李林 编译自 Arxiv
量子位 出品 公众号 | QbitAI
最近,DeepMind发了两篇论文,一篇是关于教AI学语言的
Grounded Language Learning in a Simulated 3D World
,另一篇,是关于用形式语言指挥AI智能体行动的
Programmable Agents
。
我们先说说AI学语言这件事。
想想我们每天的生活,AI帮我们做了越来越多的决定,小到看哪些新闻,大到该买什么股票。甚至有时候,还会让AI直接替我们采取行动。
不过,这也带来了一个越来越紧迫的需求:用人话和AI沟通,指挥和引导它们。
也就是说,得让AI
真的懂
人话。
什么是真的懂呢?简单来说,就是让agent能把语言和它的行为、所处的世界关联起来。
DeepMind在论文摘要中用两个词来形容他们想让agent学语言学到什么程度:
grounded,也就是有基础、接地气,能把语言中的词和agent在环境中直接遇到的物品、经历的行为联系起来;
embodied,也就是能具体表达出来的。
但是,让AI学会接地气的语言很难。
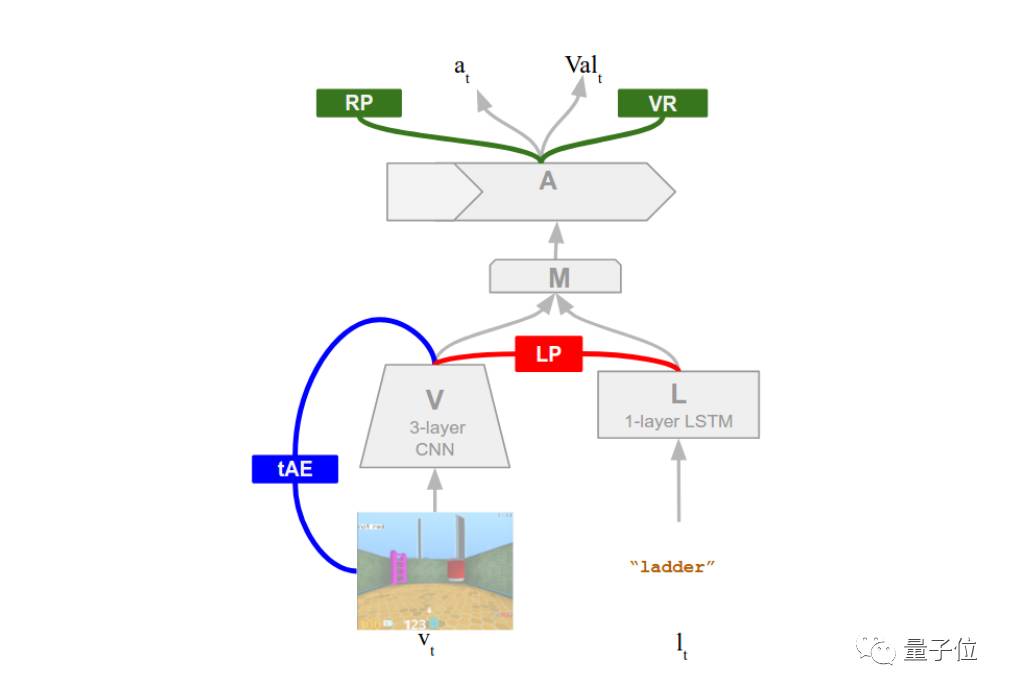
DeepMind这篇论文描述了一个新方法:把agent放在一个虚拟3D环境中,如果它成功地正确执行了用人类语言写成的指令,就给奖励。
他们就是这样,用强化学习和无监督学习相结合,对agent进行训练,让它学习理解人类语言。
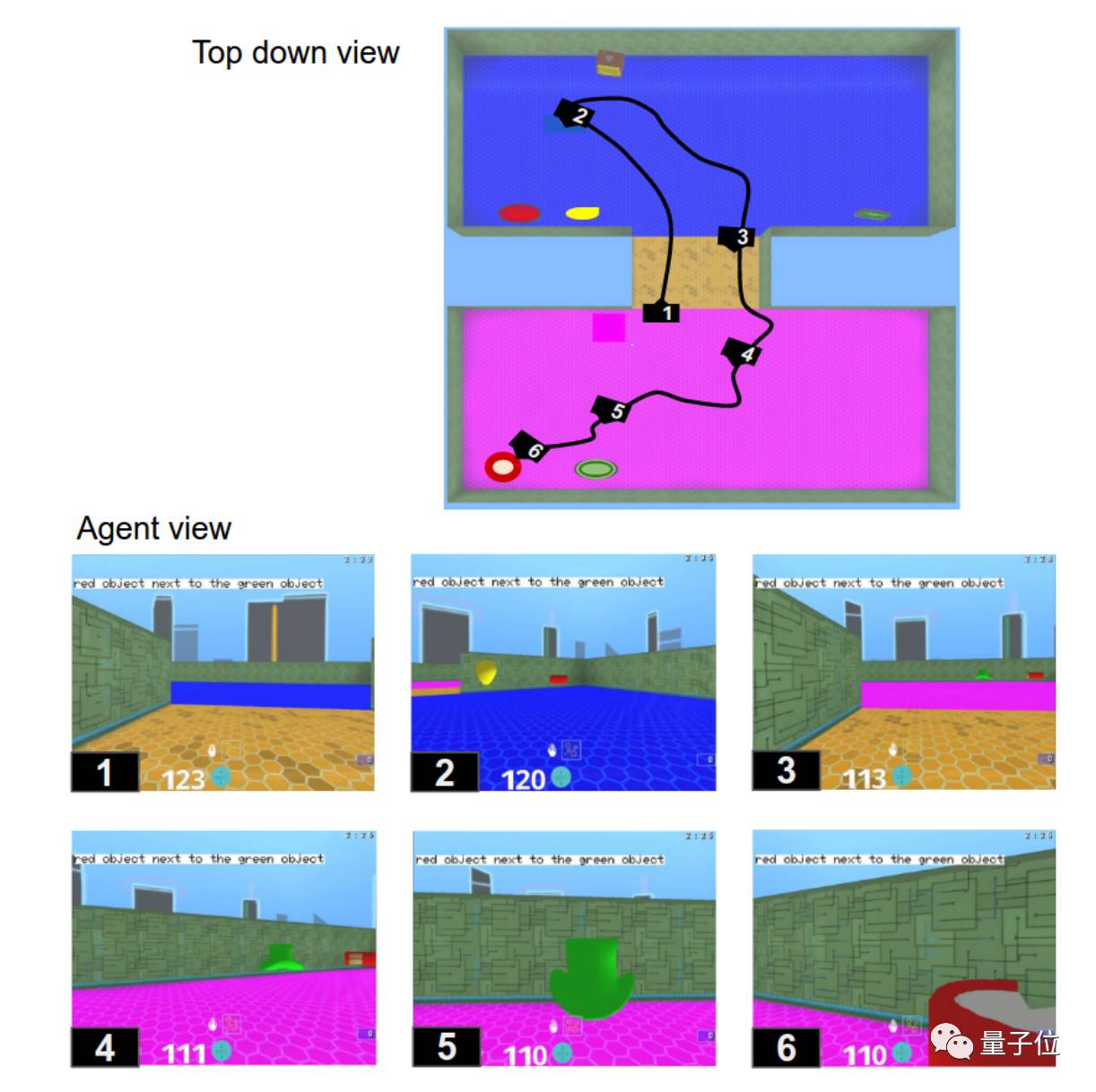
