The usage of Hadoop or another Big Data platform in order to generate insights for IT roles is a worthy alternative to consider.
使用Hadoop或其他大数据平台来监测IT部门的工作是值得考虑的方案
Big Data is the shiny new thing in the computing world with its promise to provide a way to deal with the ever-growing data production of the twenty-first century. More Big Data enthusiasts are emerging and more companies are adopting various Big Data platforms with the desire to come up with customer-centric solutions that will help them get ahead in the highly competitive market. Although it is most common to use Big Data solutions to derive analyses that target business revenues, we, being a bunch of developers at an IT firm, had a slightly different approach.Here’s a use case for the Hadoop ecosystem to monitor, analyze, and improve the software components of an IT firm.
大数据是计算机界意义重大的新领域,它提供了处理二十一世纪不断增长的海量数据的方法。越来越多的人成为大数据爱好者,越来越多的公司正在采用各种大数据平台来提供以客户为中心的商业方案,这将帮助他们在竞争激烈的市场中处于领先地位。尽管使用大数据方法进行针对业务收入的分析活动是最常见的,但作为IT公司的开发人员,我们的方法略有不同。
以下是Hadoop生态系统监控、分析和改进IT公司软件组件的例子:
The Software Infrastructure and Organization
软件基础设施组织
IBTech is the IT subsidiary of QNB Finansbank, one of the largest banks in Turkey. Banking transactions are logically divided into business modules such as customer, deposits, cash management, treasury, loans, etc. They are further divided physically into entry channels such as mobile, web, internet banking, call center, ATM, branches, etc.
As a result, our in-house developed CoreBanking ecosystem consists of a main back-end cluster, in which all the transactions take place and several front end applications working on different platforms and written with various frameworks. Our system has a service-oriented architecture, meaning that all the requests from clients and all the interaction among modules in the back-end are processed in form of services.
Every request enters the server as a service call and performs several inner service calls before returning a response. All the services are dynamically called and routed by an in-memory service bus.
IBTech是土耳其最大银行之一的QNB Finansbank的IT子公司。银行交易在逻辑上分为客户、存款、现金管理、资金、贷款等业务模块。它在物理上又进一步细分为移动、网络、网络银行、呼叫中心、ATM、分支机构等入口渠道。
因此,我们内部开发的核心银行生态系统由一个主要的后端集群组成,所有的交易都在这里进行,几个前端应用程序在不同的平台上工作并用各种框架编写。我们的系统具有面向服务的架构,这意味着客户端的所有请求以及后端模块之间的所有交互都以服务的形式被处理。
每个请求都作为一个服务进入服务器,并在返回响应之前执行多个内部服务调用。所有的服务都被内存中的服务总线动态调用和路由。
Our Motivation
我们的目的
Prior to the adoption of Hadoop, our existing monitoring tools lacked the ability to capture the custom detailed information about our system’s runtime. We had been using HP-BSM, which can monitor our service entry points and various external layers. This is a good starting point but fails when a more detailed or custom information is required for advanced analyses.
在采用Hadoop之前,当我们的监控工具无法捕获系统运行时客户的详细信息。我们一直在使用HP-BSM,它可以监控我们的服务入口点和各种外部层。这是一个很好的起点,但是当更高级的分析需要更详细或自定义的信息时HP-BSM就不行了。
A custom implementation of a monitoring and analysis tool using traditional approaches like storing the data in a relational database or a file system and sequentially reading and analyzing the data also proves highly infeasible — especially when the system in question processes over 200 million transactions per day, each of which trigger around 20 inner service calls and 15 SQL statements.
使用传统的监控分析工具(如将数据存储在关系数据库或文件系统中然后按顺序读取和分析数据)也是非常不可行的 – 特别是当系统每天要处理超过2亿次的交易,每个交易又将触发20个内部服务调用和15个SQL语句的时候。
Apart from the monitoring concerns, due to the dynamic nature of the service calls, we were unable to correctly and fully identify the possible routes and branches of service calls made from various endpoints or the module dependencies statically. Impact analysis would be done by examining the static code analysis generated by our existing tool, which required a great deal of human resources and yielded incomplete results, rendering the task practically impossible.
