本文故事场景纯属虚构,人物皆为化名,除此之外都是实在干货。

本文以叙事形式浓缩了很多运维场景、技术与总结。作者探讨了:项目管理、云计算架构、高效会议管理、网络安全管理、运维自动化架构设计、项目团队管理、两地三中心架构、人员管理、运维架构体系规划、运维感悟等等与运维密切相关的典型案例及场景。
今天周五,多云雾霾,我到了单位,接杯水瞅了瞅窗外,云遮雾罩,有种做梦的感觉,不知为啥眼睛跳的厉害,这不是好兆头。
我习惯先打开邮箱,再打开即时通讯软件,再打开云笔记,看看 24 小时值班情况、工作邮件、项目邮件、即时消息和技术文章,通过这些内容信息基本上能概览昨天工作和今天要干的事情,同时了解一些最新技术动态。
面对朦胧的窗外,我在想:工作人生就是在层层迷雾中探索,不断拨云见日,开拓眼界和道路,实现虚拟梦境到现实世界的转变。

看完邮件和一些 OA 内容,我把今天要做事情划分四个层次:
重要而且紧迫。
紧迫但不重要。
重要但不紧迫。
既不重要又不紧迫。
上午 10:00,我要召开每周项目例会,讨论云计算项目进展情况和后期安排,做好四控两管一协调工作(我好像干了监理的工作)。
这个项目重大,我们将通过这些重大项目促进公司全面升级转型技术架构,由传统信息化建设转型深化移动互联网式发展,向资源集约型、平台支撑型转变。
并提供持续集成与优化服务,趋向敏捷快速交付,由单一的运维资源交付转型全面云化生态运营交付。
我们的云计算架构体系如下:

围绕上述架构原型,我们要在特定时间、预算、资源限定内依据规范完成云计算项目建设,时间紧任务重,整个项目组压力大,动力也大。
说到项目管理,它是一门大学问,做运维管理、系统集成,信息化建设,项目经理等工作都需要了解,这里梳理了一个项目管理 5 大流程 10 大知识领域知识图,有兴趣大家可以看看 PMBOk 等相关资料,这里不再赘述。

说到开会,也是一个技术活。为了提高会议效率和效能,我通常会这么做:
借鉴《罗伯特议事规则》。例如会议要有主持人、记录人以维持好会议执行效力;会议要有具体、明确、可操作的行动建议。
会议要有大小主题,不要跑题,发言有序、有时限。就事论事,不人身攻击,不质疑私人偏好,习惯,文化观等。
提前发会议议题,资料。避免会上临时看资料,临时讨论,所有都是临时拍脑袋,导致会议冗长、效能差。
做好会议纪要,遵循 SMART 原则。明确会议的结论,任务、执行人和期限,做好工作任务追踪、追溯。
关于我们云计算项目进展,我看了下上周会议纪要,当前还有两个重要问题待解决:
这些问题都很棘手且重要,因此问题交由王宜牵头解决。王宜是我们的一个全栈型 SRE 人才。
他从前端 CDN、负载、代理到后端数据库、存储样样通,熟悉网络架构,我们的新建 IDC 网络架构就是他主导设计的,他还能写的一手好代码,我们的运维自动化平台的核心模块也是他主要完成的。
但有些遗憾的是王宜同学总是喜欢上来就干,不喜欢写规划,不喜欢写文档总结,无法协调好团队。
自打让他负责带团队之后,结果依然是他一个人在全线战斗,没有发挥整个团队的价值。
为此我跟王宜谈了多次,期望他能发挥更大能力,每当我们讨论到技术和管理的平衡关系时,最终往往陷入到底技术重要还是管理重要的漩涡中。不知广大读者朋友有何见解?
项目会刚开不久,这时网络安全负责人刘森,神色凝重,让我出来一下。
我跟着他到了隔壁会议室,刘森拿出一份文件来说,这是内部安全审计结果,我们还有安全漏洞,需要立刻整改,否则下周一外部审计过来就不合适了。
我看了看报告,里面提到的安全问题概要如下:

