来源:Youtube
编译整理:胡祥杰 张易
【新智元导读】
在本次演讲中, Hinton讨论了用“capsule”作为下一代CNN的理由。
他解释了“标准”的卷积神经网络有什么问题?
结构的层次太少,只有神经元、神经网络层、整个神经网络。所以,
我们需要把每一层的神经元组合起来,形成一个组,并装到“舱”(capsule)中去,这样一来就能完成大量的内部计算,最终输出一个经过压缩的结果。
“舱”(capsule)的灵感来自大脑皮层中的微柱体(mini-column)。CNN的代表人物是Yann LeCun,所以这也可以看成是两位大神在深度学习观点上的一次正面交锋。


2017年8月17日,Hinton在加拿大多伦多菲尔兹研究所开讲,主题是《卷积神经网络有哪些问题》,这是加拿大新成立的“向量研究院”(Vector Institute)2017-2018机器学习的发展和应用课程的一部分。
2017年3月30日,
Vector Institute
宣布成立,Hinton是这一机构的首席科学顾问。发布会上Vector 方面表示将致力于人工智能的前沿研究,专注在机器学习和深度学习领域的变革性研究。该研究院将与学术机构、孵化器、加速器、初创企业以及大公司展开合作,推动加拿大人工智能的研究及商业化应用。
卷积神经网络
(Convolutional Neural Network,
CNN
)是一种
前馈神经网络
,它的人工神经元可以响应一部分覆盖范围内的周围单元,对于大型图像处理有出色表现。
卷积神经网络的集大成者是Yann LeCun,现Facebook 人工智能实验室的主管,它被业界誉为“卷积神经网络之父”。在本次演讲中,Hinton也多次提到了LeCun的观点,提到两人在学术上的不同观点。
在本次演讲中, Hinton讨论了用“capsule”作为下一代CNN的理由。
一个卷积神经网络(CNN)或者神经元只有一个输出AND,在处理两个输入向量时做得不好。一个“capsule”是一个多值描述符号,对应输入向量中的一个特征。
Hinton在开场白中说:“在中国,有超过1万名研究生在研究神经网络”,但是这里面有一个误区,他说:“神经网络与大脑的关系不大,它们虽然是受到大脑启发的,但是因为这是我们手动搭建的,大脑是一个完全不同的架构,并且更高效。”

“标准”的卷积神经网络有什么问题?
-
结构的层次太少:神经元、神经网络层、整个神经网络
-
我们需要把每一层的神经元组合起来,形成一个组,并装到“舱”(capsule)中去,这样一来就能完成大量的内部计算,最终输出一个经过压缩的结果。
“舱”(capsule)的灵感来自大脑皮层中的微柱体(mini-column)。

1. 被呈现的对象可能的分类;
2. 对象的大概状态,包括位置、朝向、大小、变形、体积和颜色等等。

“舱”可以完成同步过滤(filtering)
一个典型的“舱”从下一层的“舱”中接收多维的预测向量,并且寻找一个更紧致的预测群(cluster)。
如果找到了一个一个更紧致的预测群(cluster),它会输出:
-
一个高概率,即某一类型的实体存在在这个区间
-
群的引力中心,也就是实体的大概状态
这种方法在过滤噪音上做得非常好,因为高维度的一致性的发生并不是偶然。
它比一般的“神经元”表现得要好很多。
当下,LeCun和几乎所有人都在用的对象识别有什么问题?

当下用于对象识别的方法:
-
Convnets(卷积网)使用多层学习到的特征检测器。(这一点很好)
-
在卷积网中,特征的检测是局部的,每一种类型的检测器被复制到整个空间中。(这一点很好)
-
在卷积网中,层次越高,特征检测的空间领域变得越大。(这一点很好)
-
特征提取层与次抽样层交叉存取,将相同类型的相邻特征检测器的输出汇集到一起。(这是问题所在)

将复制的特征检测器的输出进行结合的动机
-
池化在每一层都会给予一个小量的转换变量
最活跃的特征检测器的精确位置会丢失
可能,这也是ok的,如果池化堆叠很多次或者如果特征对其他特征的相对位置进行编码的话
-
池化减少输往特征提取下一层的数量
这将让我们在下一层拥有更多的特征类型(更大的领域)

一个卷积网络中拥有什么类型的认知
深度卷积网络中最后一层的激活行为就是一个认知
感知包含了图像中许多物体的信息
但是,物体之间的关系是怎样的?关系的认知并没有经过训练
向一个深度循环神经网络的最初隐藏层的状态上加入上文提到的认知,并且训练RNN来生成字幕(不需要对卷积网络进行预训练)

对于池化(pooling),存在以上 4 点争论:
它无法解释为什么把固有坐标系分派给对象后,会有如此明显的效果。
我们想要的是 equivariance,不是 invariance。想要的是 Disentangling,而不是 discarding。
它不能利用能够完美处理图像中大量variance的自然线性流形。
我们需要route进入神经网络的输入的每一部分,好知道如何处理它。找到最好的 routing 相当于为图像做parsing。

