I implement Ross's work "Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks" to realize
real-time object detection, which focuses on image-level problem. Here, I extend it to video-level problem by treating
videos like a series of frames and also take the relation between each frame into account. Use a tracker to track the
video frame by frame and finally visualize the final result
Backgound
Object detection is an age-old question. Many application need the techniques of object detection, such as IoT,
self-driving car. So here we're gonna introduce the state-of-the-art: faster rcnn, achieves high performance and can be
used in real-time.
Region-based Convolutional Neural Network, aka R-CNN, is a visual object detection system that combines
bottom-up region proposals with features computed by a convolutional neural network.
R-CNN first computes the region proposal with techniques, such as selective search, and feeds the candidates to the
convolutional neural network to do the classification task. Here's the system flow of R-CNN:
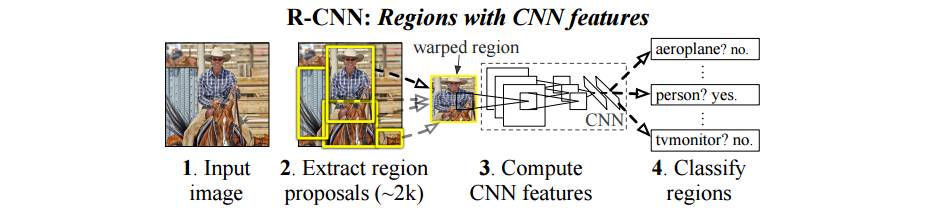
However, it can some notable disadvantages:
-
Training is a multi-stage pipeline.(three training stages)
-
Training is expensive in space. (due to the multi-stage training pipeline)
-
Object detection is slow. Detection with VGG16 takes 47s / image (on a GPU).
R-CNN is slow because it performs a ConvNet forward pass for each object proposal, without sharing computation. Many
works have been proposed to solve this problem, such as
spatial pyramid
pooling networks(SPPnets)
, whcih tries to avoid repeatedly computing the convolutional features.
Thus, R-CNN is not good enough for us in application uses though it provides bare enough performance.
"Fast" R-CNN is quite easy to understand by its word. It's quite fast, achieving 0.3s per image for detection when ignoring
the region proposal. Well, how does this magic works?
The most important factor is that it shares the computation. After the
region proposal, we'll get some bounding boxes. In the previous
alogrithm, they just directly feed the warped image to the CNN. That is,
if we have 2000 proposals, we have to do 2000 times
forward pass, which wasting lots of time. Actually, we can use the
relation between these proposals. Many proposals have overlap
with others, and these overlap part is fed into the CNN for many times.
Maybe we can just compute them for once.
Fast R-CNN utilizes this property well. Here's the illustration of how it really works:
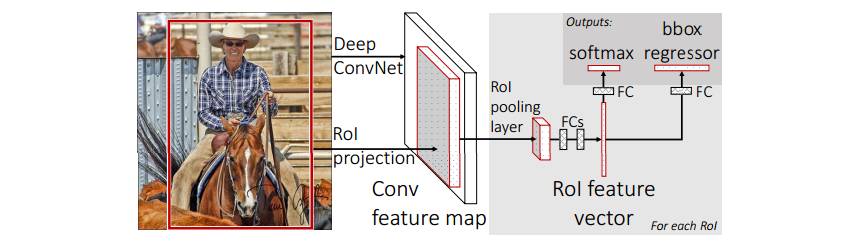
First, we'll feed the whole image into the ConvNet (to conv5). Then,
it's where the magic lies in: we know that convolutional
layer won't change the spatial relation between the adjacent pixels.
That is, the upmost pixel will still falls on the upmost
part of the feature map in conv5. Based on this, it's possible for us to
porject the coordinates in raw image to the corresponding
neuron in conv5! In this way, we can just compute the image through
ConvNet once. After getting the faeture for each bounnding box,
it will be fed into the RoI pooling layer, which is a special-case of
the spatial pyramid pooling layer. The rest work is similar
to the previous work.
The following figure is a more clear illustration of Fast R-CNN:
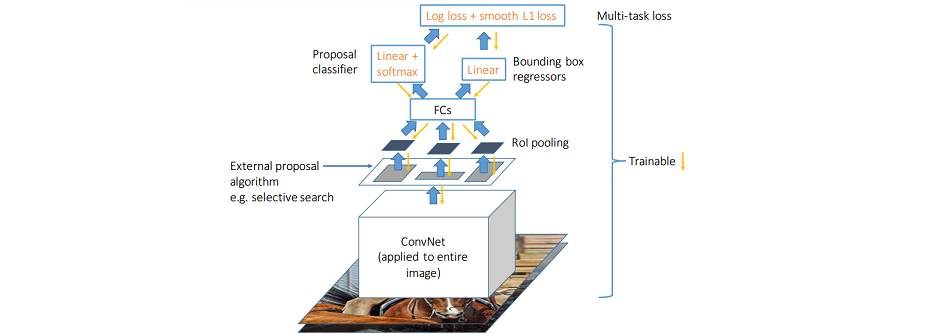
链接:
http://andrewliao11.github.io/object_detection/faster_rcnn/
代码链接:
https://github.com/andrewliao11/py-faster-rcnn-imagenet
原文链接:
http://weibo.com/1402400261/ECnDP0HMV?from=page_1005051402400261_profile&wvr=6&mod=weibotime&type=comment#_rnd1491045119362





