杰
个人简介: 2007毕业于中科院计算所,现任职于腾讯架构平台部,负责虚拟化平台建设,经历了腾讯内部从xen,kvm到docker的演化过程,致力于利用虚拟化技术提升资源调度及利用效率,降低业务整体成本。
演讲主题:《基于空闲资源的弹性计算实践》
演讲简介:腾讯内部业务以在线型为主,且业务场景多样化,为保障服务质量,未考虑资源均衡分时的高效利用;近年随着图片,视频,数据挖掘,AI等计算需求逐渐增多,计算成本逐渐成为一种不可承受之重,为解决这个问题,建设了腾讯计算平台,通过挖掘在线业务闲置资源,供给计算业务使用,节省了大量计算成本,本次演讲的大纲如下:
1. 背景及演进历史;
2. 整体架构方案;
3. 如何保障在线业务质量;
4. 如何保障计算业务质量;
5. 如何保障平台调度成功率;
6. 弹性计算实践的经验体会。
听众受益:
1. 了解现网业务资源复用办法;
2. 了解大规模资源复用背后的质量保障机制。
薛珂 唯品会

唯品会基础架构部高级架构师 薛珂
个人简介:互联网技术创业老兵,曾参与主导多个大型互联网产品的整体架构;2016加入唯品会,现为基础架构团队核心成员;兴趣集中在架构设计,分布式设计,任务调度,搜索引擎,优雅设计等领域;目前主导唯品会开源弹性调度平台Saturn的研发,推广以及开源社区的维护。
演讲主题:《日调度3000万次,任务调度系统Saturn的架构设计和演进历程》
演讲简介:跟大家分享一下关于我们对于什么是好的任务调度系统的理解和相关的经验,主要的内容有:
1. 任务调度系统的架构设计;
2. Saturn的前世今生;
3. Saturn在唯品会的应用实践;
4. 任务调度系统的选型经验。
听众收益:
1. 掌握任务调度系统的基本原理及概念;
2. 了解当前业内任务调度领域的发展现状;
3. 通过了解唯品会的经验,为任务调度系统选型提供一些参考依据。
陶清乾 百度

百度网页搜索部资深研发工程师 陶清乾
个人简介: 2013年加入百度PS-FE团队,先后负责百度Web搜索前端速度优化,百度搜索全站HTTPS改造,搜索生态体验提升等专题工作。自2016年起,负责百度搜索前端极速浏览框架研发工作;2016底开始负责PWA与百度搜索和结合与落地工作。
演讲主题:《基于PWA的Web App前端架构探索与实践》
演讲简介:本次主题演讲将从Web App生态体验改善角度出发,讲述Web App生态如何通过PWA改善如今困境,开发者如何通过PWA提升自己Web站点体验,以及百度搜索在PWA中的探索与实践经验,演讲主要为:
1. Web App生态现状;
2. PWA给Web App的体验与技术的福利:PWA价值与收益;
3. PWA技术下的前端架构新思路:从离线化和交互打磨PWA体验;
4. PWA最佳实践经验:PWA技术选型与效果评估。
听众受益:
1. 学习了解PWA技术原理;
2. 了解PWA在设计与开发时与传统Web的区别;
3. 了解百度实际产品的PWA实践经验。
陈秋余 前卷皮网

前卷皮网架构服务部技术总监 陈秋余
个人简介: 资深架构师&技术管理专家,十多年传统企业应用与互联网从业经验;曾主导中国移动集团、南方电网IT战略架构规划,有负责过某知名移动特卖电商从0到1的技术架构落地,支撑数亿PV,百万级日订单;经历过多种类型,不同阶段的技术团队,注重团队组织与技术架构融合互促,对敏捷有深刻理解。在TOGAF,SOA以及微服务领域有相当建树。
演讲主题:《领域模型 + 内存计算 + 微服务的协奏曲:乾坤》
演讲简介:
1. 解决分布式事务困惑的最佳选择是不要使用分布式事务;
2. 解决高并发争抢的最优方式是避免竞争争抢的发生;
3. 乾坤,一套经过线上大规模实践验证过的,无锁无阻塞,基于异步和内存计算的超强性能的微服务架构;除了HA&HP,它还可以带给你们更多的惊喜。
听众受益:
1. 拓展新的视野和思路:接触一种较为新颖的微服务架构,和主流RPC微服务框架截然不同的架构逻辑;
2. 解决微服务业务边界和粒度切分的困惑问题;
3. 解决微服务跨域查询的尴尬;
4. 重新认识领域建模的价值:不光能解决业务复杂度问题,更可以提高性能。
帅翔 阅文集团

阅文集团架构师 帅翔
个人简介:阅文集团内容平台中心存储系统架构师。
演讲主题:《PB级去内存化的分布式缓存系统Lest的架构设计与实践》
演讲简介:分布式文件缓存系统,可以将数据对象经特定格式序列化后,存储到分布式文件系统中,并提供可靠的数据访问接口。各存储节点间保证负载均衡。各镜像节点支持主主模式,并保证数据同步。当前可以支持支持List和Map形式的数据对象。本次演讲的主要内容如下:
1. 缓存系统的背景及现状;
2. 系统的整体架构;
3. 如何持久化以及访问数据;
4. 数据同步及版本控制;
5. 如何保证数据安全。
听众受益:
1. 了解分布式文件存储架构;
2. 如何保证数据的安全;
3. 解决Redis等存储系统中大内存的缺陷。
陈敏敏 苏宁云商

