雷锋网AI掘金志消息,近日,第四届岭南眼科论坛暨第二届全国眼科人工智能大会在广州举办。
大会以“Eye+AI”为主题,由广东省医师协会眼科分会、中国医药教育协会智能医学专委全国智能眼科学组主办,中山大学中山眼科中心、广东省医师协会眼科医师分会青年委员会、广东省眼科诊断与治疗创新工程技术研究中心承办。
本次大会设置了近80个主题演讲,与人工智能相关的主题有“AI技术与眼科实践”、“Eye+AI”、“眼科AI技术应用”,涉及青光眼、白内障、角膜病、糖尿病视网膜病变等多个关注度较高的病种。
目前,南方科技大学的唐晓颖教授与中山大学中山眼科中心的袁进教授进行合作,共同开发面向眼科的AI诊疗系统,系统的数据主要来自中山大学中山眼科中心,研究项目关注的病变主要有三类;
出血、渗出以及微动脉瘤。
病变检测从本质上而言仍然属于目标检测领域,而目标检测不能绕开的一个话题就是深度学习技术。
唐晓颖表示,对于医学的任务而言,最重要的因素就是Big Data,而且是Big Good Data,数据的质量控制是非常重要的,医生在其中发挥重要作用。
而手工标注的方式又会耗费医生大量时间,并且存在漏标和误标的问题。
因此,团队的一个重要工作就是研究用自动化的方法对不精准的标注进行校正。
研究中最重要的一部分是如何模拟生成粗略标注数据。
唐晓颖说到,由于IDRiD 数据集是像素级别的分割,所以对于任何一个病变,首先得到可以包含病变的最小长方形作为标注金标准,然后将标注金标准的长和宽随机扩大10%-50%,并在始终包含病灶的基础上做随机的平移,由此生成模拟的粗略标注数据集。
最后,在一种相对“粗糙”的标注方法下,团队生成了6164份训练集以及1436份数据集,回归网络模型训练后评估指标IoU达到0.8615。
“将训练好的标注回归网络运用于粗略标注数据集,我们可以去生成一个标注更加精准的数据集。
”
以下为唐晓颖教授的演讲内容,AI掘金志做了不改变原意的编辑
唐晓颖:
糖尿病视网膜病(Diabetic retinopathy ,DR)是全世界范围内首要的致盲因素。
检测和诊断DR主要用到的检查方式是数字彩色眼底摄像。
在我国需要被筛查和检查的眼底图像是非常巨大的,一方面是因为我们的病人数量非常多,另一方面专业的医生数量相对是比较少的。

回到我演讲报告的主题,我们为什么想要做一个眼底病变自动筛查工具?
首先,因为DR的症状表现为眼底的病变,包括微动脉瘤和出血;
其次,DR的严重程度可以根据这些病变的位置,还有病变的数量去做一个判别,像我们下图里展示的这样。

然而对于一些微小的病变,像微动脉瘤,即使一名资深医生来鉴别,可能都特别容易忽视。
在这种情况下,如果我们利用一些自动检测的算法,是否会达到一些比较好的效果?
这是我们所研究方向的研究背景。
病变检测从本质上而言仍然属于目标检测领域,谈到目标检测我们不能绕开的一个话题—深度学习技术(Deep Learning )。
最近几年随着计算机视觉的发展,深度学习的研究如火如荼,在计算机视觉的很多应用方向得到了非常成功的推广。
我们举三个简单的例子,一是行为识别,二是物体追踪,三是和我们更加相关的生物信号的检测,如虹膜识别。
在这些目标检测的任务中,深度学习其实都做到了非常好的应用。
在我个人看来,深度学习有三个主要的要素。
第一个是大数据(Big Data),第二个是高性能的计算机配置,第三个是如何去设计更加高级的深度学习模型。