除了监控方面的考虑外,由于服务呼叫的动态性质,我们无法以静态的方式正确、全面地识别来源于各种端点或模块的分行服务电话。影响分析将通过检查我们现有工具生成的静态代码进行,这需要耗费大量人力而且产生的结果也不完整。因此,这些因素都使得这个任务几乎不可能完成。
As the IT teams employ various roles that work with different technologies and different business domains, and indifferent to each other, it was not easy for a treasury backend developer to realize the impact of their change in a certain service to a certain screen in the mobile banking application. Nor was it clear to a call center front-end developer what caused the performance degradation when they called a certain service on the push of a button on a certain page.
由于IT团队采用不同的技术、服务于不同的领域,并且各领域之间没有交流,这就使得后端开发人员很难意识到改变手机银行中的某项服务将会给其他部门带来怎样的影响。一个呼叫中心前端开发人员也不清楚当他们在特定页面上按下某个按钮调用某项服务时将会导致性能下降多少。
All of these concerns drove us to develop a custom monitoring and analysis tool for the IT audience using Hadoop and its supplementary components.
这些问题都促使我们使用Hadoop及其补充组件的IT受众开发定制监控和分析工具。
Implementation Details
We wrote a module we named Milena, which collects all the runtime data passing through our core banking servers and sends the data to Kafka. We configured Flume agents that read these streams from Kafka and persist them to HDFS. The data of the previous day is analyzed at the end of the day by Spark batches (source codes of some are here), and the results are indexed at ElasticSearch and visualized in our Kibana dashboards. We call this entire system Insights.
实施细节
我们写了一个名为Milena的模块,它收集了核心银行服务器运行时的所有数据,并将数据发送到Kafka。我们配置了从Kafka读取这些流的Flume代理,并将它们保留到HDFS中。前一天收集的数据将会在这一天的结尾用Spark(一些源代码在这里)进行批次分析,结果将在ElasticSearch中进行索引,并在Kibana仪表板中进行可视化。我们把这个整个系统称为Insights。
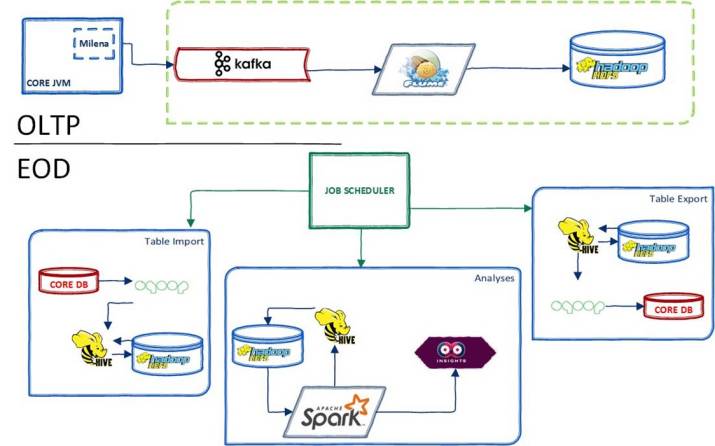
Our runtime data includes identifying information about the transaction, information about the client and user, executed services, executed SQL statements and affected tables, return codes, and start and finish timestamps corresponding to every executable unit.