上图是DeepMind论文中所举的例子:一开始agent处于位置1,收到“把绿色物体旁边的红色物体捡起来”的指令,于是它把两个“房间”逛了一遍,去查看房间里的物体及其相对位置,找到了需要捡起来的物体。
这种探索、选择的行为,并没有预先编程,完全是借助激励机制学会的。
这样的探索训练有数十万种变体,agent会遇到不同的房间布局、不同的物体摆放位置等等。
在训练过程中,agent几乎没有先验知识,只是通过将语言符号和它周围物理环境中出现的感知表征和行为序列关联起来,来学习语言。
也正因为agent理解语言不依赖先前的经验,如果研究人员把agent放到一个完全陌生的环境中,用它学过的语言向它发出新的指令,这个agent一样能完成。
DeepMind的研究人员还发现,随着语义知识的积累,agent学习新词的速度越来越快。
他们认为,这种泛化和自我扩展语义知识的能力,说明他们现在所用的方法有潜力让AI agent理解模糊的自然语言与复杂的实体世界之间的关联。
关于具体的训练过程和原理,请移步论文:
Grounded Language Learning in a Simulated 3D World
https://arxiv.org/pdf/1706.06551.pdf
作者:Karl Moritz Hermann, Felix Hill, Simon Green, Fumin Wang, Ryan Faulkner, Hubert Soyer, David