现在网络安全是运维常态化重点工作,我们通常定期做安全漏洞扫描、渗透测试。
针对安全漏洞,我们常用的漏洞修复策略如下:
严格各区域之间访问限制与隔离,阻止服务器之间的互相访问,防止内网移动渗透。
下线有问题的系统,保留证据,重新安装部署备机后再上线。
严格堡垒机访问权限,什么角色的人使用什么权限。
加强系统 ip tables 访问策略,严格应用访问策略。
修改相关系统的账号密码。
升级打补丁,修复系统、应用漏洞。
清理有木马等异常的系统服务器。
虽然有上述很多安全防护措施,但我们总还隐约担心安全,有种一入安全深似海,回首沧桑惊心怀。也因此我们正在探索从整体网络架构、安全架构层面彻底解决安全防控问题。
由于是限期安全整改,截止到下周一必须完成。我们得立刻找人手开始修复漏洞。
考虑到这次安全限期整改的重要紧急性,我安排王宜加入刘森安全整改项目组。王宜是一个全栈型技术人才,希望他能帮助刘森尽快解决这些安全问题。
对于批量增删改查、密码查询修改,批量打补丁,系统部署,监控管理等工作,我们有自己研发的一套运维自动化综合管理平台,总体功能框架设计如下图:

本运维自动化是一体化解决方案,从我们的实际业务需求出发,基于 DevOps 理念,引入轻量级 IT 服务管理体系,以 CMDB 资源管理为核心驱动,围绕运维监控及自动化管理为建设主体,构建起敏捷运维服务管理体系。
通过运维自动化管理解决方案融合、统一管理运维人员、资源、事件流程,统一监控管理 IT 资源,有效关联整合数据信息,从而促进运维管理工作的标准化、流程化、可视化、自动化、智能化、产品化。
最终目标是要提供更好地运维服务交付能力,更好地支撑我们当前及未来业务快速稳健发展。
如下是本运维自动化系统逻辑架构规划图:
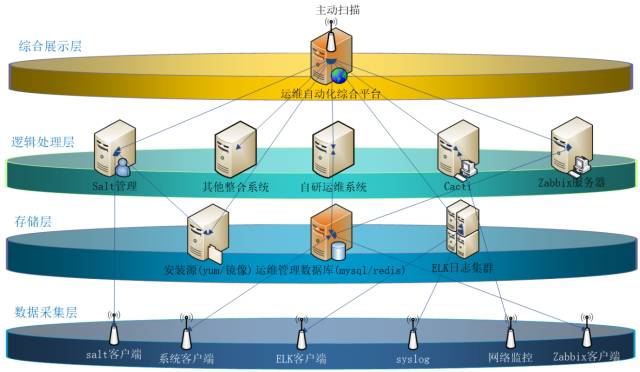
对于运维自动化系统的设计与实现思路,我们老大(后文即将出场)曾提出了他的一些建议:
对此我有些不解,我总想把该系统做成大一统紧耦合,自动化到极致,寄希望于运维自动化解放运维人员,但实际情况我逐渐领悟到二八原则和中庸之道,凡事要适度恰到好处,凡事要柔韧不可用尽。
上午的项目会、安全事情和一些运维琐事交织在一切,让人感觉时间飞快,眼看就要 12:00 了,我看见刘森和王宜好像还在因为安全修复项目组怎么组建、怎么分工,怎么开工的事情争论不断。
我忍不住过去也加入了他们的争论之中,我把我总结的布鲁斯·塔克曼的团队发展阶段模型及应对措施给他们讲了讲,希望他们能从中获得一些价值和帮助。

说完我先走了,我得赶紧吃点午饭,准备一些材料。下周需要召开立项研讨会。
我打算升级优化核心数据库系统的技术架构,为此我已初拟了个立项报告。考虑到项目重大,我需要今天下午提前向老大汇报征求一下意见。
下午 14:00,我准时来到老大的办公室,直奔主题说明我的想法。
由于历史原因,我们的这组核心数据库系统存在一些隐患:
因此我建议重新升级优化架构,从整体设计上解决这些问题,主要思路如下:
两地三中心是什么样的架构,下面我给一个示意图例:

