依赖项
下面是我们将在 Windows 10(Version 1607 OS Build 14393.222)上配置深度学习环境所需要的工具和软件包:
-
Visual Studio 2015 Community Edition Update 3 w. Windows Kit 10.0.10240.0:用于其 C/C++编译器(而不是 IDE)和 SDK,选择该确定的版本是因为 CUDA 8.0.61 所支持的 Windows 编译器。
-
Anaconda (64-bit) w. Python 3.6 (Anaconda3-4.4.0) [for Tensorflow support] or Python 2.7 (Anaconda2-4.4.0) [no Tensorflow support] with MKL:Anaconda 是一个开源的 Python 发行版本,其包含了 conda、Python、NumPy、SciPy 等 180 多个科学包及其依赖项,是一个集成开发环境。MKL 可以利用 CPU 加速许多线性代数运算。
-
CUDA 8.0.61 (64-bit):CUDA 是一种由 NVIDIA 推出的通用并行计算架构,该架构使 GPU 能够解决复杂的计算问题,该软件包能提供 GPU 数学库、显卡驱动和 CUDA 编译器等。
-
cuDNN v5.1 (Jan 20, 2017) for CUDA 8.0:用于加速卷积神经网络的运算。
-
Keras 2.0.5 with three different backends: Theano 0.9.0, Tensorflow-gpu 1.2.0, and CNTK 2.0:Keras 以 Theano、Tensorflow 或 CNTK 等框架为后端,并提供深度学习高级 API。使用不同的后端在张量数学计算等方面会有不同的效果。
硬件
-
Dell Precision T7900, 64GB RAM:Intel Xeon E5-2630 v4 @ 2.20 GHz (1 processor, 10 cores total, 20 logical processors)
-
NVIDIA GeForce Titan X, 12GB RAM:Driver version: 372.90 / Win 10 64
安装步骤
我们可能喜欢让所有的工具包和软件包在一个根目录下(如 e:\toolkits.win),所以在下文只要看到以 e:\toolkits.win 开头的路径,那么我们可能就需要小心不要覆盖或随意更改必要的软件包目录。
运行下载的软件包以安装 Visual Studio,可能我们还需要做一些额外的配置:
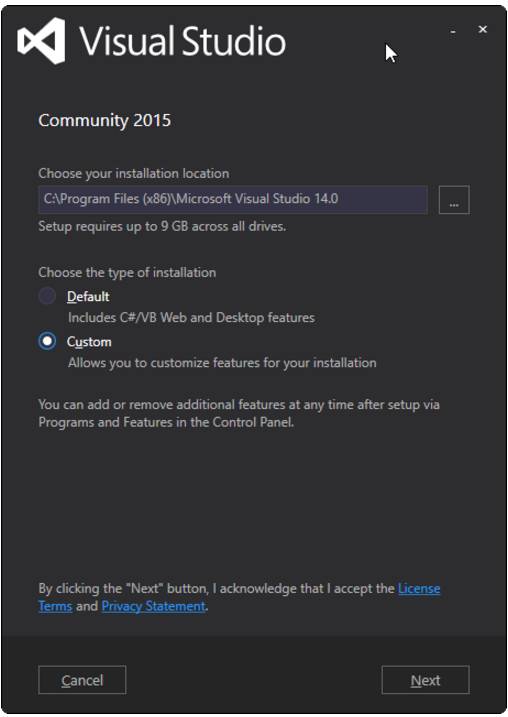
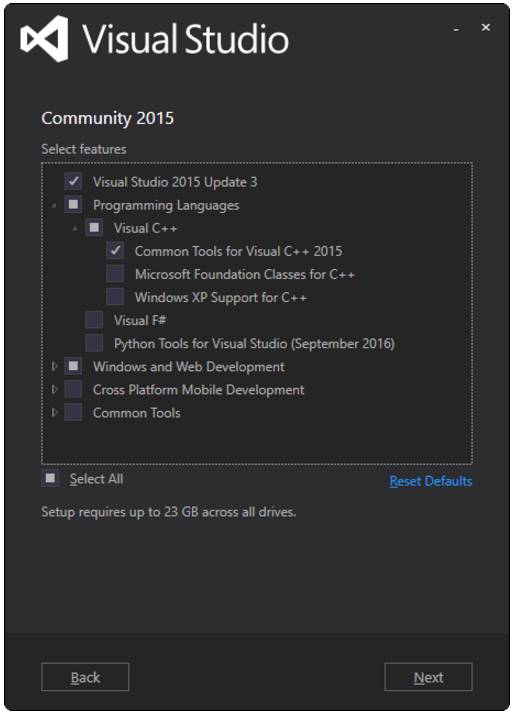
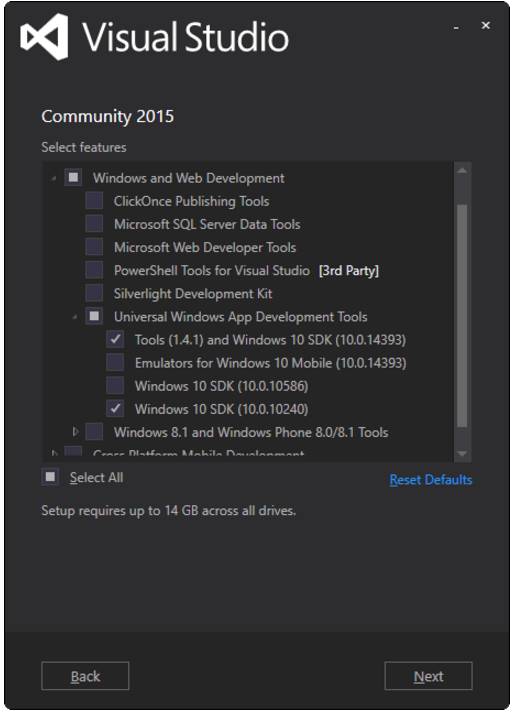
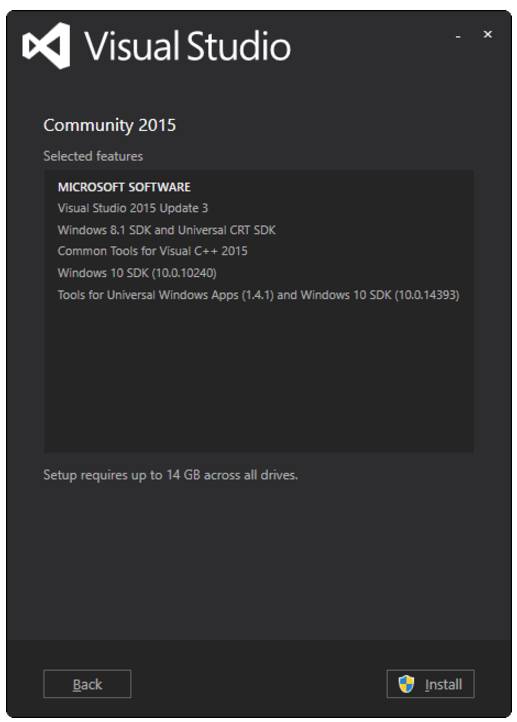
-
基于我们安装 VS 2015 的地址,需要将 C:\Program Files (x86)\Microsoft Visual Studio 14.0\VC\bin 添加到 PATH 中。
-
定义系统环境变量(sysenv variable)INCLUDE 的值为 C:\Program Files (x86)\Windows Kits\10\Include\10.0.10240.0\ucrt
-
定义系统环境变量(sysenv variable)LIB 的值为 C:\Program Files (x86)\Windows Kits\10\Lib\10.0.10240.0\um\x64;C:\Program Files (x86)\Windows Kits\10\Lib\10.0.10240.0\ucrt\x64