对于医学的任务而言,我认为最重要的因素就是Big Data,而且是Big Good Data,像刚才杨院长所说,数据的质量控制是非常重要的。
但是非常遗憾,在医学任务里面,特别是涉及到病变分割,要获得高质量的数据其实是非常难,所以研究者们一直在强调医学数据难以获取,非常宝贵。
以眼底病变的检测任务为例,如果我们想去做像素级别的分割,就是把眼底图像中每一个有病变的像素都标注出来。
对于很多医生来说,将眼底病变手工标注出来是非常耗时的。
我们与中山眼科中心医生团队讨论过,对于这样的一张2D图像,医生如果想去做像素级的标注,手动的分割出来,可能需要花至少六个小时。
我们既需要这种高质量的数据,又需要数据量比较大,这个是很难同时去满足的。
我们的研究项目关注的病变主要是有三类,第一个是出血,第二个是渗出,第三个是微动脉瘤。
所以我们采用了一个折中的方案。
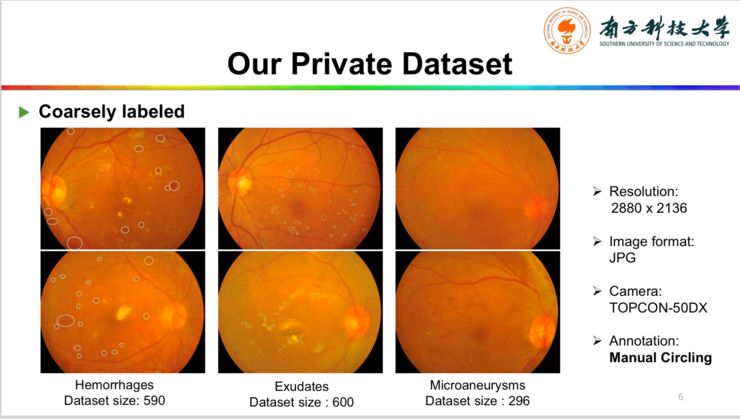
我们让医生用图中这种圆圈尽量去把病变的区域框出来。
相对于像素级标注来说,它要节约大概六倍的时间。
在我们的项目中医生以这种方式手动地将病变画出来,比像素级别标注要轻松。
我们收集了590张眼底出血病变的数据集,600张渗出病变数据集,296张微动脉瘤数据集。
这种标注方式相对比较粗糙,我们把它称之为coarse annotation。
Coarse annotation会带来一些问题。
首先是这种画圈方式不是非常精准,我们也去看了很多张图像,发现实际病变比勾画的bounding box 更小,所以它是比较粗糙的标注。
比如说图中的出血灶,还有下面这个图里的微动脉瘤,即使达不到像素级别的分割,标注框也需要改进。

第二个问题是我们发现医生在标注的时候,即使是这样比较粗略的一个标注方式,仍然会有漏标的情况存在,当然这也是在所有的手动标注工作里面都不可避免的一个问题。
比如下面图里面,我们会发现有一些出血和渗出灶被医生漏标了。

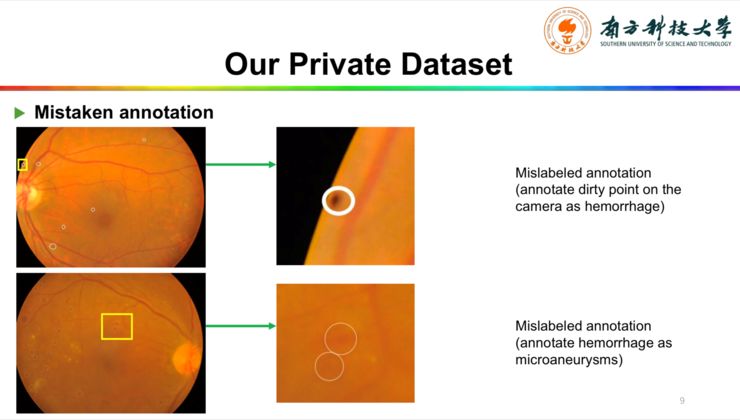
第三个问题是有一些错误的标注,比如第一个图里面,医生把这一块用黄色框标注出来,认为它是出血,其实是摄像时候的伪影。
第二个图是医生把出血误判为微动脉瘤。
以上是三类在医生手工标注工作中可能存在的问题,最好的办法是让不同的医生去标注和检查,最后达成一致。
但这样仍然是非常耗时的,也违背了我们的初衷。