关于争论1:
四面体Puzzle:关于坐标系能做什么的演示

反向四面体Puzzle

一些更多的心理学证据,显示了我们的视觉系统在抓住物体形状时,利用了坐标系。

关于争论2:Equivariance vs Invariance
-
卷积神经网络努力在让神经活动对视点上的小变化invariant,方法是通过在一个“池”内合并这些活动
—这个目标是错误的;
—它由这样一个事实驱动:最终的 label 需要 viewpoint-invariant
-
以equivariance为目标会更好:视点中的变化引发了神经活动中的相应变化
—在认知系统中,是 weights 编码了viewpoint-invariant knowledge,而不是神经活动。
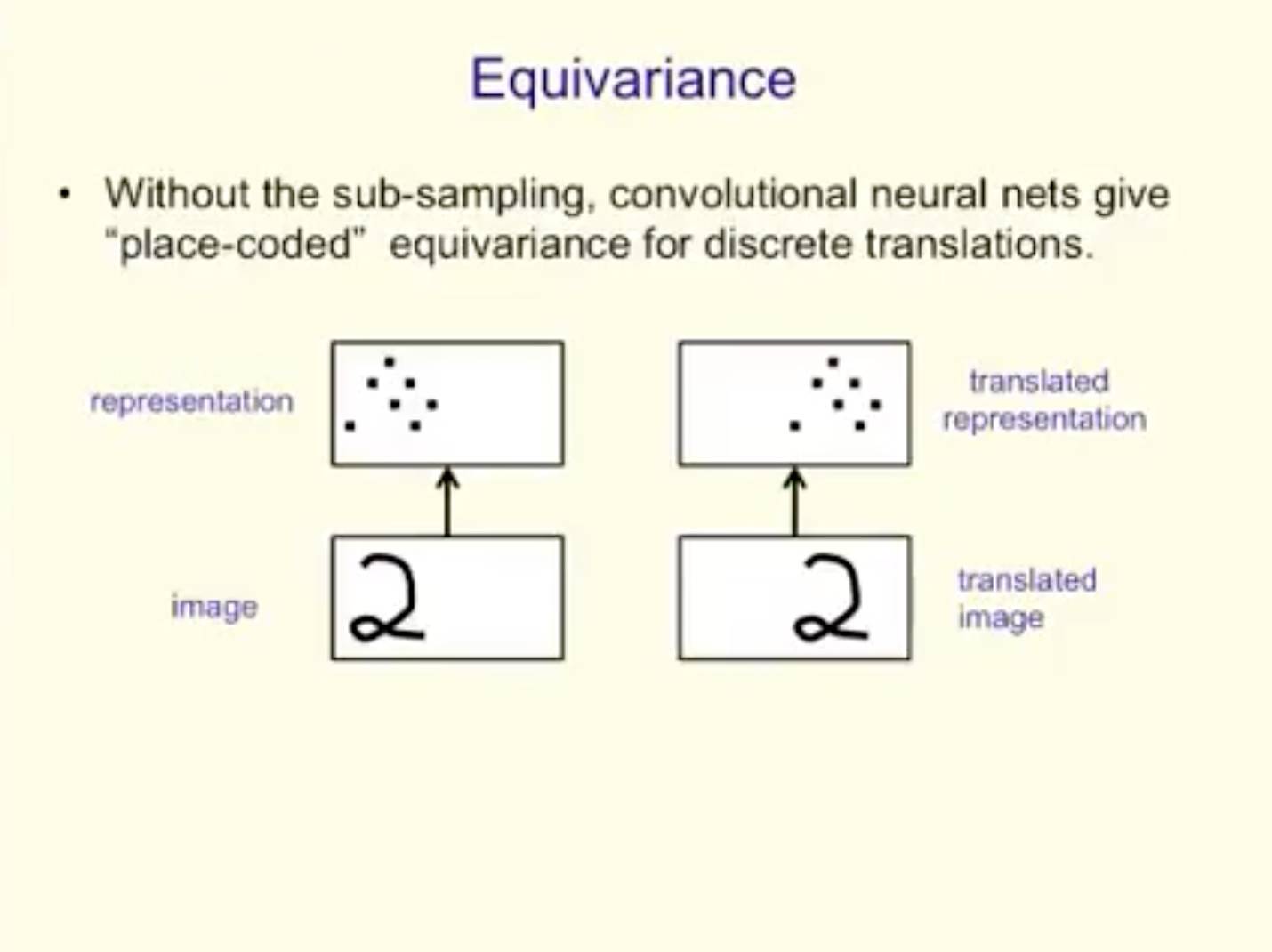
Equivariance
没有sub-sampling,卷积神经网络为discrete translations 给出了“place-coded” equivariance。