我认为我考虑地很周全,我稀里哗啦说了一通,但发现老大没有欣赏之意。
老大问:“你是否与业务部门,研发部门,商务部门一块讨论过这个方案?”
“这个……没有…….”我支支吾吾说:“我觉得这是纯技术方案…..”
老大又问:“互联网运维和传统信息化运维有区别么?”
“这个,那个…..”我一时间脑袋空白了。
老大继续再问:“你这方案的优化创新思路在哪里?”
这时我感觉一股冷气直入后脊梁,头脑飞速但凌乱:“我这个方案有很多成熟案例,这种技术架构已有好多年了……”
“是好多年了,你还在照搬多年前的技术架构,方案毫无创新。”,老大若有所思:
首先你应该了解业务,技术与业务不能两张皮,技术要与其他部门业务协同,技术要支撑业务发展。
其次咱们不能再走传统信息化那种封闭竖井式道路,要走平台化、集群分布式、敏捷可持续、开放互联、合作共赢的生态道路。
最后再次提醒你们,从业务到技术到运营,你们需要互相协同与支持。
我有种顿悟的感觉,但同时我也想赶紧离开这里。突然我的手机短信响了,是一条告警显示“严重故障,MySQL 主从不同步”,我有种得救的感觉。
赶紧跟老大说:“我有个监控告警,小故障,得去了解下情况”,说完赶紧从办公室出来了。
我走到王宜那里问:“谁在处理 MySQL 主从不同步的故障?”
王宜很自信地说:“我在处理,这个小问题我能解决。”
“安全漏洞防护进展咋样了?”我问。
“刘森让我帮助他做系统安全加固和打补丁”,王宜有些无奈地表情说:“他根本不了解我这边工作情况,我今天一直在忙,根本没时间做系统安全加固的事情,等我把 MySQL 的问题解决了,再做系统 ip tables 控制策略…..”
我没有再说什么,只是在想,其实我更希望王宜他们团队的组员去处理(而不是王宜直接处理),希望发挥其团队每个人的价值。
但我又想,王宜本身也需要锻炼团队管理协调能力,所以还是由王宜自己判断如何协调团队工作吧。
我走回自己的办公位,冥思苦想互联网运维与传统运维有什么区别呢?不知广大读者朋友有何见解?我先说说拙见吧。
传统运维与互联网运维的差异,可以归结为如下 6 大差异:
架构差异。
工作内容差异。
知识体系差异。
面向对象差异。
运维人员差异。
体制理念差异。
这里只摆放一个架构差异的图解,如下图所示:

这时,张驰快步向我走来,看着有些着急:有故障,我们的多个域名打开异常缓慢,网站性能监测频发告警。
虽然我干 IT 工作 10 余年了,但当我听到“故障”这俩字,仍然感觉刺耳敏感。
作为运维人,经常要救火,头脑需要冷静,做到胆大心细,行事可以忙但不能乱。对于这种访问故障,我们通常会基于网络架构层次逐个捋顺排查和定位。
网站架构通常如下图所示:

基于网站架构及网民访问的数据流向,我们逐个排查 CDN、源站、负载均衡……
很快,我们发现一个老旧负载均衡设备上并发连接数激增,如下图所示:

根据我们以往经验,这种突发激增往往由某种网站活动引起的。
经过网安部梳理 CDN 监测信息、负载情况、域名网站、流控监测信息,网站业务运行信息,我们很快确定了部分网站缓慢原因。
由于恶意刷票导致突发大并发连接,过度消耗设备性能,由于这台负载老设备处理并发性能有限,因此该负载下网站都出现了访问缓慢问题。
我看了下时间 17:45,网安部门刘森向我走来,他怀着一种庆幸(找到了问题原因)和一些委屈(又是投票,这是业务层面事情,不是运维导致的故障)向我反馈详细故障由来。
等他说完原因,我问道:“业务影响范围有多大?后续如何处置?什么时间彻底解决?”
对于这些问题,刘森貌似还没准备好如何回答。
我接着说道:做运维需要熟悉业务才能更好地支撑业务,基于业务场景的运维是运维价值观的重要体现。
这个时候,我们老大也走了过来:“问题解决怎么样了?要抓紧解决,不要保留问题过夜”,老大又说:“发生了这么多问题,你们要从架构体系层面高屋建瓴式地解决问题,而不是天天忙于被动救火”。
我回答道:“好的,我赶紧落实处理恶意刷票问题……”。
老大又说道:“还有,你们要考虑如何升级转型架构体系,遵循公司战略目标,通过技术创新升级并引领业务发展”。
对于老大的建议,我若有所思…..不过我还是先解决当下棘手的刷票问题吧。对于这种恶意刷票现象,很多行业已屡见不鲜了,考虑到投票业务多样性,我们运维解决思路也有很多方式。
列举如下:
调整负载均衡流量,将大流量的业务切换到小流量的负载上,或者单独配置(软、硬)负载。
使用 IP 地址过滤,通过 CDN、前端防火墙、负载、代理、Lua 等软硬件对恶意 IP 进行过滤。
通过 Session 会话、Cookies 验证来防止恶意刷票。
通过实名制登记、登录验证码等来防止恶意刷票。
把业务搬到公有云上,借助公有云资源来防护恶意刷票,也是一种手段。
不知不觉时间已经 18:50 了,这时我们值班服务台 Service Desk 同事打回电话说(需要二线支持),业务部门反映发布系统非常缓慢,甚至打不开,图片、JS、CSS 加载缓慢。
但我查看网站性能监控并未告警,从监控来看有些波动,但貌似没有太明显异常。