Our OLTP servers process about 200 million transactions, producing 3.3 TB of data on a daily basis. An example of the raw data stored is:
我们的任务包括识别关于业务、客户端和用户的信息,执行服务,执行SQL语句和受影响的表,返回代码和对应于每个可执行单元的开始和结束的时间戳。我们的OLTP服务器每天处理大约2亿次交易并产生3.3 TB的数据。 存储原始数据的示例是:
{
“header”:{
“aygKodu”:“”,
“transactionState”:9,
“entranceChannelCode”:“999”,
“jvmID”:“999”,
“pageInstanceId”:“”,
“channelTrxName”:“IssueCreditTransaction”,
“processTime”:“075957”,
“processState”:9,
“channelHostProcessCode”:“0”,
“processDate”:“20170328”,
“correlationId”:“3e03bb4f-d175-44bc-904f-072b08116d4e”,
“channelCode”:“999”,
“userCode”:“XXXXXXXXX”,
“transactionID”:99999999999999999999999999,
“processType”:0,
“环境”:“XXXX”,
“sessionId”:“999999999999999999999999”,
“clientIp”:“999.999.999.999”
},
“服务”:[
{
“returnCode”:0,
“channelId”:“999”,
“parent”:0,
“poms”:[]
“endTime”:1490677197467,
“platformId”:“9”,
“serviceName”:“CREDIT_ISSUANCE_SERVICE”,
“startTime”:1490677197466,
“级”:1,
“环境”:“XXXX”,
“订单”:1,
“additionalInfos”:{},
“查询”:[],
“referenceData”:“CREDIT_ISSUANCE_OPERATION_PARAMETERS”
},
(...),
{
“returnCode”:0,
“channelId”:“999”,
“父母”:5,
“poms”:[]
“endTime”:1490677197491,
“platformId”:“9”,
“serviceName”:“GET_CUSTOMER_INFORMATION”,
“startTime”:1490677197491,
“级别”:6,
“环境”:“XXXX”,
“订单”:18,
“additionalInfos”:{},
“查询”:[
{
“tables”:“CUSTOMER_MAIN,CUSTOMER_EXT”,
“startTime”:1490677197491,
“订单”:1,
“queryName”:“SELECT_CUSTOMER_DATA”,
“isExecuted”:true,
“父母”:18,
“type”:1,
“endTime”:1490677197491
}
]
“referenceData”:“”
},
{
“returnCode”:0,
“channelId”:“999”,
“父母”:6,
“poms”:[]
“endTime”:1490677197467,
“platformId”:“9”,
“serviceName”:“GET_PRICING_POLICY”,
“startTime”:1490677197466,
“级别”:7,
“环境”:“XXXX”,
“订单”:7,
“additionalInfos”:{},
“查询”:[],
“referenceData”:“”
},
{
“returnCode”:0,
“channelId”:“999”,
“父母”:5,
“poms”:[]
“endTime”:1490677197468,
“platformId”:“9”,
“serviceName”:“CALCULATE_ISSUANCE_COMMISSIONS”,
“startTime”:1490677197466,
“级别”:6,
“环境”:“XXXX”,
“订单”:6,
“additionalInfos”:{},
“查询”:[],
“referenceData”:“”
},
(...),
{
“returnCode”:0,
“channelId”:“999”,
“父母”:18,
“poms”:[]
“endTime”:1490677197491,
“platformId”:“9”,
“serviceName”:“CREDIT_ISSUANCE_DOCUMENT_SERVICE”,
“startTime”:1490677197491,
“级别”:9,
“环境”:“XXXX”,
“订单”:19,
“additionalInfos”:{},
“查询”:[
{
“tables”:“ISSUANCE_MAIN,CUSTOMER_MAIN”,
“startTime”:1490677197491,
“订单”:1,
“queryName”:“SELECT_CUSTOMER_ISSUANCE_INFORMATION”,
“isExecuted”:true,
“父母”:19,
“type”:1,
“endTime”:1490677197491
}
]
“referenceData”:“”
},
(...)
]
}
We have various custom dashboards aimed to provide insights regarding the general performance of our core banking application, inter-module and intra-module dependencies, and usage statistics. We can effectively visualize the correlation between separate services. This enables us to foresee the impacts of a change or outage in a service on other services and applications. Here are some examples from some of the dashboards, with a hypothetical scenario involving multiple parties.
