早前针对疫情的影响情况,各地教育局纷纷发布了延迟开学的通知。为了让广大学子们在家也能线上学习,腾讯课堂助力“停课不停学”,推出了“老师极速版”,全方位帮助学校、老师、学生进行在线教学,助力保障学校与教育机构的教学进度与教学效果。


线上授课,最担心的莫过于:
小明同学,您来回答下这道题目...
小明?
...听得到吗?...
老师,您的屏幕黑屏了,我们看不到...
老师,您那边网络好卡呀...
我们都错过刚说的知识重点了...
Don't worry. 腾讯
课堂依托平台强大的音视频技术,有效的降低了卡顿、网络延时等问题;同时其核心系统100%上云,可实现业务秒级扩容。除此之外,当然也少不了腾讯云监控,帮助业务及时发现异常、定位问题原因,更好地保障腾讯课堂的服务质量,为老师和学生打造流畅的上课体验。

今天腾讯云监控给你划学习重点啦!
业务核心指标监控
■
■
■
■
腾讯课堂的研发同学会在各个服务模块的关键路径代码里,埋点上报自定义的业务指标,如:
-
同时在线人数;
-
进入课堂房间数;
-
老师直播授课的延时;
-
学生点击签到的成功率;
-
......
然后通过对这些业务指标进行
定义
(定义其所代表的含义,定义其是否关键指标,定义其汇聚的统计方式)、
分组
(对不同服务模块部署的机器进行分组,构建不同模块的分组视图)、
管理
(对上报的指标按系统层、逻辑层、数据层等方式分组管理,以便快速检索查看);最后来构成业务重点指标的实时监控面板,以及查看各自研发负责的指标视图和单机视图的变化情况。
(今天我们不详细展开关于业务指标监控的内容,感兴趣的同学可以浏览之前推送过的文章:
腾讯会议幕后的Metric监控
)
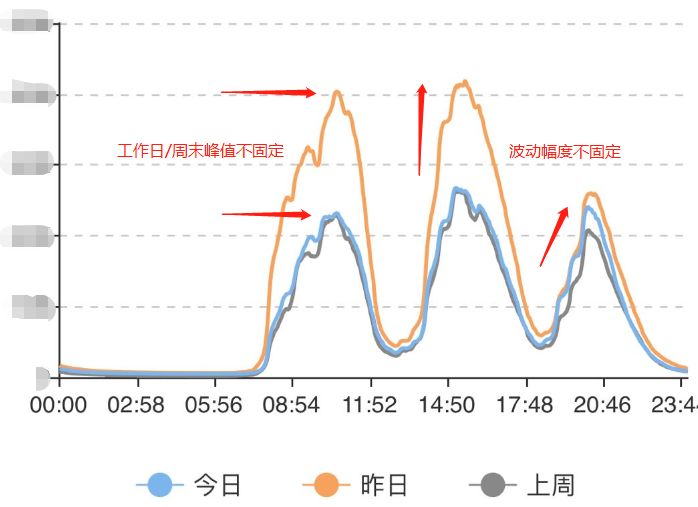
时间序列异常检测
■
■
■
■
想要更好保障服务质量,上报的指标就要更覆盖业务代码和系统的所有逻辑点。但在如此海量指标中,通过传统的告警配置来发现异常,会存在以下问题:
假设不通过告警规则配置,而是利用我们大脑去人为判断,又是怎样发现业务指标是否真的出现异常呢?我们用心电图举个例子,假如你以前正常的心电图是左边这样的波形,突然之间你的心电图变成右边这样的波形展示了:
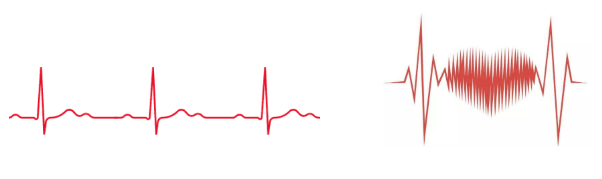
这时候的你,肯定是出现什么跟以往不同的异常情况了吧~这是心动的感觉?
![]() 还是老师突然点名让你回答问题的紧张呢?
还是老师突然点名让你回答问题的紧张呢?
![]() 不管是什么情况,你的心电图波形跟以前对比出现较大偏差。
不管是什么情况,你的心电图波形跟以前对比出现较大偏差。
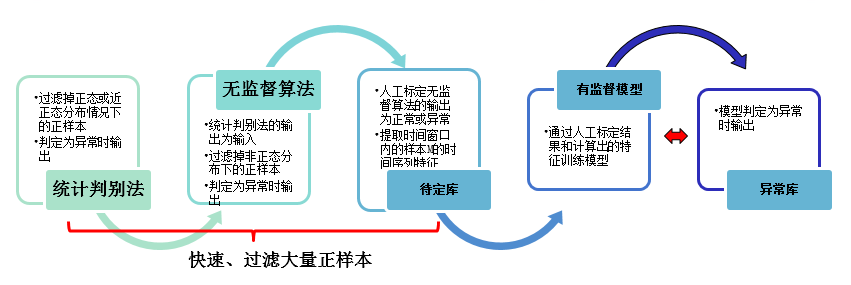
那么如果无须人为判断,是否能让机器学习算法来自动识别出异常呢?我们通过将以往的数据进行特征工程,挖掘选取出多种不同的特征,然后通过算法来进行训练,再加以人工对样本的打标,从而不断优化模型。
特征工程:
“数据和特征决定了机器学习的上限,而模型和算法只是逼近这个上限而已”。可以说,用哪些特征来表达一个时序数据样本的“长相”,是保证后面算法效果的关键,也间接决定了最终异常判决效果的关键。特征选取是一个不断优化的过程,我们从最初的max, min, mean, meidan,pvalue,rvalue(相关系数), intercept(截距), slope(斜率), stderr(拟合的标准差) 等32个特征优化到目前的100+,还在不断优化中。
算法和模型:
在前期研究测试中发现,没有任何一种单一算法可以达到业务对异常检测的准确率、召回率以及性能上的要求。比如:
所以我们的实际算法方案上,采用和不同类型算法串联的方式,发挥不同类型算法各组的优点:
平台化建设:
我们搭建了通用时序数据异常检测平台,将上述能力投入自研环境运营使用。
最后,放上几张具有代表意义的典型案例图:
(向左滑动查看更多)
时间序列联动分析
■
■
■
■
虽然我们利用机器学习来帮助我们智能地检测异常,而省去人工配置告警规则的工作,以及提升检测的准确率。但面对如此海量的指标,还是会产生大量的告警,往往导致:










