
Neurons字幕组出品
翻译
|
智博
校对
|
龙牧雪
时间轴
|
虫
2
后期
| Halo
项目管理
|
大力
Neurons字幕组
第四期作品
震撼来袭!
Neurons
字幕组源自英文单词Neuron,一个个独立的神经元,汇聚千万,成就了四通八达,传递最in最酷炫信息的神经网络。
来吧,
和Neurons一起,玩点不一样的AI!
还记得吗?9月26日GTC 2017北京场的舞台上,英伟达创始人黄仁勋展示了用英伟达GPU的识别器进行图像推理,可以在一秒钟识别560张图像▼

当你还在震惊AI识别图像的速度(当然还有对于花卉知识的储备量)时,我们今天要说的,则是AI识别图像的深度。神经网络不仅仅可以做到图像分类,还可以“看图说人话”!
想要一探究竟嘛?今天我们将用一个2分钟小视频,
为大家介绍人工智能怎样结合卷积神经网络CNN与循环神经网络RNN,识别图像并输出一句完整的描绘语句!
在视频中出镜的论文是李飞飞的博士Andrej Karpathy大神与李飞飞合著的经典论文Deep Visual-Semantic Alignments for Generating Image Descriptions。
关注大数据文摘公众号,并在后台回复
“
神经元
”
,可直接下载本期论文。
请在
WiFi
下观看小视频,暂时无法观看的读者可以先收藏,或者下拉直接查看文字版要点,土豪请随意
~
神经网络是怎么看图说话的?
神经网络的一个分支——大名鼎鼎的卷积神经网络CNN由于适合人类的视觉机制,从而更加适合处理和分类图像。
在
Karpathy
开发的这个页面,你可以实时看到卷积神经网络的训练结果:
http://cs.stanford.edu/people/karpathy/convnetjs/demo/cifar10.html
从这些模糊的图片中,算法试图猜测图片可以被归为哪类▼
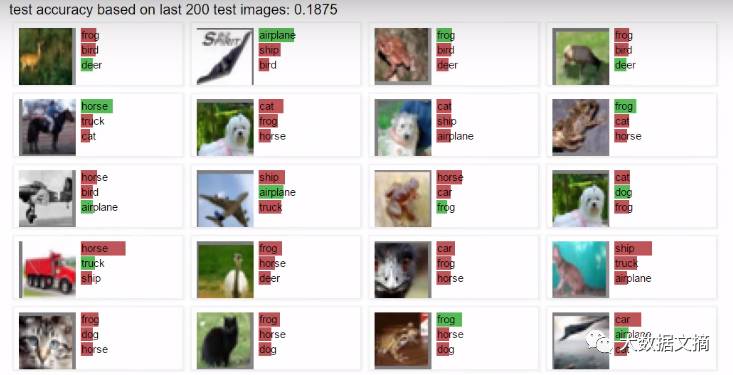
如果这个神经网络被训练得足够久,它可以达到80%的分类准确率!现在尖端的研究技术能达到大概90%的准确率,仅仅比人类处理同样的任务结果差4%。这已经超(you)级(dian)厉(ke)害(pa)了!
但是更加厉(kong)害(bi)的还在后面!由于句子可以看成一个由单词构成的序列,因此我们可以用循环神经网络RNN来构建句子。
将CNN的读图术与RNN的构句法结合起来,我们用图像作为输入,句子作为输出,也就是算法能通过“看”一幅图,总结出图片的内容,生成对图片的文字描述,并输出一句完整的人话!

△通过RCNN,AI输出了“狗跳起来接住了飞盘”这样一句完整的人话
如果你觉得这还不够惊艳的话,准备好,接下来的内容将让你大跌眼镜:
看到下面这些图,算法识别出了“穿了橙色安全背心的建筑工人正在路上工作”、“一个男人正在投掷一个球”、“一条黑白相间的狗越过了横杆”▼

算法不仅能识别出来图片里的建筑工人,还能看出来他穿了安全背心,并且他现在在路上工作。它同样能看出来一个男人正在投掷一个球,尽管在图中“球”几乎不可见。
识别出狗“越过”了一个横杆就更了不起了,因为算法能区分“越过”和“钻过”(over/under),尽管它只看到了代表三维世界的二维图像。
当然也有很搞笑的识别失败的情况啦:
比如这个,“一个宝宝拿着棒球棒”▼