Anaconda 4.4.0 (64-bit) (Python 3.6 TF support / Python 2.7 no TF support))
本教程最初使用的是 Python 2.7,而随着 TensorFlow 可作为 Keras 的后端,我们决定使用 Python 3.6 作为默认配置。因此,根据我们配置的偏好,可以设置 e:\toolkits.win\anaconda3-4.4.0 或 e:\toolkits.win\anaconda2-4.4.0 为安装 Anaconda 的文件夹名。
运行安装程序完成安装:
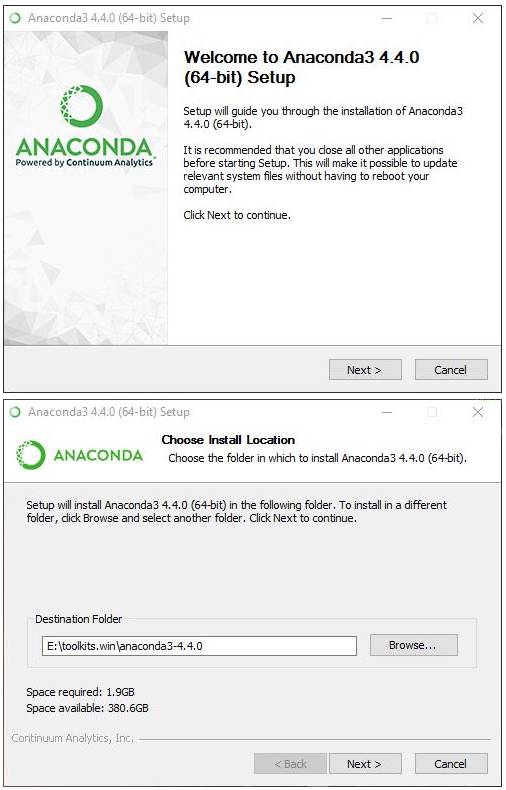
如上,本教程选择了第二个选项,但不一定是最好的。
定义一下变量并更新 PATH:
-
定义系统环境(sysenv variable)变量 PYTHON_HOME 的值为 e:\toolkits.win\anaconda3-4.4.0
-
添加 %PYTHON_HOME%, %PYTHON_HOME%\Scripts 和 %PYTHON_HOME%\Library\bin 到 PATH 中
创建 dlwin36 conda 环境
在安装 Anaconda 后,打开 Windows 命令窗口并执行:
#使用以下命令行创建环境
$ conda create --yes -n dlwin36 numpy scipy mkl-service m2w64-toolchain libpython jupyter
# 使用以下命令行激活环境:
# > activate dlwin36
#
# 使用以下命令行关闭环境:
# > deactivate dlwin36
#
# * for power-users using bash, you must source
#
如上所示,使用 active dlwin36 命令激活这个新的环境。如果已经有了旧的 dlwin36 环境,可以先用 conda env remove -n dlwin36 命令删除。既然打算使用 GPU,为什么还要安装 CPU 优化的线性代数库如 MKL 呢?在我们的设置中,大多数深度学习都是由 GPU 承担的,这并没错,但 CPU 也不是无所事事。基于图像的 Kaggle 竞赛一个重要部分是数据增强。如此看来,数据增强是通过转换原始训练样本(利用图像处理算子)获得额外输入样本(即更多的训练图像)的过程。基本的转换比如下采样和均值归 0 的归一化也是必需的。如果你觉得这样太冒险,可以试试额外的预处理增强(噪声消除、直方图均化等等)。当然也可以用 GPU 处理并把结果保存到文件中。然而在实践过程中,这些计算通常都是在 CPU 上平行执行的,而 GPU 正忙于学习深度神经网络的权重,况且增强数据是用完即弃的。因此,我们强烈推荐安装 MKL,而 Theanos 用 BLAS 库更好。
CUDA 8.0.61 (64-bit)
从英伟达网站下载 CUDA 8.0 (64-bit):https://developer.nvidia.com/cuda-downloads
选择合适的操作系统:
下载安装包:
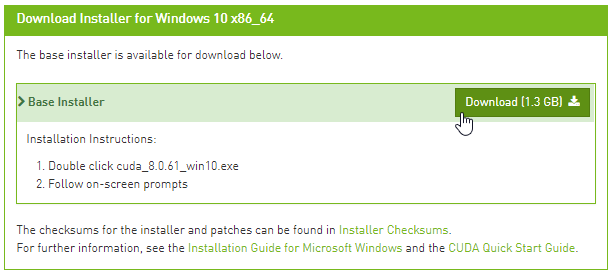
运行安装包,安装文件到 e:\toolkits.win\cuda-8.0.61 中:
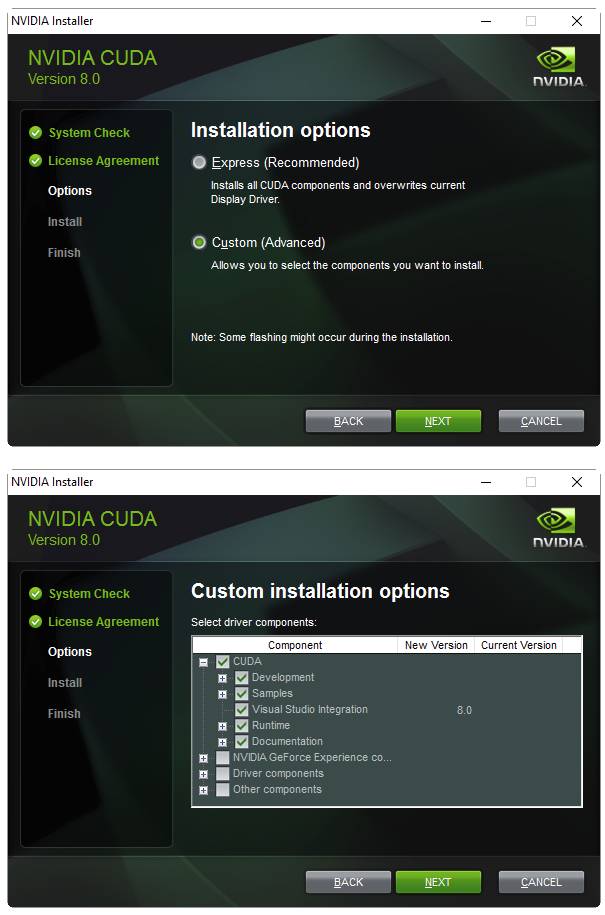
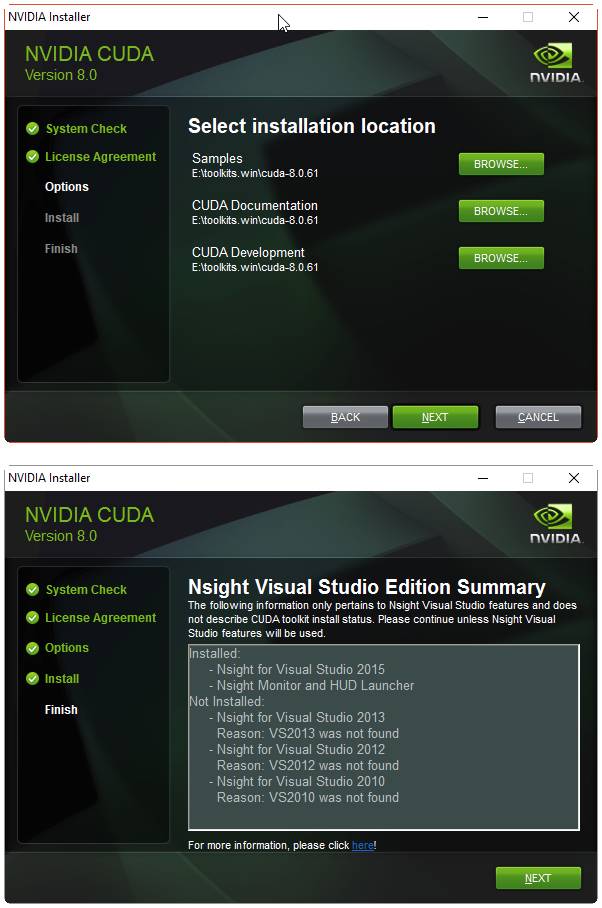
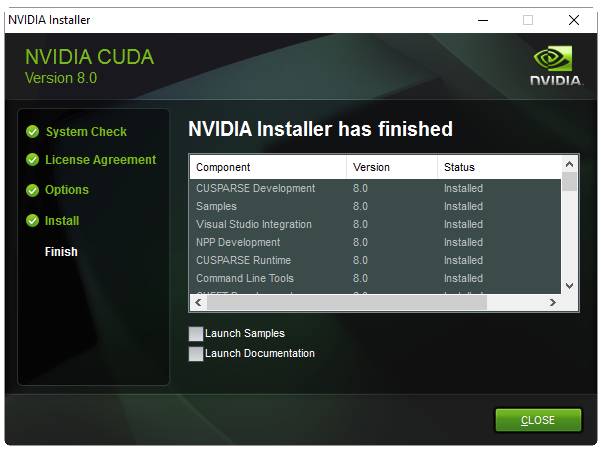