我们有各种定制仪表板,旨在提供有关银行核心应用程序、模块间和模块内依赖关系和使用记录的信息。 我们可以有效地可视化单独服务之间的相关性。 这使我们能够清楚知道某个服务中更改或中断将对其他服务和应用程序产生怎样的影响。 以下是仪表板的一些示例,其中包含多种应用场景:
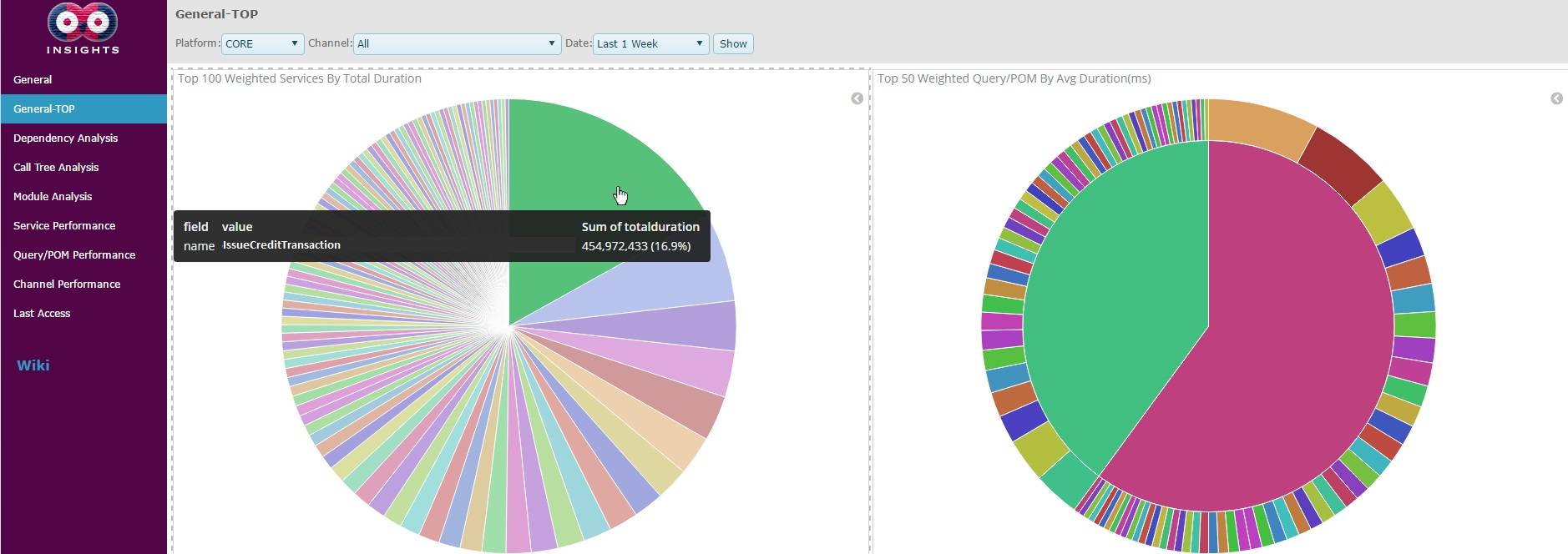
Suppose an IT monitoring specialist is set out to decrease the overall response time of the core banking system. They begin by examining the General-TOP dashboard of insights to see the most time-consuming transactions. They quickly observe that the credit issuance transaction, IssueCreditTransaction, of the mobile banking application lasts exceptionally long.