陈敏敏,苏宁云商大数据中心技术总监,主要负责智能推荐、数据仓库和数据应用等部门的研发团队,并负责建设支撑供应链、物流、财务、运营等的统一数据平台。成电本科,上交硕士,《Storm 技术内幕与大数据实践》一书作者(人民邮电出版社、出口台湾),中关村大数据产业联盟专委会委员,2012年牵头成立三星电子研究院上海分部技术委员会(把关 Code Review 和技术架构),后在1号店分别任资深开发经理、精准化部门总架构师,目前主要关注推荐系统、应用架构、数据平台、OLAP等相关技术。
程浩 Intel

英特尔软件与服务部门大数据研发经理 程浩
个人简介: Intel亚太研发中心Spark团队研发经理,Apache Spark活跃开发者,致力于Apache Spark框架在Intel平台架构上的性能分析与优化。
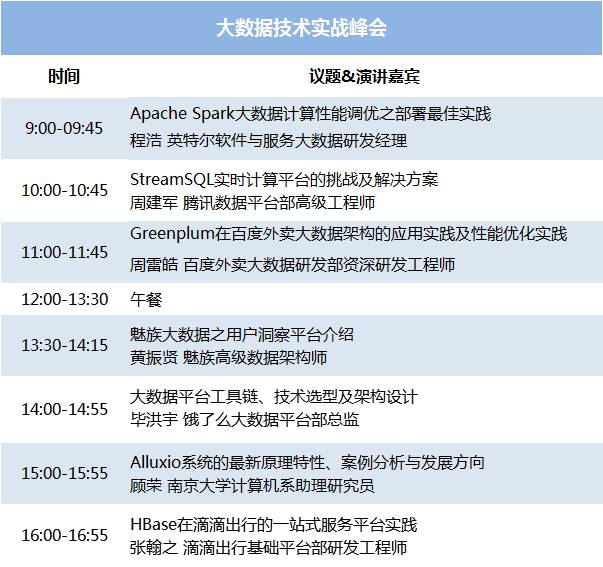
演讲主题:《Apache Spark大数据计算性能调优之部署最佳实践》
演讲简介:性能调优在Spark大数据应用中一直是大家普遍关心的话题。本次分享将主要探讨以下内容:
1. 如何收集硬件利用率来分析Spark应用程序性能瓶颈,从而进行有效调优?
2. 新硬件采购时,怎样的硬件配置对Spark应用可以有最佳的效能或者最好的性价比?
3. 通过展示不同特性的典型Spark应用的性能分析和调优手段,揭示如何释放硬件性能,监控硬件性能发挥,并在此基础上,测试不同硬件配置诸如内存、网络、磁盘、CPU选型,对于Spark大数据应用程序性能的影响,指导运维人员决策购买或者升级新的硬件零部件。
听众受益:针对硬件性能监控来调优Spark应用程序性能,并揭示Spark应用的最高性价比环境部署最佳实践。
周建军 腾讯

腾讯数据平台部高级工程师 周建军
个人简介: 2015年加入腾讯,供职于TEG数据平台部,主要负责StreamingSQL及实时计算平台的相关工作。在加入腾讯前曾供职于京东商城、聚美优品,有多年的大数据相关工作经验,尤其擅长分布式存储、HBase、实时数据采集等领域。
演讲主题:《StreamSQL实时计算平台的挑战及解决方案》
演讲简介: StreamSQL是一个通过SQL描述实时计算业务需求并将其转换成实时计算任务的开发平台。相对于传统实时计算平台Storm,StreamSQL内建丰富的字符串处理、时间、统计、复杂数据结果处理等各类计算函数,除了支持标准SQL之外还根据流式数据特点新增窗口统计特性,具有强大的统计计算能力。StreamSQL解决了传统Storm原生API使用复杂、上手难度高的问题,减少了用户对复杂实时计算框架和编程语言的学习成本,让用户具有更加良好的流式开发体验。
听众受益:
1. 深入了解StreamSQL实时计算平台;
2. 理解StreamSQL的设计目标并从中获得启发:让用户通过通用的SQL查询语言完成实时计算需求,减少用户对复杂实时计算框架及编程语言的学习成本,提高实时计算任务的开发效率。
周雷皓 百度外卖

百度外卖大数据平台负责人 周雷皓
个人简介:百度外卖资深研发工程师,负责百度外卖的大数据平台,致力于大数据引擎的研究和大数据平台架构的设计和研发。
演讲主题:《Greenplum在百度外卖大数据架构的应用实践及性能优化实践》
演讲简介:
1. GPDB架构介绍;
2. GPDB在百度外卖大数据架构中的角色以及应用场景;
3. 在生产环境中如何对gpdb进行性能优化;
4. 平台化之路,自动化性能优化平台设计思路以及架构介绍。
听众受益:
1. 了解MPP原理以及GPDB的架构;
2. 大数据查询引擎优化经验分享。
黄振贤 魅族

