AI科技评论注:
本文作者为深度学习平台MxNet的作者李沐,文章由AI科技评论整理自作者的机器学习网站“动手学深度学习”。在这个网站中,李沐介绍了他做这个项目的初衷:
两年前我们开始了MXNet这个项目,有一件事情一直困扰我们:每当MXNet发布新特性的时候,总会收到“做啥新东西,赶紧去更新文档”的留言。我们曾一度都很费解,文档明明很多啊,比我们以前所有做的项目都好。而且你看隔壁家轮子,都没文档,大家照样也不是用的很嗨。
后来有一天,Zack问了这样一个问题:假设回到你刚开始学机器学习的时候,那么你需要什么样的文档?
为此,李沐决定:
我们想开设一些系列课程,从深度学习入门到最新最前沿的算法,从0开始通过交互式的代码来讲解每个算法和概念。
而本文也正是这一系列的开篇介绍,向初学者介绍了机器学习的背景知识,并希望借此吸引更多的初学者进入到机器学习的殿堂中来。
本文原地址:
http://zh.gluon.ai/introduction.html
以下为全文:
————————————————————
本书作者跟广大程序员一样,在开始写作前需要去来一杯咖啡。我们跳进车准备出发,Alex掏出他的安卓喊一声“OK Google”唤醒语言助手,Mu操着他的中式英语命令到“去蓝瓶咖啡店”。手机这时马上显示出识别的命令,并且知道我们需要导航。接着它调出地图应用并给出数条路线方案,每条方案边上会有预估的到达时间并自动选择最快的线路。
好吧,这是一个虚构的例子,因为我们一般在办公室喝自己的手磨咖啡。但这个例子展示了在短短几秒钟里,我们跟数个机器学习模型进行了交互。
如果你从来没有使用过机器学习,你会想,这个不就是编程吗?或者,到底机器学习是什么?首先,我们确实是使用编程语言来实现机器学习模型,我们跟计算机其他领域一样,使用同样的编程语言和硬件。但不是每个程序都用了机器学习。对于第二个问题,精确定义机器学习就像定义什么是数学一样难,但我们试图在这章提供一些直观的解释。
一个例子
我们日常交互的大部分计算机程序可以使用最基本的命令来实现。当你把一个商品加进购物车时,你触发了电商的电子商务程序来把一个商品ID和你的用户ID插入到一个叫做购物车的数据库表格中。你可以在没有见到任何真正客户前来用最基本的程序指令来实现这个功能。如果你发现你可以这么做,那么你就不应该使用机器学习。
对于机器学习科学家来说,幸运的是大部分应用没有那么容易。回到前面那个例子,想象下如何写一个程序来回应唤醒词例如“Okay, Google”,“Siri”,和“Alexa”。如果你在一个只有你和代码编辑器的房间里写这个程序,你该怎么办?你可能会想像下面的程序:

但实际上你能拿到的只是麦克风里采集到的原始语音信号,可能是每秒44,000个样本点。那么需要些什么样的规则才能把这些样本点转成一个字符串呢?或者简单点,判断这些信号里是不是就是说了唤醒词。
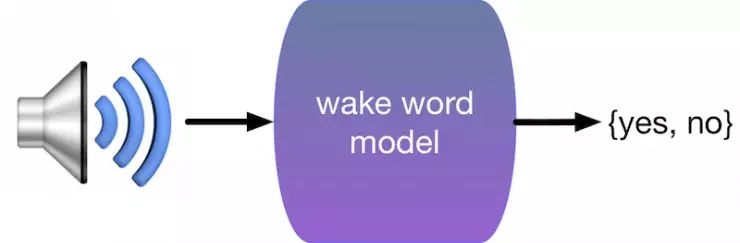
如果你被这个问题困住了,不用担心。这就是我们为什么要机器学习。
虽然我们不知道怎么告诉机器去把语音信号转成对应的字符串,但我们自己可以。我们可以收集一个巨大的
数据集
里包含了大量语音信号,以及每个语音型号是不是对应我们要的唤醒词。在机器学习里,我们不直接设计一个系统去辨别唤醒词,而是写一个灵活的程序,它的行为可以根据在读取数据集的时候改变。所以我们不是去直接写一个唤醒词辨别器,而是一个程序,当提供一个巨大的有标注的数据集的时候它能辨别唤醒词。你可以认为这种方式是
利用数据编程
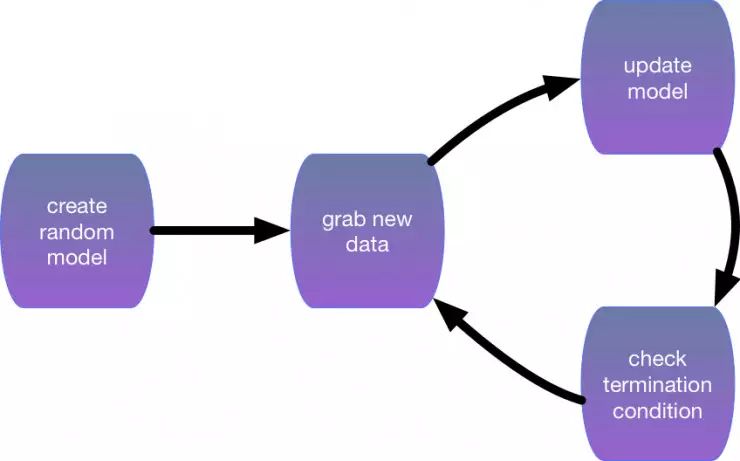
。换言之,我们需要用数据训练机器学习模型,其过程通常如下:
初始化一个几乎什么也不能做的模型;
抓一些有标注的数据集(例如音频段落及其是否为唤醒词的标注);
修改模型使得它在抓取的数据集上能够更准确执行任务(例如使得它在判断这些抓取的音频段落是否为唤醒词上判断更准确);
重复以上步骤2和3,直到模型看起来不错。
眼花缭乱的机器学习应用
机器学习背后的核心思想是,设计程序使得它可以在执行的时候提升它在某任务上的能力,而不是有着固定行为的程序。机器学习包括多种问题的定义,提供很多不同的算法,能解决不同领域的各种问题。我们之前讲到的是一个讲
监督学习
应用到语言识别的例子。
