
原文来源:medium
作者:Lazim Mohammed
「机器人圈」编译:BaymaxZ
 CoreML是2017年苹果WWDC发布的最令人兴奋的功能之一。它可用于将机器学习整合到应用程序中,并且全部脱机。
CoreML是2017年苹果WWDC发布的最令人兴奋的功能之一。它可用于将机器学习整合到应用程序中,并且全部脱机。
以下是来自苹果的官方机器学习文档:(https://developer.apple.com/machine-learning)
CoreML允许你将各种机器学习模型类型集成到你的应用程序中。除了支持30多种类型的广泛的深度学习外,它还支持诸如树集成、SVM(支持向量机)和广义线性模型之类的标准模型。由于它是建立在像Metal和Accelerate这样的低级技术之上的,所以Core ML无缝利用CPU和GPU,以提供最高的性能和效率。你可以在设备上运行机器学习模型,因此数据不需要离开要进行分析的设备。
当深入了解预测如何发生,在哪儿发生,你就会发现CoreML的重要性。到目前为止,所有人都习惯于将机器学习整合到应用程序中,预测过程则发生在托管服务器中。如果是对象识别应用程序,则必须从设备中捕获帧,将数据发送到预测引擎,等待图像完全上传到服务器,最后得到输出。 这种方法主要有两个问题——网络延迟和用户隐私。现在,所有这些处理都可以简单地发生在设备中,从而减少了这两个问题。
在coreML之前,架构是这样的

从零开始
我们可以尝试使用CoreML,并为此实现一个简单的设备上解决方案。
我将重点介绍iOS或Swift的基础知识。首先我们要做的是获得iOS 11设备和Xcode 9。如果你不熟悉机器学习,请在这里看一下简单介绍,或者你可以从这里获得高级别概述。
机器学习
该技术使计算机能够在没有明确编码问题解决方案的情况下学习。这里有两个过程——训练和预测。训练是我们给模型不同的输入集(和相应的输出)以便从模式中学习的过程。这个训练过的模型被传送了一个从之前没有看到的输入,从之前的观察中预测出来。
选择模型
所以我们要做的第一件事是为你的项目选择一个很好的模型。有许多预训练的模型可用于图像识别。或者你甚至可以训练自己的模型来获得更好的体验。
来自苹果机器学习的CoreML有很多很好的模型(下载网址https://developer.apple.com/machine-learning/), 或者如果你有自己的模型,可以使用Apple提供的CoreML工具将其转换为支持CoreML的模型(网址:https://pypi.python.org/pypi/coremltools)。我选择了苹果中提供的Inception V3库。
Inception v3——从一组1000个类别(如树木、动物、食物、车辆、人物等)中检测出图像中的主要物体。
创建iOS项目
你可以使用带有单视图控制器的swift创建一个基本的iOS项目,包括视频预览图层和标签。
从视频预览中获取帧
获取当前帧照例是一样的,我们已经知道了。这在这篇invasivecode的文章中有所解释。
使用Inception V3进行预测
在提供输入图像时,将我们的初始模型视为黑盒子,可以将你作为其知道的一组类别中的一个概率。
从Apple的门户下载模型,拖动它(Inceptionv3.mlmodel)到你的项目。你可以从Xcode中看到模型描述。

Xcode模型查看器显示的Inceptionv2.mlmodel
你可以看到该模型以299x299像素的图像作为输入,并给出输出:
图像最可能的类别
每个类别的概率列表
我们可以利用任何这些参数来确定类别。我使用的第一个是一个绳子,并直接打印在屏幕上。
你还可以看到,Xcode直接从mlmodel对象创建一个swift模型(Inceptionv3.swift)。你不必为此做任何额外的更改。
用法
我们可以利用Xcode生成的预测API,如下所示:
/**
Make a prediction using the convenience interface
- parameters:
- image: Input image to be classified as RGB image buffer, 299 pixels wide by 299 pixels high
- throws: an NSError object that describes the problem
- returns: the result of the prediction as Inceptionv3Output
*/
func prediction(image: CVPixelBuffer) throws -> Inceptionv3Output {
let input_ = Inceptionv3Input(image: image)
return try self.prediction(input: input_)
}
/// Model Prediction Output Type
class Inceptionv3Output : MLFeatureProvider {
/// Probability of each category as dictionary of strings to doubles
let classLabelProbs: [String : Double]
/// Most likely image category as string value
let classLabel: String
// Class has other APIs and properties.
// ...
}
预测则很简单:
var model = Inceptionv3()
let output = try? model.prediction(image: pixelBuffer)
let prediction = output?.classLabel ?? “I don’t know! ”
但它需要一个CVPixelBuffer的对象而不是UIImage进行预测,这是由hackingwithswift.com在“机器学习与远景”一节中精通这些的人介绍的,文章(https://www.hackingwithswift.com/whats-new-in-ios-11)。
我已经创建了UIImage类别,并将其与resize API一起进行提取。
extension UIImage {
func buffer() -> CVPixelBuffer? {
return UIImage.buffer(from: self)
}
static func buffer(from image: UIImage) -> CVPixelBuffer? {
// as explained in https://www.hackingwithswift.com/whats-new-in-ios-11
// ...
}
func resizeTo(_ size: CGSize) -> UIImage? {
UIGraphicsBeginImageContext(size)
draw(in: CGRect(x: 0, y: 0, width: size.width, height: size.height))
let image = UIGraphicsGetImageFromCurrentImageContext()
UIGraphicsEndImageContext()
return image
}
}
最后的架构
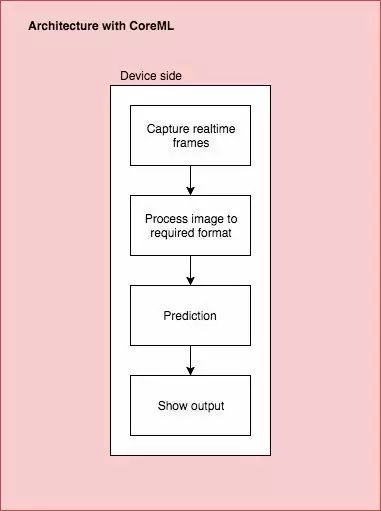
结果
该应用程序能够从几乎所有提供的输入中正确识别结果。




点击此处链接获取完整的代码资源。
回复「转载」获得授权,微信搜索「ROBO_AI」关注公众号
 欢迎加入
欢迎加入

中国人工智能产业创新联盟在京成立 近200家成员单位共推AI发展

关注“机器人圈”后不要忘记置顶哟
我们还在搜狐新闻、机器人圈官网、腾讯新闻、网易新闻、一点资讯、天天快报、今日头条、QQ公众号…
↓↓↓点击阅读原文查看中国人工智能产业创新联盟手册