如果IT监控专家想要降低核心银行系统的整体响应时间。他们首先会检查General-TOP仪表板以了解最耗时的交易。观察后发现手机银行应用程序的信用发行交易(IssueCreditTransaction)过程耗时很长。
They inform the owner of the transaction, the front-end development team of mobile banking, about the discovery. A front-end developer from the team goes on to analyze this particular transaction in terms of its dependencies.They find out that 60% of the time spent in this transaction takes place in the
CREDIT_ISSUANCE_SERVICE
, which is dominated by the
CREDIT_ISSUANCE_DOCUMENT_SERVICE
. Hence, they easily pinpoint the low performance to the
CREDIT_ISSUANCE_DOCUMENT_SERVICE
:
他们会通知交易所有者(移动银行的前端开发团队)相关信息。 来自该团队的前端开发人员将继续根据服务之间的依赖关系分析耗时较长的原因。他们将会发现在此交易中60%的时间是花在CREDIT_ISSUANCE_SERVICE中的(由CREDIT_ISSUANCE_DOCUMENT_SERVICE主导)。 因此,他们会将工作重心放在CREDIT_ISSUANCE_DOCUMENT_SERVICE:
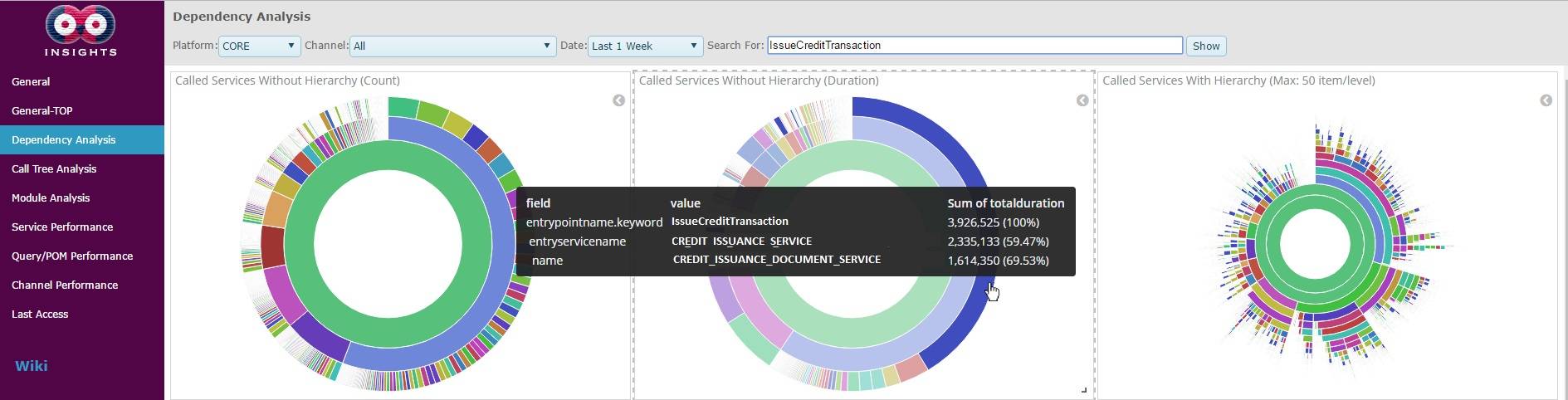
Figure 3: The dependency tree of the transaction in the above JSON. The left-most diagram shows the call counts of the inner services in this transaction. The diagram in the middle shows the total time elapsed in the inner services, the largest slices being the main burdens on the response time of this transaction. The right-most diagram shows the tree structure of this transaction, with all the possible paths from the root to leaves illustrated.
图3:上述JSON中的事务的依赖关系树。
最左侧的图表显示了此事务中内部服务的调用计数。中间的图显示了内部服务的总时间,最大的切片是此次交易响应时间最长的部分。 最右边的图表显示了该事务的树结构,其中包含从根到叶的所有可能的路径。
The mobile front-end development team asks the owners of the CREDIT_ISSUANCE_DOCUMENT_SERVICE, loans back-end development team to investigate the issue. A back-end developer starts examining the said service by searching it in the Service Performance dashboard. The analysis unveils two separate issues, a great deal of time is spent in the code, and the SELECT_CUSTOMER_ISSUANCE_INFORMATION query is costly.