完成安装后,安装包应该创建了一个名为 CUDA_PATH 的系统环境变量(sysenv variable),并且已经添加了%CUDA_PATH%\bin 和 %CUDA_PATH%\libnvvp 到 PATH 中。检查是否真正添加了,若 CUDA 环境变量因为一些原因出错了,那么完成下面两个步骤:
cuDNN v5.1 (Jan 20, 2017) for CUDA 8.0
根据英伟达官网「cuDNN 为标准的运算如前向和反向卷积、池化、归一化和激活层等提供高度调优的实现」,它是为卷积神经网络和深度学习设计的一款加速方案。
cuDNN 的下载地址:https://developer.nvidia.com/rdp/cudnn-download
我们需要选择符合 CUDA 版本和 Window 10 编译器的 cuDNN 软件包,一般来说,cuDNN 5.1 可以支持 CUDA 8.0 和 Windows 10。
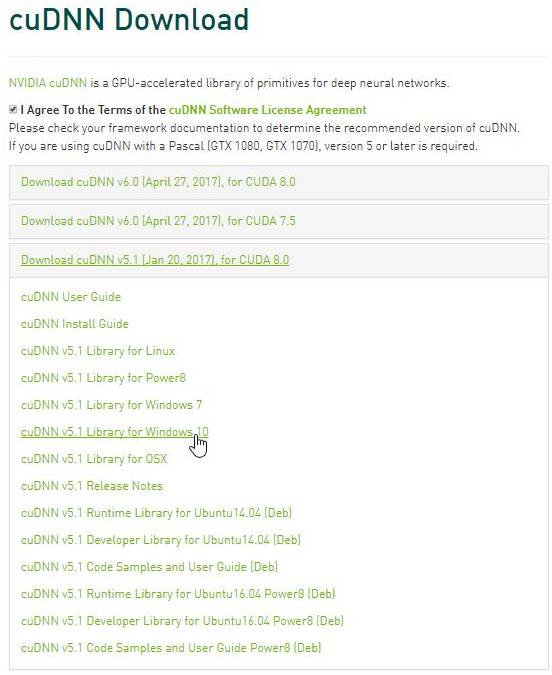
下载的 ZIP 文件包含三个目录(bin、include、lib),抽取这三个的文件夹到%CUDA_PATH% 中。
安装 Keras 2.0.5 和 Theano0.9.0 与 libgpuarray
运行以下命令安装 libgpuarray 0.6.2,即 Theano 0.9.0 唯一的稳定版:
(dlwin36) $ conda install pygpu==0.6.2 nose
#下面是该命令行安装的效果
Fetching package metadata ...........
Solving
package specifications: .
Package plan for installation in environment e:\toolkits.win\anaconda3-4.4.0\envs\dlwin36:
The following NEW packages will be INSTALLED:
libgpuarray: 0.6.2-vc14_0 [vc14]
nose: 1.3.7-py36_1
pygpu: 0.6.2-py36_0
Proceed ([y]/n)? y
输入以下命令安装 Keras 和 Theano:
(dlwin36) $ pip install keras==2.0.5
#下面是该命令行安装的效果
Collecting keras==2.0.5
Requirement already satisfied: six in e:\toolkits.win\anaconda3-4.4.0\envs\dlwin36\lib\site-packages (from keras==2.0.5)
Collecting pyyaml (from keras==2.0.5)
Collecting theano (from keras==2.0.5)
Requirement already satisfied: scipy>=0.14 in e:\toolkits.win\anaconda3-
4.4.0\envs\dlwin36\lib\site-packages (from theano->keras==2.0.5)
Requirement already satisfied: numpy>=1.9.1 in e:\toolkits.win\anaconda3-4.4.0\envs\dlwin36\lib\site-packages (from theano->keras==2.0.5)
Installing collected packages: pyyaml, theano, keras
Successfully installed keras-2.0.5 pyyaml-3.12 theano-0.9.0
安装 CNTK 2.0 后端
根据 CNTK 安装文档,我们可以使用以下 pip 命令行安装 CNTK:
(dlwin36) $ pip install https:
//cntk.ai/PythonWheel/GPU/cntk-2.0-cp36-cp36m-win_amd64.whl
#下面是该命令行安装的效果
Collecting cntk==2.0 from https://cntk.ai/PythonWheel/GPU/cntk-2.0-cp36-cp36m-win_amd64.whl
Using cached https://cntk.ai/PythonWheel/GPU/cntk-2.0-cp36-cp36m-win_amd64.whl
Requirement already satisfied: numpy>=1.11 in e:\toolkits.win\anaconda3-4.4.0\envs\dlwin36\lib\site-packages (from cntk==2.0)
Requirement already satisfied: scipy>=0.17 in e:\toolkits.win\anaconda3-4.4.0\envs\dlwin36\lib\site-packages (from cntk==2.0)
Installing collected packages: cntk
Successfully installed cntk-2.0
该安装将导致在 conda 环境目录下额外安装 CUDA 和 cuDNN DLLs:
(dlwin36) $ cd E:\toolkits.win\anaconda3-4.4.0\envs\dlwin36
(dlwin36) $ dir cu*.dll
#下面是该命令行安装的效果
Volume in drive E is datasets
Volume Serial Number is 1ED0-657B
Directory of E:\toolkits.win\anaconda3-4.4.0\envs\dlwin36
06/30/2017 02:47 PM 40,744,896 cublas64_80.dll
06/30/2017 02:47 PM 366,016 cudart64_80.dll
06/30/2017 02:47 PM 78,389,760 cudnn64_5.dll
06
/30/2017 02:47 PM 47,985,208 curand64_80.dll
06/30/2017 02:47 PM 41,780,280 cusparse64_80.dll
5 File(s) 209,266,160 bytes
0 Dir(s) 400,471,019,520 bytes free
这个问题并不是因为浪费硬盘空间,而是安装的 cuDNN 版本和我们安装在 c:\toolkits\cuda-8.0.61 下的 cuDNN 版本不同,因为在 conda 环境目录下的 DLL 将首先加载,所以我们需要这些 DLL 移除出%PATH% 目录:
(dlwin36) $ md discard & move cu*.dll discard
#下面是该命令行安装的效果
E:\toolkits.win\anaconda3-4.4.0\envs\dlwin36\cublas64_80.dll
E:\toolkits.win\anaconda3-4.4.0\envs\dlwin36\cudart64_80.dll
E:\toolkits.win\anaconda3-4.4.0\envs\dlwin36\cudnn64_5.dll
E:\toolkits.win\anaconda3-
4.4.0\envs\dlwin36\curand64_80.dll
E:\toolkits.win\anaconda3-4.4.0\envs\dlwin36\cusparse64_80.dll
5 file(s) moved.