魅族高级数据架构师 黄振贤
个人简介: 2016年加入魅族,主要负责数据应用平台的规划、架构设计和落地实现。
演讲主题:《魅族大数据之用户洞察平台架构设计和实践》
演讲简介:魅族DMP(用户洞察平台),通过对三方受众数据的汇聚、清洗、智能运算,构建了庞大的精准人群数据中心,提供丰富的用户画像数据以及实时的场景识别力。
对内:无缝对接各类业务平台的数据应用,如广告平台、PUSH推送、个性化推荐之间建立了数据通道,支持公司级的精准营销,消息及时送达服务等场景。
对外:完善对数据的管理及输出流程,以开放接口形式为全行业从业者提供标准的精准人群标签,帮助优化投放并提升营销效果。达到对受众的精准投放,释放数据真正价值。
本次分享将介绍用户洞察平台所采用的架构,探讨其间遇到的技术难点和解决过程,回顾目前架构的不足之处以及将来改进的方向。
听众受益:
1. 了解大数据时代下的用户洞察,用户画像、精准营销;
2. 了解族用户洞察平台的架构设计和实践。
毕洪宇 饿了么

饿了么大数据平台部总监 毕洪宇
个人简介:曾在eBay,PPTV任职DBA。2012年加入唯品会,依次经历从0到1参与数据库基础建设、大数据基础平台和实时计算平台的工作;2016年加入饿了么负责大数据基础架构,主要负责数据平台工具链及数据仓库。
演讲主题:《大数据平台工具链、技术选型及架构设计》
演讲简介:随着接入需求方越来越多样化,对大数据的数据使用、数据存储与计算的需求也越来越多样化,业务的飞速发展及集群的规模急速扩大。如何在这样的场景下通过有限的资源来构建大数据平台、稳定支撑住业务的发展是一个不小的挑战。本次分享主要谈一谈从数据平台工具链、技术选型及架构设计出发的一些个人经验。
听众受益:
1. 了解如何在效率与规范、隔离和共享间平衡;
2. 学习与之相应的技术选型和架构设计;
3. 借由饿了么在业务快速发展过程中构建大数据平台从0到N的经验获得启发。
顾荣 南京大学

南京大学计算机系助理研究员 顾荣
个人简介:博士毕业于南京大学计算机系,Alluxio PMC成员。参与完成了Alluxio社区很多工作,包括性能测试框架Alluxio-Perf、Alluxio缓存策略优化、Alluxio与Hadoop生态系统多个组件的整合等。已经以一作身份在分布式并行计算领域一流期刊/会议上发表论文10篇等,并且参与编写书籍《深入理解大数据》。同时是南京大数据技术Meetup组织人,多次在国内外知名技术大会上演讲。曾在Microsoft Research、Intel、Baidu、星环科技从事大数据系统实习工作。
演讲主题:《Alluxio系统的最新原理特性、案例分析与发展方向》
演讲简介: Alluxio是一个开源内存级分布式大数据虚拟存储系统。在三年多的时间里,Alluxio开源社区已有来自全世界近500名的贡献者,成为大数据领域内历史上成长最快的项目之一。Alluxio系统已经部署在包括百度,巴克莱银行,华泰证券,英特尔,华为和去哪儿网等许多公司当中。在其中一些生产环境中,Alluxio已经行了一年多,管理数据PB级别的数据。Alluxio项目最新几个版本极大提升了系统性能,Scalability和用户体验,并增加了一系列新功能,包括统一命名空间、REST API等更加方便用户使用Alluxio。Alluxio未来将让更多用户人群可以使用Alluxio,着重提高安全性支持,支持新语言binding,以及进一步增加稳定性和对资源有效使用。此外,还会探索新的API,让应用程序能够更有效地访问数据。
听众受益:
1. 了解Alluxio项目最新版的新特性;
2. 学习Alluxio系统合适的应用场景与性能调优;
3. 交流Alluxio项目的发展方向。
张翰之 滴滴出行

滴滴出行基础平台部研发工程师 张翰之
个人简介:就职于滴滴出行基础平台部,负责HBase、Spark相关开发。
演讲主题:《HBase在滴滴出行的一站式服务平台实践》
演讲简介:面对企业的快速发展,每天几百亿业务访问、数据的疯狂增长和多租户场景下,到底企业该如何面对HBase集群规模不断扩展、集群管理、资源隔离、风险管理、服务保障、成本账单、业务监控及集群运维所带来的问题。
听众受益:
1. 使用哪些技术保障HBase稳定的服务;
2. 在多租户的背景下如何打造HBase一站式服务平台。
一站式干货强势来袭,热门话题一网打尽,更多精彩尽在SDCC 2017·深圳站。技术长路,道法万千,我们已经备下了技术华宴,带上你的“想法”,带上你的“求索之心”——创新之都一行,期待与你相约。

六折售票进入倒计时最后一天,欲购从速,详情点击「阅读原文」。










