R语言与Python的Pandas中具有非常丰富的数据聚合功能,今天就跟大家盘点一下这些函数的用法。
R语言:
-
aggregate
-
grouy_by+summarize
-
ddply
Python:
在R语言中,新建变量最为快捷的方式是通过transform(当然你可以选择使用自定义函数),该函数支持基于同一个数据框新建多个变量。
这里仍然使用经典的莺尾花数据集演示:
iris1
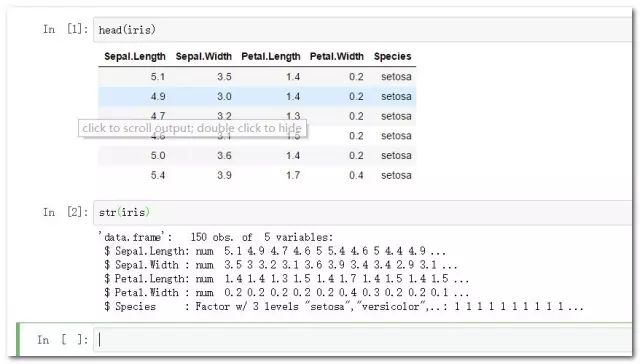
transform与mutate两个函数都是新建变量,但是前者仅能基于所提供的数据框内变量进行新建,而后者则可以直接在新建变量基础上进行操作。
(iris1
(iris1
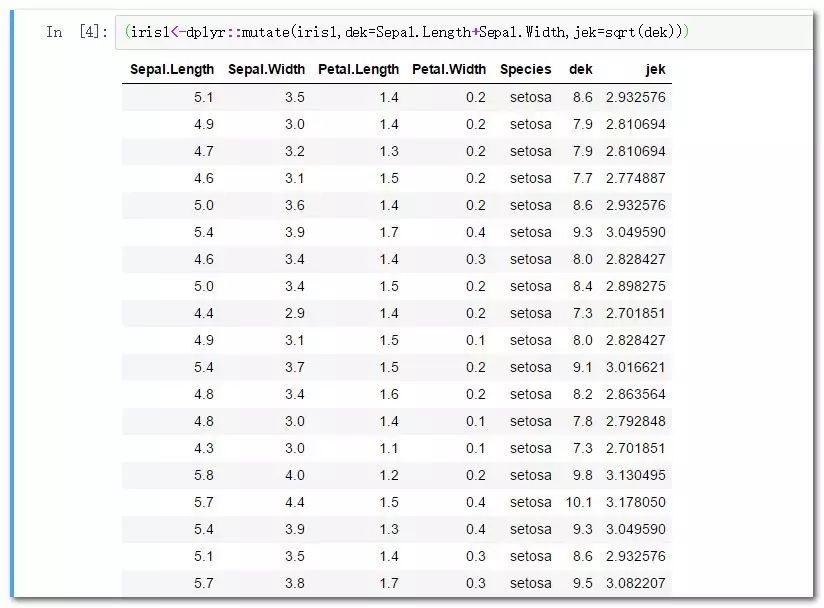
aggregate是专门用于分组聚合的函数:
aggregate(value~class,data,fun)
#表达式左侧是要聚合的目标度量,右侧是分组依据,紧接着是数据框名称,最后是聚合函数。
aggregate(Sepal.Length~Species,iris,mean)
aggregate(Sepal.Length~Species,iris,sum)
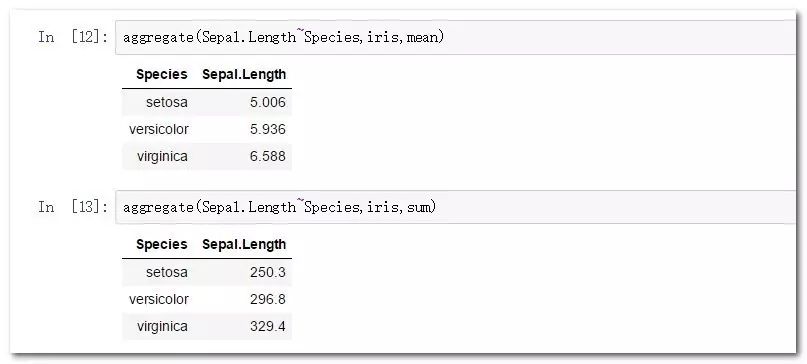
library(dplyr)
使用group_by函数结合summarize可以方便的完成分组聚合功能。
iris%>%group_by(Species)%>%summarize(means=mean(Sepal.Length))
iris%>%group_by(Species)%>%summarize(sums=sum(Sepal.Length))

R语言中的分组聚合如果使用矢量函数来进行操作,会大大提升其执行效率:
tapply(iris$Sepal.Length,iris$Species,mean)
tapply(iris$Sepal.Length,iris$Species,sum)
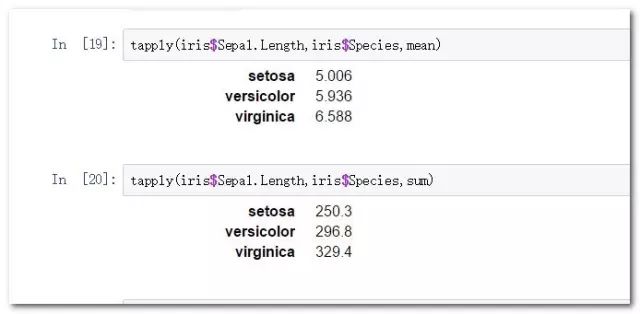
tapply(X, INDEX, FUN = NULL, …, simplify = TRUE)