安装 TensorFlow-GPU 1.2.0 后端
运行以下命令行使用 pip 安装 TensorFlow:
(dlwin36) $ pip install tensorflow-gpu==
1.2.0
#以下是安装效果
Collecting tensorflow-gpu==1.2.0
Using cached tensorflow_gpu-1.2.0-cp36-cp36m-win_amd64.whl
Requirement already satisfied: bleach==1.5.0 in e:\toolkits.win\anaconda3-4.4.0\envs\dlwin36\lib\site-packages (from tensorflow-gpu==1.2.0)
Requirement already satisfied: numpy>=
1.11.0 in e:\toolkits.win\anaconda3-4.4.0\envs\dlwin36\lib\site-packages (from tensorflow-gpu==1.2.0)
Collecting markdown==2.2.0 (from tensorflow-gpu==1.2.0)
Requirement already satisfied: wheel>=0.26 in e:\toolkits.win\anaconda3-4.4.0\envs\dlwin36\lib\site-packages (from tensorflow-gpu==1.2.0)
Collecting protobuf>=3.2.0 (from tensorflow-gpu==1.2.0)
Collecting backports.weakref==1.0rc1 (from tensorflow-gpu==1.2.0)
Using cached backports.weakref-1.0rc1-py3-none-any.whl
Collecting html5lib==0.9999999 (from tensorflow-gpu==1.2.0)
Collecting werkzeug>=0.11.10 (from tensorflow-gpu==1.2.0)
Using cached Werkzeug-0.12.2-py2.py3-none-any.whl
Requirement already satisfied: six>=1.10.0 in e:\toolkits.win\anaconda3-4.4.0\envs\dlwin36\lib\site-packages (from tensorflow-gpu==1.2.0)
Requirement
already satisfied: setuptools in e:\toolkits.win\anaconda3-4.4.0\envs\dlwin36\lib\site-packages\setuptools-27.2.0-py3.6.egg (from protobuf>=3.2.0->tensorflow-gpu==1.2.0)
Installing collected packages: markdown, protobuf, backports.weakref, html5lib, werkzeug, tensorflow-gpu
Found existing installation: html5lib 0.999
DEPRECATION: Uninstalling a distutils installed project (html5lib) has been deprecated and will be removed in a future version. This is due to the fact that uninstalling a distutils project will only partially uninstall the project.
Uninstalling html5lib-0.999:
Successfully uninstalled html5lib-0.999
Successfully
installed backports.weakref-1.0rc1 html5lib-0.9999999 markdown-2.2.0 protobuf-3.3.0 tensorflow-gpu-1.2.0 werkzeug-0.12.2
使用 conda 检查安装的软件包
完成以上安装和配置后,我们应该在 dlwin36 conda 环境中看到以下软件包列表:



为了快速检查上述三个后端安装的效果,依次运行一下命令行分别检查 Theano、TensorFlow 和 CNTK 导入情况:
(dlwin36) $ python -c "import theano; print('theano: %s, %s' % (theano.__version__, theano.__file__))"
theano: 0.9.0, E:\toolkits.win\anaconda3-4.4.0\envs\dlwin36\lib\site-packages\theano\__init__.py
(dlwin36) $ python -c "import pygpu; print('pygpu: %s, %s' % (pygpu.__version__, pygpu.__file__))"
pygpu: 0.6.2, e:\toolkits.win\anaconda3-4.4.0\envs\dlwin36\lib\site-packages\pygpu\__init__.py
(dlwin36) $ python -c "import tensorflow; print('tensorflow: %s, %s' % (tensorflow.__version__, tensorflow.__file__))"