两类 equivariance
-
如果一个低级别部分移动到了一个非常不同的位置,它会被不同的capsule表征
—这是“place-coded” equivariance。
-
如果一个部分仅移动了很短的距离,它仍会被同样的capsule表征,但capsule的输出将会变化
—这是“rate-coded” equivariance。
-
更高级别的 capsules 有更大的domain,所以低级别的place-coded equivariance 转化为了高级别的 rate-coded equivariance。

关于争论3:推算形状识别到非常不同的视点

使用计算机图像使用的全局线性流形在视点上泛化
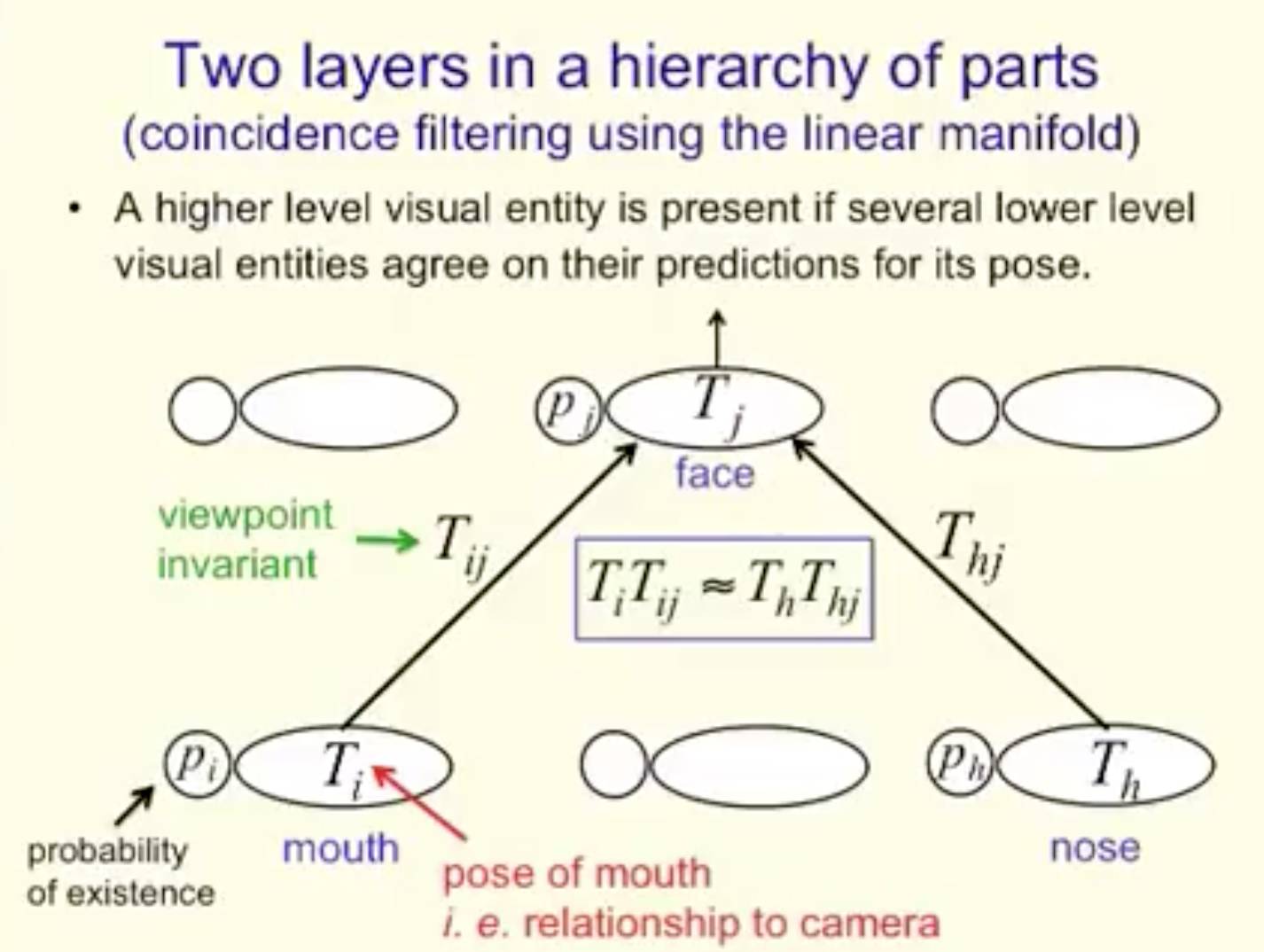
在部分层次中的两层(使用线性流形的coincidence filtering)

关于争论4:我们需要 route 图像中的信息,好让神经网络可以理解
【号外】
新智元正在进行新一轮招聘,
飞往智能宇宙的最美飞船,还有N个座位
点击阅读原文可查看职位详情,期待你的加入~