移动前端开发团队要求CREDIT_ISSUANCE_DOCUMENT_SERVICE的所有者(贷款后端开发团队)检查此问题。 后端开发人员通过在服务性能仪表板中进行搜索来检查上述服务。 该分析揭示了两个问题:代码中花费了大量时间、SELECT_CUSTOMER_ISSUANCE_INFORMATION查询成本高昂。
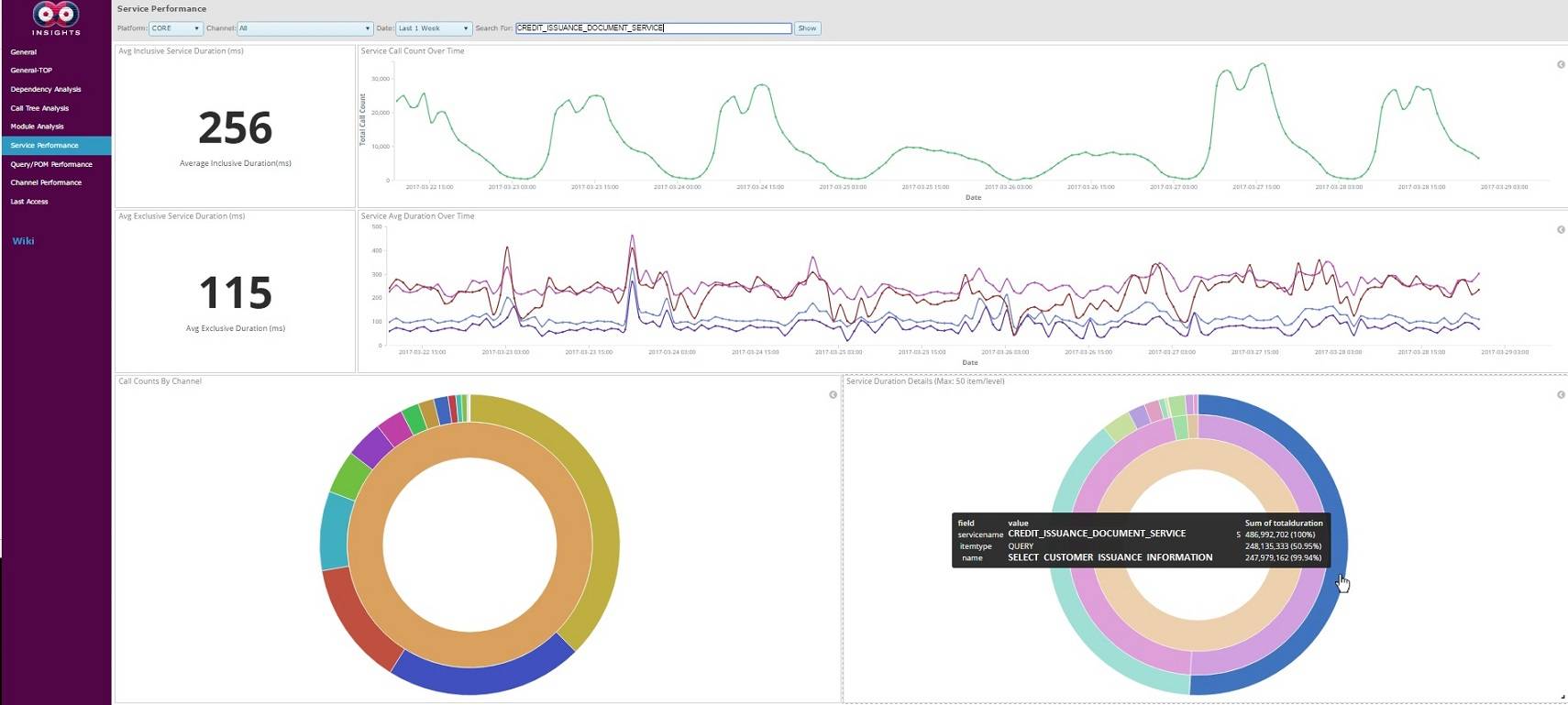
Figure 4: The detailed service analysis of CREDIT_ISSUANCE_DOCUMENT_SERVICE in the example JSON data. In the upper part, you can see the average durations of this particular service including or excluding the times elapsed in the inner services it calls. In the bottom right diagram, the layers in which this service passes time are shown.