tensorflow: 1.2.0, E:\toolkits.win\anaconda3-4.4.0\envs\dlwin36\lib\site-packages\tensorflow\__init__.py
(dlwin36) $ python -c
"import cntk; print('cntk: %s, %s' % (cntk.__version__, cntk.__file__))"
cntk: 2.0, E:\toolkits.win\anaconda3-4.4.0\envs\dlwin36\lib\site-packages\cntk\__init__.py
验证 Theano 的安装
因为 Theano 是安装 Keras 时自动安装的,为了快速地在 CPU 模式、GPU 模式和带 cuDNN 的 GPU 模式之间转换,我们需要创建以下三个系统环境变量(sysenv variable):
-
系统环境变量 THEANO_FLAGS_CPU 的值定义为:floatX=float32,device=cpu
-
系统环境变量 THEANO_FLAGS_GPU 的值定义为:floatX=float32,device=cuda0,dnn.enabled=False,gpuarray.preallocate=0.8
-
系统环境变量 THEANO_FLAGS_GPU_DNN 的值定义为:floatX=float32,device=cuda0,optimizer_including=cudnn,gpuarray.preallocate=0.8,dnn.conv.algo_bwd_filter=deterministic,dnn.conv.algo_bwd_data=deterministic,dnn.include_path=e:/toolkits.win/cuda-8.0.61/include,dnn.library_path=e:/toolkits.win/cuda-8.0.61/lib/x64
现在,我们能直接使用 THEANO_FLAGS_CPU、THEANO_FLAGS_GPU 或 THEANO_FLAGS_GPU_DNN 直接设置 Theano 使用 CPU、GPU 还是 GPU+cuDNN。我们可以使用以下命令行验证这些变量是否成功加入环境中:
(dlwin36) $ set KERAS_BACKEND=theano
(dlwin36) $ set | findstr /i theano
KERAS_BACKEND=theano
THEANO_FLAGS=floatX=float32,device=cuda0,optimizer_including=cudnn,gpuarray.preallocate=0.8,dnn.conv.algo_bwd_filter=deterministic,dnn.conv.algo_bwd_data=deterministic,dnn.include_path=e:/toolkits.win/cuda-8.0.61/include,dnn.library_path=e:/toolkits.win/cuda-8.0.61/lib/x64
THEANO_FLAGS_CPU=floatX=float32,device=cpu
THEANO_FLAGS_GPU=floatX=float32,device=cuda0,dnn.enabled=False,gpuarray.preallocate=0.8
THEANO_FLAGS_GPU_DNN=floatX=float32,device=cuda0,optimizer_including=cudnn,gpuarray.preallocate=0.8,dnn.conv.algo_bwd_filter=deterministic,dnn.conv.algo_bwd_data=deterministic,dnn.include_path=e:/toolkits.win/cuda-8.0.61/include,dnn.library_path=e:/toolkits.win/cuda-8.0.61/lib/x64
更多具体的 Theano 验证代码与命令请查看原文。
检查系统环境变量
现在,不论 dlwin36 conda 环境什么时候激活,PATH 环境变量应该需要看起来如下面列表一样:
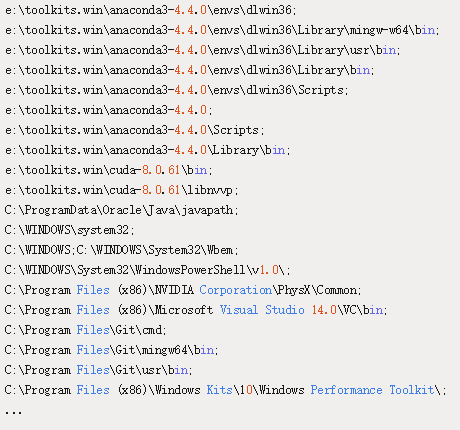
使用 Keras 验证 GPU+cuDNN 的安装
我们可以使用 Keras 在 MNIST 数据集上训练简单的卷积神经网络(convnet)而验证 GPU 的 cuDNN 是否正确安装,该文件名为 mnist_cnn.py,其可以在 Keras 案例中找到。该卷积神经网络的代码如下:
Keras案例地址:https://github.com/fchollet/keras/blob/2.0.5/examples/mnist_cnn.py
(dlwin36) $ set KERAS_BACKEND=cntk
(dlwin36) $ python mnist_cnn.py
Using CNTK backend
Selected
GPU[0] GeForce GTX TITAN X as the process wide default device.
x_train shape: (60000, 28, 28, 1)
60000 train samples
10000 test samples
Train on 60000 samples, validate on 10000 samples
Epoch 1/12
e:\toolkits.win\anaconda3-
4.4.0\envs\dlwin36\lib\site-packages\cntk\core.py:351: UserWarning: your data is of type "float64", but your input variable (uid "Input113") expects "". Please convert your data beforehand to speed up training.