tapply是一个快捷的分组聚合函数,其参数简单易懂,通过提供一个度量,一个分类别字段,一个聚合函数即可完成简答的数据聚合功能。
library(plyr)
ddply(iris,.(Species),summarize,means=mean(Sepal.Length))
ddply(iris,.(Species),summarize,means=sum(Sepal.Length))
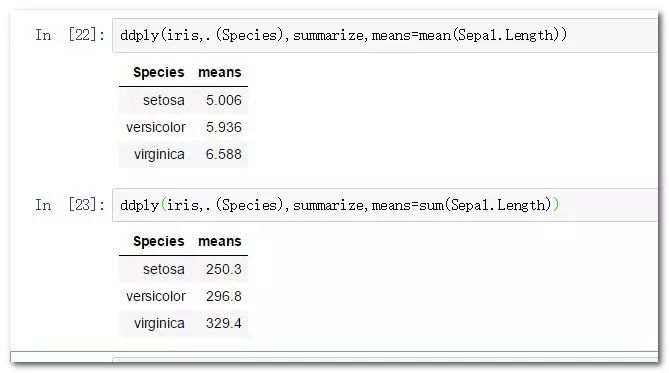
ddply(.data, .variables, .fun =) #一般只需提供数据框,带聚合分类字段,以及最终的聚合函数与聚合变量公式。它的用法与内置的tpply用法如出一辙。
----------
Python:
----------
import pandas as pd
import numpy as np
Python中长用到的数据聚合工具主要包括groupby函数,agg函数以及povit_table等。
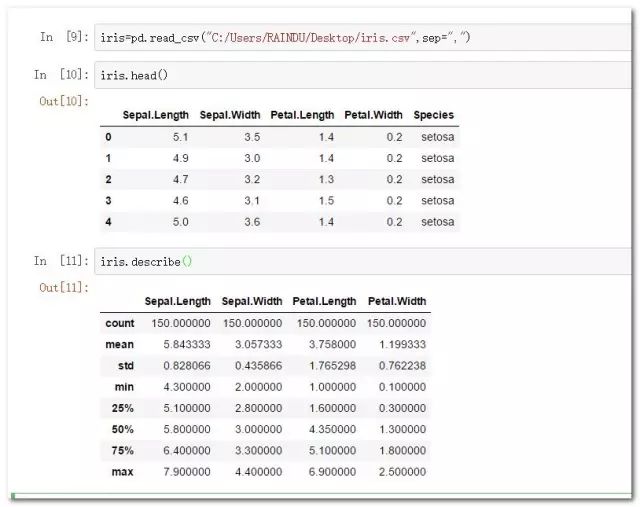
iris=pd.read_csv("C:/Users/RAINDU/Desktop/iris.csv",sep=",")
iris.head()
iris.describe()
使用pandas中的groupby方法可以很快捷的进行分组数据聚合。
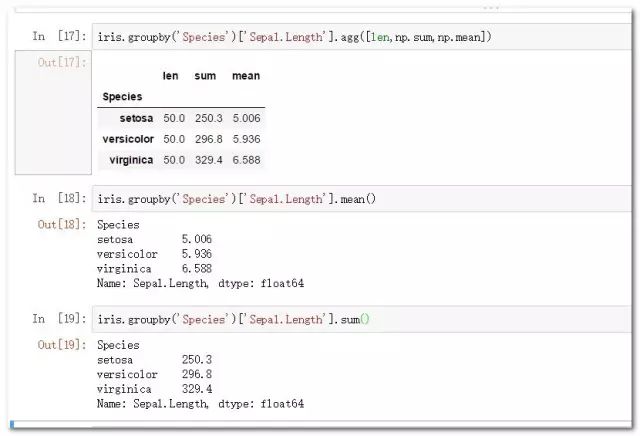
iris.groupby('Species')['Sepal.Length'].mean()
iris.groupby('Species')['Sepal.Length'].sum()
iris.groupby('Species')['Sepal.Length'].agg([len,np.sum,np.mean])
iris.groupby('Species')['Sepal.Length'].agg({'count':len,'sum':np.sum,'mean':np.mean})
#对输出进行自定义命名:
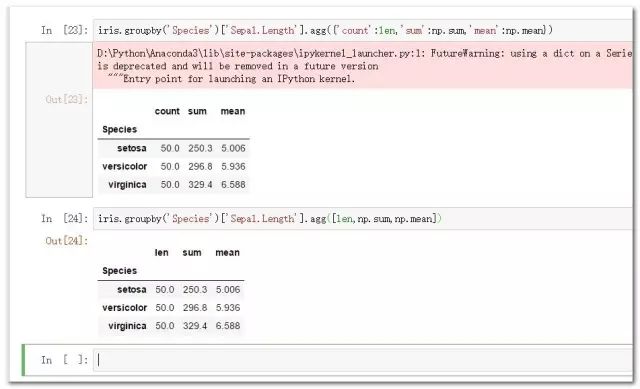
只聚合一个变量可以直接使用对应聚合函数,需要聚合多个变量则可以 借助agg函数完成。