For the performance problem of the code, the backend developer makes some changes for optimization, and requests for a test before deploying the code to production. Testers, given the changed service, try to list the test cases. They look through the call tree analysis to see which entry points lead to this service being called, through which path(s), and proceed to test these scenarios.
图4:在示例JSON数据中对CREDIT_ISSUANCE_DOCUMENT_SERVICE的详细分析。
在上半部分,您可以看到特定服务的平均持续时间,包括呼叫内部服务经过的时间。 在右下图中,显示了此服务通过时间的图层。
对于代码的性能问题,后端开发人员进行一些优化更改,并在将代码部署到生产之前进行测试。 测试人员考虑到更改的服务,尝试列出测试案例。 他们通过调用树分析来查看哪个入口点导致这个服务被调用,查看可以通过哪个路径来测试这些案例。
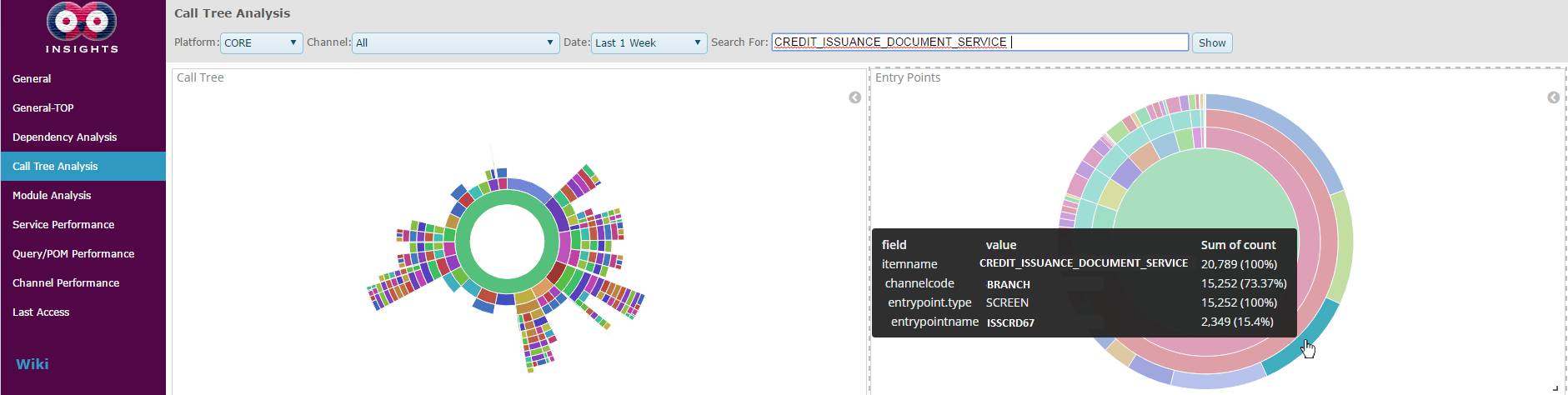
Figure 5: The call tree analysis of CREDIT_ISSUANCE_DOCUMENT_SERVICE. The diagram in the left illustrates all the possible paths leading to this service, including the one in the example JSON. The diagram on the right shows all the possible entry points and channels from which this service is reached.
For the performance problem of the query, a data architect reviews the SQL stamement, and reach the conclusion that a new index should be created on the table ISSUANCE_MAIN. They request the index creation for the database administrators to approve. Upon receiving the request to create a new index for the ISSUANCE_MAIN table, DBAs realize that the index creation would be costly, and likely to cause the table to be locked for a while.
They inform the process management specialists about the transactions that will be affected by the service blockage during the index creation, and plan the operation accordingly, by observing the call tree analysis of the table.