额,你们这届
AI
到底行不行啊?
……
看在宝宝这么可爱的份上,这次就算了╮
(
╯▽╰
)
╭
可是下面这个,就实在是让人哭笑不得
……
“
一个宝宝和玩具熊躺在床上
”
▼

(这个风骚的男人把
AI
都给耍了)
哈哈哈,这些是不是很
6
呢?
戳这里就可以看到这个算法的更多
“
看图说话
”
结果:
http://cs.stanford.edu/people/karpathy/deepimagesent/generationdemo/
(手动复制到浏览器打开哦,下同)
总而言之,我们5年前的科幻场景,已经被机器学习研究实现,何况这个学科的进展速度如此之快,我们现在了解的也只是些皮毛而已。
在AI技术爆炸式发展的今天,我们几乎可以预计到不久的将来AI又多了一项迅速将视觉信息转变为文本信息的能力。不可思议的是,神经网络目前已经可以做到诸如创作音乐甚至莎士比亚式的剧本(想起了《异形:契约》里面的大卫了有没有?)。今年二月,美国罗格斯大学(Rutgers)的艺术与人工智能实验室(AAIL)的AI,就创造出了一系列“更新颖”、“更具艺术审美吸引力”的画作,并且通过了图灵测验。
如果你想追踪更多的相关信息,请持续关注Neurons字幕组,我们将为你带来更多的干货!
论文下载
点击文章右上角关注“大数据文摘”,进入公众号,在后台对话框内回复“神经元”三个字,你将会得到我们送出的大礼包:往期所有Neurons字幕组2分钟小视频系列的原版论文合集!
同时,本期视频中介绍的论文作者
Karpathy
已经在
GitHub
上提供了项目源代码:
https://github.com/karpathy/neuraltalk2
感兴趣的同学可以到
Karpathy
本人的主页查看论文内容:
http://cs.stanford.edu/people/karpathy/deepimagesent/
Karpathy目前是特斯拉的AI主管,在自动驾驶方向担任关键角色,此前他曾在Tesla CEO埃隆·马斯克(Elon Musk)发起的非盈利机构OpenAI工作。他在斯坦福大学获得了计算机视觉的博士学位。
作为斯坦福教授李飞飞的博士生,Karpathy也是李飞飞的斯坦福CS231n Convolutional Neural Networks for Visual Recognition课程的助教兼讲师。
大数据文摘去年获得这门明星课程翻译授权,现已全部译制完毕并免费发布于网易云课堂,戳这里就可以看到带有中文字幕的课程视频啦:http://study.163.com/course/introduction/1003223001.htm
小编就想问,马斯克分分钟要上火星,还要开发洲际火箭,Karpathy大神你开发的无人车啥时候能飞起来?

感谢收看
下期再见
感谢以下同学参与翻译本期视频,最终采纳的版本为
智博
的翻译:
南么《僧伽吒经》,张世健,
乌球球,智博,晓莉
Neurons招募正在开启!
我们已经拿到了一批有趣有料的视频授权,将在第一线直击AI和大数据的发展轨迹。
无论你是曾经在其他字幕组工作过的
老司机
,还是刚刚接触AI的
小白
,只要你
有时间、有能力、愿分享
,Neurons都欢迎你,现在加入,都有机会成为Neurons的元老哦!
-
一定的英文翻译和听译能力
-
有责任心、可靠、有耐心
-
有时间(每周保证至少3小时工作量)
-
最重要的,有探索AI和数据知识的强烈好奇心!
-
第一时间接触
独家
授权视频等学习资料。
-
视频发布时会
署
上各位志愿者的
名
字和贡献。
-
有范儿有料科技
大会
的免费、优惠门票。
-
优质公司和岗位的
内推
机会。
-
和志同道合的小伙伴一起
成长
的机会。
1.听译:
有较强的听译能力,能准确听写没有字幕的视频中的台词。
2.翻译:
翻译能力强,能按照中文的用语习惯流畅地翻译字幕,需要较强的语言功底和耐心
3.校对:
对翻译的结果进行校对和二次编辑,纠正专有名词、用语上的错误,需要有较强的领域知识和文字经验。
4.时间轴:
需要处理译文和时间的之间的关系,添加字幕持续时间并将译文调整为适合观看的字幕,需要对句子时间点进行准确的把握和判定。
5.后期、压制:
把翻译得出的字幕文件和片源打包压制成可播放的影片文件。需要懂得一定的计算机硬件环境并懂得使用各类压制影片的软件。