(sample.dtype, var.uid, str(var.dtype)))
60000/60000 [==============================] - 8s - loss: 0.3275 - acc: 0.8991 - val_loss: 0.0754 - val_acc: 0.9749
Epoch 2/12
60000/60000 [==============================] - 7s - loss: 0.1114 - acc: 0.9662 - val_loss: 0.0513 - val_acc: 0.9841
Epoch 3/12
60000/60000 [==============================] - 7s - loss: 0.0862 - acc: 0.9750 - val_loss: 0.0429 - val_acc: 0.9859
Epoch 4/12
60000/60000 [==============================] - 7s - loss: 0.0721 - acc: 0.9784 - val_loss: 0.0373 - val_acc: 0.9868
Epoch 5/12
60000
/60000 [==============================] - 7s - loss: 0.0649 - acc: 0.9803 - val_loss: 0.0339 - val_acc: 0.9878
Epoch 6/12
60000/60000 [==============================] - 8s - loss: 0.0580 - acc: 0.9831 - val_loss: 0.0337 - val_acc: 0.9890
Epoch 7/12
60000/60000 [==============================] - 8s - loss: 0.0529 - acc: 0.9846 - val_loss: 0.0326 - val_acc: 0.9895
Epoch
8/12
60000/60000 [==============================] - 8s - loss: 0.0483 - acc: 0.9858 - val_loss: 0.0307 - val_acc: 0.9897
Epoch 9/12
60000/60000 [==============================] - 8s - loss: 0.0456 - acc: 0.9864 - val_loss: 0.0299 - val_acc: 0.9898
Epoch 10/12
60000
/60000 [==============================] - 8s - loss: 0.0407 - acc: 0.9875 - val_loss: 0.0274 - val_acc: 0.9906
Epoch 11/12
60000/60000 [==============================] - 8s - loss: 0.0405 - acc: 0.9883 - val_loss: 0.0276 - val_acc: 0.9904
Epoch 12/12
60000/60000 [==============================] - 8s - loss: 0.0372 - acc: 0.9889 - val_loss: 0.0274 - val_acc: 0.9906
Test
loss: 0.0274011099327
Test accuracy: 0.9906
1. 使用带 Theano 后端的 Keras
为了有一个能进行对比的基线模型,首先我们使用 Theano 后端和 CPU 训练简单的卷积神经网络:
(dlwin36) $ set KERAS_BACKEND=theano
(
dlwin36) $ set THEANO_FLAGS=%THEANO_FLAGS_CPU%
(dlwin36) $ python mnist_cnn.py
#以下为训练过程和结果
Using Theano backend.
x_train shape: (60000, 28, 28, 1)
60000
train samples
10000 test samples
Train on 60000 samples, validate on 10000 samples
Epoch 1/12
60000/60000 [==============================] - 233s - loss: 0.3344 - acc: 0.8972 - val_loss: 0.0743 - val_acc: 0.9777
Epoch
2/12
60000/60000 [==============================] - 234s - loss: 0.1106 - acc: 0.9674 - val_loss: 0.0504 - val_acc: 0.9837
Epoch 3/12
60000/60000 [==============================] - 237s - loss: 0.0865 - acc: 0.9741
- val_loss: 0.0402 - val_acc: 0.9865
Epoch 4/12
60000/60000 [==============================] - 238s - loss: 0.0692 - acc: 0.9792 - val_loss: 0.0362 - val_acc: 0.9874
Epoch 5/12
60000/60000 [==============================]
- 241s - loss: 0.0614 - acc: 0.9821 - val_loss: 0.0370 - val_acc: 0.9879
Epoch 6/12
60000/60000 [==============================] - 245s - loss: 0.0547 - acc: 0.9839 - val_loss: 0.0319 - val_acc: 0.9885
Epoch 7/12
60000
/60000 [==============================] - 248s - loss: 0.0517 - acc: 0.9840 - val_loss: 0.0293 - val_acc: 0.9900
Epoch 8/12
60000/60000 [==============================] - 256s - loss: 0.0465 - acc: 0.9863 - val_loss: 0.0294 - val_acc: 0.9905
Epoch
9/12
60000/60000 [==============================] - 264s - loss: 0.0422 - acc: 0.9870 - val_loss: 0.0276 - val_acc: 0.9902
Epoch 10/12
60000/60000 [==============================] - 263s - loss: 0.0423 - acc: 0.9875 -
val_loss: 0.0287 - val_acc: 0.9902
Epoch 11/12
60000/60000 [==============================] - 262s - loss: 0.0389 - acc: 0.9884 - val_loss: 0.0291 - val_acc: 0.9898
Epoch 12/12
60000/60000 [==============================]
- 270s - loss: 0.0377 - acc: 0.9885 - val_loss: 0.0272 - val_acc: 0.9910
Test loss: 0.0271551907005
Test accuracy: 0.991
我们现在使用以下命令行利用带 Theano 的后端的 Keras 在 GPU 和 cuDNN 环境下训练卷积神经网络:
(
dlwin36) $ set THEANO_FLAGS=%THEANO_FLAGS_GPU_DNN%
(dlwin36) $ python mnist_cnn.py
Using Theano backend.
Using cuDNN version 5110 on context None
Preallocating 9830/12288 Mb (0.800000) on cuda0
Mapped
name None to device cuda0: GeForce GTX TITAN X (0000:03:00.0)
x_train shape: (60000, 28, 28, 1)
60000 train samples
10000 test samples
Train on 60000 samples, validate on 10000 samples
Epoch
1/12
60000/60000 [==============================] - 17s - loss: 0.3219 - acc: 0.9003 - val_loss: 0.0774 - val_acc: 0.9743
Epoch 2/12
60000/60000 [==============================] - 16s - loss: 0.1108 - acc: 0.9674 - val_loss: 0.0536 - val_acc:
0.9822
Epoch 3/12
60000/60000 [==============================] - 16s - loss: 0.0832 - acc: 0.9766 - val_loss: 0.0434 - val_acc: 0.9862
Epoch 4/12
60000/60000 [==============================] - 16s - loss:
0.0694 - acc: 0.9795 - val_loss: 0.0382 - val_acc: 0.9876
Epoch 5/12
60000/60000 [==============================] - 16s - loss: 0.0605 - acc: 0.9819 - val_loss: 0.0353 - val_acc: 0.9884
Epoch 6/12
60000
/60000 [==============================] - 16s - loss: 0.0533 - acc: 0.9836 - val_loss: 0.0360 - val_acc: 0.9883
Epoch 7/12
60000/60000 [==============================] - 16s - loss: 0.0482 - acc: 0.9859 - val_loss: 0.0305 - val_acc: 0.9897
Epoch
8/12
60000/60000 [==============================] - 16s - loss: 0.0452 - acc: 0.9865 - val_loss: 0.0295 - val_acc: 0.9911
Epoch 9/12
60000/60000 [==============================] - 16s - loss: 0.0414 - acc: 0.9878 - val_loss: 0.0315 - val_acc:
0.9898
Epoch 10/12
60000/60000 [==============================] - 16s - loss: 0.0386 - acc: 0.9886 - val_loss: 0.0282 - val_acc: 0.9911
Epoch 11/12
60000/60000 [==============================] - 16s - loss: 0.0378
- acc: 0.9887 - val_loss: 0.0306 - val_acc: 0.9904
Epoch 12/12
60000/60000 [==============================] - 16s - loss: 0.0354 - acc: 0.9893 - val_loss: 0.0296 - val_acc: 0.9898
Test loss: 0.0296215178292
Test
accuracy: 0.9898
我们看到每一个 Epoch 的训练时间只需要 16 秒,相对于使用 CPU 要 250 秒左右取得了很大的提高(在同一个批量大小的情况下)。
2. 使用 TensorFlow 后端的 Keras
为了激活和测试 TensorFlow 后端,我们需要使用以下命令行:
(
dlwin36) $ set KERAS_BACKEND=tensorflow
(dlwin36) $ python mnist_cnn.py
Using TensorFlow backend.