正因为机器学习提供多种工具可以利用数据来解决简单规则不能或者难以解决的问题,它被广泛应用在了搜索引擎、无人驾驶、机器翻译、医疗诊断、垃圾邮件过滤、玩游戏、人脸识别、数据匹配、信用评级和给图片加滤镜等任务中。
虽然这些问题各式各样,但他们有着共同的模式从而可以被机器学习模型解决。最常见的描述这些问题的方法是通过数学,但不像其他机器学习和神经网络的书那样,我们会主要关注真实数据和代码。下面我们来看点数据和代码。
用代码编程和用数据编程
这个例子灵感来自 Joel Grus 的一次 应聘面试. 面试官让他写个程序来玩Fizz Buzz. 这是一个小孩子游戏。玩家从1数到100,如果数字被3整除,那么喊’fizz’,如果被5整除就喊’buzz’,如果两个都满足就喊’fizzbuzz’,不然就直接说数字。这个游戏玩起来就像是:
1 2 fizz 4 buzz fizz 7 8 fizz buzz 11 fizz 13 14 fizzbuzz 16 …
传统的实现是这样的:
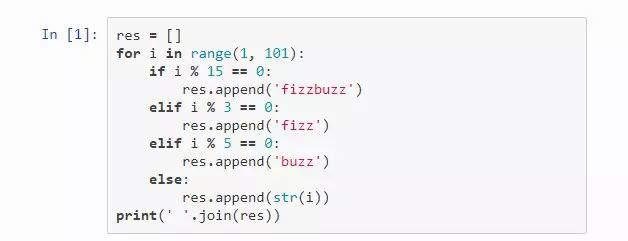
1 2 fizz 4 buzz fizz 7 8 fizz buzz 11 fizz 13 14 fizzbuzz 16 17 fizz 19 buzz fizz 22 23 fizz buzz 26 fizz 28 29 fizzbuzz 31 32 fizz 34 buzz fizz 37 38 fizz buzz 41 fizz 43 44 fizzbuzz 46 47 fizz 49 buzz fizz 52 53 fizz buzz 56 fizz 58 59 fizzbuzz 61 62 fizz 64 buzz fizz 67 68 fizz buzz 71 fizz 73 74 fizzbuzz 76 77 fizz 79 buzz fizz 82 83 fizz buzz 86 fizz 88 89 fizzbuzz 91 92 fizz 94 buzz fizz 97 98 fizz buzz
对于经验丰富的程序员来说这个太不够一颗赛艇了。所以Joel尝试用机器学习来实现这个。为了让程序能学,他需要准备下面这个数据集:
-
数据 X [1, 2, 3, 4, ...] 和标注Y ['fizz', 'buzz', 'fizzbuzz', identity]
-
训练数据,也就是系统输入输出的实例。例如 [(2, 2), (6, fizz), (15, fizzbuzz), (23, 23), (40, buzz)]
-
从输入数据中抽取的特征,例如 x -> [(x % 3), (x % 5), (x % 15)].
有了这些,Jeol利用TensorFlow写了一个分类器。对于不按常理出牌的Jeol,面试官一脸黑线。而且这个分类器不是总是对的。
显然,用原子弹杀鸡了。为什么不直接写几行简单而且保证结果正确的Python代码呢?当然,这里有很多一个简单Python脚本不能分类的例子,即使简单的3岁小孩解决起来毫无压力。
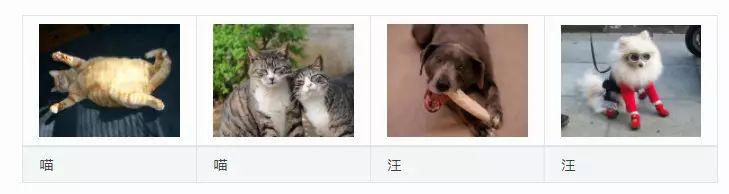
幸运的是,这个正是机器学习的用武之地。我们通过提供大量的含有猫和狗的图片来编程一个猫狗检测器,一般来说它就是一个函数,它会输出一个大的正数如果图片里面是猫,一个大的负数如果是狗,如果不确信就输出一个0附近的。当然,这是机器学习能做的最简单例子。
机器学习最简要素
成功的机器学习有四个要素:数据、转换数据的模型、衡量模型好坏的损失函数和一个调整模型权重来最小化损失函数的算法。
-
数据。
越多越好。事实上,数据是深度学习复兴的核心,因为复杂的非线性模型比其他机器学习需要更多的数据。数据的例子包括
-
模型。
通常数据和我们最终想要的相差很远,例如我们想知道照片中的人是不是在高兴,所以我们需要把一千万像素变成一个高兴度的概率值。通常我们需要在数据上应用数个非线性函数(例如神经网络)
-
损失函数
。我们需要对比模型的输出和真实值之间的误差。损失函数帮助我们决定2017年底亚马逊股票会不会价值1500美元。取决于我们想短线还是长线,这个函数可以很不一样。
-
训练
。通常一个模型里面有很多参数。我们通过最小化损失函数来学这些参数。不幸的是,即使我们做得很好也不能保证在新的没见过的数据上我们可以仍然做很好。