图5:CREDIT_ISSUANCE_DOCUMENT_SERVICE的调用树分析。
左图显示了导致此服务的所有可能路径,包括示例JSON中的路径。 右侧的图显示了达到此服务的所有可能的入口点和渠道。
关于查询性能方面的问题问题,数据架构师会回顾SQL 语句,然后发现应该在表ISSUANCE_MAIN上创建一个新的索引。 他们请求数据库管理员批准索引的创建。在接收到为ISSUANCE_MAIN表创建新索引的请求时,DBA发现索引创建将耗费很长时间,就可能将表锁定一段时间。它们通过进程管理专家通知在创建索引期间将受到服务阻塞影响的进程,并通过观察表的调用树分析来制定相应地计划。
Results
The first phase of the system was launched in production in October 2016 and continued to expand and improve upon customer feedback and demands. Roughly around January 2017, it had matured to its final state and has been in frequent use since then. Now that the project is live and stable, it has affected the project lifecycle considerably. The outcome appeals to a variety of roles from different backgrounds.
成果:
该系统的第一阶段于2016年10月投产,并根据客户的反馈和需求进行了扩大和改进。 大约在2017年1月左右该系统发展完善,并一直被频繁使用。 现在该系统保持活跃稳定,并大大影响了项目的生命周期。该系统的出现也吸引了不同背景的各种身份的人的参加。
Business analysts and application architects are now reviving the possible effects of a proposed change in the discovery phase and planning the change accordingly. Developers and testers are reviewing the affected components of a change, and making sure of the smooth integration with necessary development and testing.
业务分析师和应用架构师现在正在恢复系统发展阶段提出的变更可能带来的影响,并相应地规划变更。开发人员和测试人员正在审查受到变更影响的部分,并确保与必要的开发和测试的顺利整合。
The number of production errors resulting from poor or lack of impact analysis was reduced drastically after the project was put into use. Process management specialists are reviewing the results to see which specific transactions would be affected by the planned or unplanned outage of a certain feature and take measures accordingly.
该项目投入使用后,由于缺乏影响分析而导致的生产错误的案例急剧下降。 流程管理专家正在检查结果,以查看哪些具体交易将受到计划或计划外中断的影响,并采取相应措施。
Conclusion
It is vital for a modern technology company to explore Big Data options to analyze data with concrete business revenues in mind. However, it should not be neglected that once manual and trivial workloads are eliminated, the highly competent IT staff would be able to focus on more innovative aspects of their jobs.
现代科技公司必须探索使用大数据方法来分析具体业务收入数据。 然而,不容忽视的是,当手动和微不足道的工作量消除时,高素质的IT人员将能够专注于更多创新的工作。
In addition to this, the software infrastructure, being the gist of a business’s whole system at the lowest level, is the key component that allows or disallows the agility, performance, flexibility and competence of the system. That’s why improvements that are done right and to the point in the software infrastructure have the potential to yield greater revenues, which is possible by effective monitoring and analysis. Usage of Hadoop or another Big Data platform to generate insights for IT roles is a worthy alternative to consider.
除此之外,软件基础设施是最低层次的业务整体系统的要素,是决定系统的敏捷性、性能、灵活性和能力的关键部分。 这就是为什么在软件基础设施方面做出的正确改进有可能产生更大的收入(这可以通过有效的监测和分析来实现)。 使用Hadoop或其他大数据平台来监测IT部门的工作是值得考虑的方案。
本文为36大数据独家授权编译,作者Gizem Akman,编译LSQ,未经允许不得转载
End
为了让大家能有更多的好文章可以阅读,36大数据联合华章图书共同推出「祈文奖励计划」,该计划将奖励每个月对大数据行业贡献(翻译or投稿)最多的用户中选出最前面的10名小伙伴,统一送出华章图书邮递最新计算机图书一本。投稿邮箱:[email protected]
点击查看:你投稿,我送书,「祈文奖励计划」活动详情>>>
如果有人质疑大数据?不妨把这两个视频转给他
视频:大数据到底是什么 都说干大数据挣钱 1分钟告诉你都在干什么
人人都需要知道 关于大数据最常见的10个问题
从底层到应用,那些数据人的必备技能
如何高效地学好 R?
一个程序员怎样才算精通Python?
排名前50的开源Web爬虫用于数据挖掘