x_train shape: (60000, 28, 28, 1)
60000 train samples
10000 test samples
Train
on 60000 samples, validate on 10000 samples
Epoch 1/12
2017-06-30 12:49:22.005585: W c:\tf_jenkins\home\workspace\release-win\m\windows-gpu\py\36\tensorflow\core\platform\cpu_feature_guard.cc:45] The TensorFlow library wasn't compiled to use SSE instructions, but these are available on your machine and could speed up CPU computations.
2017-06-30 12:49:22.005767: W c:\tf_jenkins\home\workspace\release-win\m\windows-gpu\py\36\tensorflow\core\platform\cpu_feature_guard.cc:45] The TensorFlow library wasn't compiled to use SSE2 instructions, but these are available on your machine and could speed up CPU computations.
2017
-06-30 12:49:22.005996: W c:\tf_jenkins\home\workspace\release-win\m\windows-gpu\py\36\tensorflow\core\platform\cpu_feature_guard.cc:45] The TensorFlow library wasn't compiled to use SSE3 instructions, but these are available on your machine and could speed up CPU computations.
2017-06-30 12:49:22.006181: W c:\tf_jenkins\home\workspace\release-win\m\windows-gpu\py\36\tensorflow\core\platform\cpu_feature_guard.cc:45] The TensorFlow library wasn't compiled to use SSE4.1 instructions, but these are available on your machine and could speed up CPU computations.
2017-06-30 12:49:22.006361: W c:\tf_jenkins\home\workspace\release-win\m\windows-gpu\py\36\tensorflow\core\platform\cpu_feature_guard.cc:45] The TensorFlow library wasn't compiled to use SSE4.2 instructions, but these are available on your machine and could speed up CPU computations.
2017-06-30 12:49:22.006539: W c:\tf_jenkins\home\workspace\release-win\m\windows-gpu\py\36\tensorflow\core\platform\cpu_feature_guard.cc:45] The TensorFlow library wasn'
t compiled to use AVX instructions, but these are available on your machine and could speed up CPU computations.
2017-06-30 12:49:22.006717: W c:\tf_jenkins\home\workspace\release-win\m\windows-gpu\py\36\tensorflow\core\platform\cpu_feature_guard.cc:45] The TensorFlow library wasn't compiled to use AVX2 instructions, but these are available on your machine and could speed up CPU computations.
2017-06-30 12:49:22.006897: W c:\tf_jenkins\home\workspace\release-win\m\windows-gpu\py\36\tensorflow\core\platform\cpu_feature_guard.cc:45] The TensorFlow library wasn't compiled to use FMA instructions, but these are available on your machine and could speed up CPU computations.
2017-06-30 12:49:22.453483: I c:\tf_jenkins\home\workspace\release-win\m\windows
-gpu\py\36\tensorflow\core\common_runtime\gpu\gpu_device.cc:940] Found device 0 with properties:
name: GeForce GTX TITAN X
major: 5 minor: 2 memoryClockRate (GHz) 1.076
pciBusID 0000:03:00.0
Total memory: 12.00GiB
Free
memory: 10.06GiB
2017-06-30 12:49:22.454375: I c:\tf_jenkins\home\workspace\release-win\m\windows-gpu\py\36\tensorflow\core\common_runtime\gpu\gpu_device.cc:961] DMA: 0
2017-06-30 12:49:22.454489: I c:\tf_jenkins\home\workspace\release-win\m\windows-gpu\py\36\tensorflow\core\common_runtime\gpu\gpu_device.cc:971] 0: Y
2017-06-30
12:49:22.454624: I c:\tf_jenkins\home\workspace\release-win\m\windows-gpu\py\36\tensorflow\core\common_runtime\gpu\gpu_device.cc:1030] Creating TensorFlow device (/gpu:0) -> (device: 0, name: GeForce G
TX TITAN X, pci bus id: 0000:03:00.0)
60000/60000 [==============================] - 8s - loss: 0.3355 - acc: 0.8979 - val_loss: 0.0749 - val_acc: 0.9760
Epoch 2/12
60000/60000 [==============================] - 5s - loss: 0.1134 - acc: 0.9667 - val_loss: 0.0521 - val_acc: 0.9825
Epoch 3/12
60000/60000 [==============================] - 5s - loss: 0.0863 - acc: 0.9745 - val_loss: 0.0436 - val_acc: 0.9854
Epoch