这是为什么?这可能是前端或系统相关问题,我想找王宜核查一下,但刘森说他已经下班走了。
“他不是在帮助你解决安全防护的问题么,怎么没有个里程碑式结论就走人了?”我有些诧异。
“这个安全事情。。。。。咱们待会再商议吧”,刘森无奈地说“我现在给王宜打电话,优先处理业务用户反馈问题”。
稍后刘森说:“王宜电话没人接,您看下步怎么办?”
这时我脑子里首先一闪念,想起了一个运维前辈曾经给我说过“做运维工作,要有高度责任心,不甩锅不背锅”。
我拿起电话,直接拨通了王宜团队的组员李智的号码。我把问题现象给他描述了一下。
李智说:“头,这个问题现象有些笼统,咱们今天都做过什么变更么?”
我犹豫了一下,“今天的变更有很多,不过你先查查前端系统吧,我再找人查其他环节”。
李智也犹豫了一下“……我可能最近也要变动一下…..”
“你说什么?”我好想没听懂。
“我正想找您说这事……”李智说“我打算离职了……”
“啊?”我没继续说。
“这个回头再说吧……”李智转移了话题“我先处理问题吧”。
我挂下电话,有种焦头烂额的感觉。我想了想:铁打的营盘,流水的兵,离职倒也是正常现象。
可能离职原因多种多样,但归纳起来,(借鉴马斯洛需求层次理论)无外乎以下几种诉求得不到满足:生理需求(工资待遇)、安全需求(公司内外环境)、社会需求(文化、社交)、尊重的需求(人文关怀、团队建设)、自我实现的需求(职业发展)、自我超越的需求(人生发展)。

我还在猜想李智的离职原因,这时王宜电话打回电话说刚才没听见电话响。我把问题给他又复述了一遍,他好像知道了什么。
“可能由于批量化操作,导致前端有组特殊的 Ngnix 系统的 ip tables 配置错了”,王宜说:“估计李智不清楚这套系统环境,所以这事还是由我来处理吧”。
没过一会,王宜反馈说问题解决了。主要原因是:这组特殊的 Ngnix 在负载后面,但由于错误的 ip tables 策略,收到负载请求则不处理丢弃,因此造成超时 TCP 重传,负载只能再向 Ngnix 分配请求,如此造成访问请求缓慢不稳定。
虽然问题解决,但我总结教训如下:
尽量避免变更,应保持不可变基础设施。
一次变更只做一件事,同时做好变更的记录。
条件允许的话,在做变更之前先做好测试、应急回退措施。
做变更最好有实施者,有复核(配合)人员,有工作互备人员。最好能做到相关人员周知。
变更最好周五之前做,夜晚做。
运维自动化的确是把双刃剑,没有标准化、流程化的批量自动化可能是灾难。
这时我突然想起老大的提醒,我应该从架构体系的层面梳理解决当前一锅粥似的一系列问题。运维架构体系是运维的基础及核心竞争力。
通过运维体系的构建及完善,使我们的运维做到稳定可靠,准确完备,规范科学。
以面向服务、持续交付为核心,从人、事、物、流程这四个方面把运维体系进行解构,它们彼此互相作用,共同构建了一个完整实用的运维体系。

前文已阐述了传统运维与互联网运维的不同层面维度的差异,但从另一方面来看,作为运维,还是有很多共同之处。
这里我将从一个架构高度看待和规划运维,如下图所示:
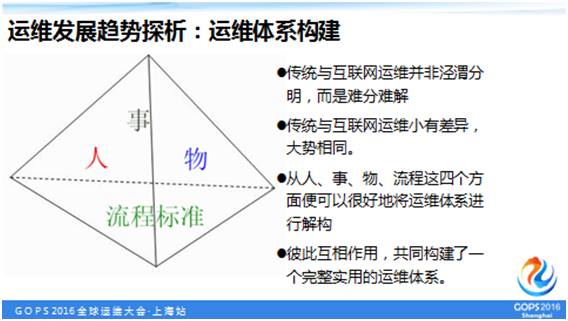
下面列举了这四个方面各自的含义及相关内容:
人:例如完善岗位职责与职业发展、提高团队技术水平、完善技能分享与培训、完善团队绩效考核、规范工作行为规范等。
目的是要建成一支工作高效、技术水平高、团结稳定、有职业素养的运维团队。
事:例如做好日常基础运维工作,保障好生产业务运行。不断探索新的运维理念与技术,探索优化系统架构。
具体可以分为几大块,例如运维流程管理,资源架构规划,应急与故障处理,监控与优化,安全与防护,项目及日常工作等等。
目的是要明白运维做什么正确的事,怎么正确地做事,做事有章法,稳定高效能。
物:主要是如何管理好系统运维所涉及的各种资源。例如机房环境、办公设备、服务器、网络设备、操作系统、应用软件、工具等各种软硬件资源。
目的要使各类资源配置管理妥当,清楚资源属性,知道从哪来,现在哪,要去哪使得物尽其用,物有所值,安置妥当。
流程标准:运用流程标准将上述要素(人、事、物)有机地结合,有序科学地流转、高效稳定地运行。
例如资源规划与采购,各种标准规范、项目规范、软硬件配置部署规范、安全制度、工作交接等等。
如下列举一个安全岗位运维规划图:

想着想着,不觉得已进入深夜,我看下时间,晚上 22:17 了。忙碌了一天,感觉整个身体被掏空,终于回到家可以洗把脸睡了。
晚上做起了梦,梦境不可描述,我把这个奇葩的梦境画面贴出来,请读者帮我解梦,说说你们的理解。

这虽然是一个梦,但梦却是真实的表达。作为运维工作者,其中的酸甜苦辣,谁解其中味?也许谁干谁知道。
工作繁琐:采购设备软硬件,上架贴标签,系统环境软硬件部署,统计核实设备信息、复核系统变更情况,搬迁设备,调优系统……如此工作,日复一日,年复一年,会让人感觉无始无终。
鸭梨山大:有句话说的好“操着卖白粉的心,赚着卖白菜的钱。”,运维各种繁琐工作交织一块,在有限时间、精力和繁重工作情况下,我们倍感鸭梨山大。系统故障、上线、调优、升级、恢复等特殊环境下,我们的身心都面临着不可描述的感受……
设备系统故障:设备系统,尤其是过保的硬件设备,很容易出故障。机房环境、温湿度,业务的读写频繁度,业务人员野蛮地使用,各种因素都会导致设备系统意外故障。意外就是意外,往往出现在不恰当的时间、地点。经常会让运维人员莫名郁闷。
熬夜加班:有没有别人节假日团圆 Happy,你在苦逼的加班熬夜。有没有别人吃喝畅聊,你在角落里苦逼的远程 VPN,有没有三更半夜向特务一样起床敲代码,低声细语的频繁打电话?有没有。。。。。。?反正我都有。。。。。
IT 消防员:我们就是 IT 消防员,我们的最高境界就是无我境界,大家都很舒服时都想不起来我。一旦想起来我,可能IT环境出问题了。。。。。。我们只有硬着头皮去结尾,牺牲我一个,幸福一大家。
背黑锅:运维人员有天生背黑锅的宿命。当你找不出别人的问题时,那就只能背黑锅,或许找出问题,也可能一起背黑锅。任何行业工作都有其委屈尴尬的一面,背黑锅是运维人员成熟历练的必经之路。
我感觉梦里有种刺耳有熟悉的铃声响起,不……我突然醒了,原来是手机响了……..
作者:韩晓光
编辑:陶家龙、孙淑娟
来源:转载自高效运维微信公众号
韩晓光,Devops Master、信息系统项目管理师、ITIL Foundation、RHCE,著有《系统运维全面解析:技术、管理与实践》一书。

京东大规模数据中心网络运维监控之眼
阿里Dubbo疯狂更新,关Spring Cloud什么事?
饿了么业务爆发性增长欠下的“技术债”,迟早都是要还的!