Szepesvari, Wojtek Czarnecki, Max Jaderberg, Denis Teplyashin, Marcus Wainwright, Chris Apps, Demis Hassabis, Phil Blunsom
上文提到的训练方法,是在一个3D虚拟环境中,让agent执行人类语言写成的指令。
在DeepMind另一批研究员同日发到Axriv的另一篇论文中,agent执行的是用简单的形式语言写成的指令,不过,这项研究让agent遇到从未见过的物体,也能灵活应对。
这篇论文的题目是:Programmable Agents。经验告诉我们,无论是新闻还是论文,标题越短事儿越大……当然,在AI研究领域,这个规则最近越来越受到怀疑。
我们先来看看这篇论文想让AI做什么。
简单来说,是让agent执行用形式语言表达的描述性程序。
在这项研究中,研究人员所设定的环境是一张大桌子,中间有一支带有6个关节的机械臂,周围有特定数量的积木块,出现在随机位置。
他们所做的,是让虚拟环境中的“机械臂”去够特定颜色、形状的积木,也就是把手(机械臂前端的白色部分),伸到目标积木块的附近。
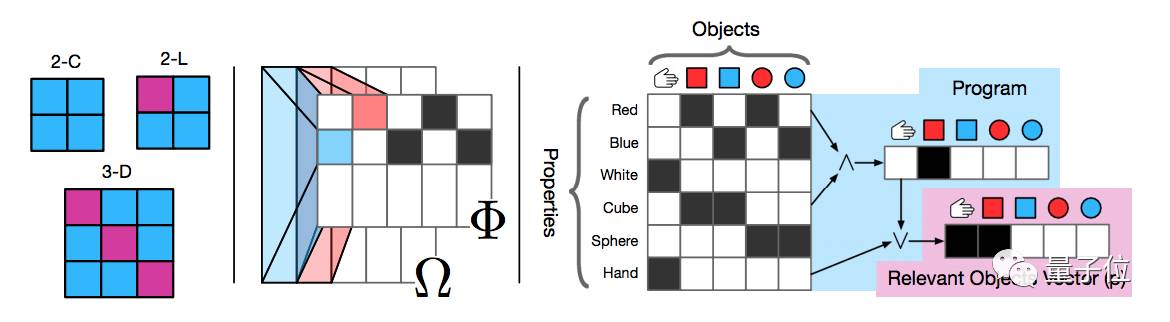
而前面提到的“形式语言描述性程序”,是这样执行的:
NEAR(HAND, AND(RED, CUBE))
,表示把手伸到红色立方体附近。
形式语言中指定的,是目标的颜色和形状。在具体的程序中,桌面的大小、目标的数量也可能发生变化。
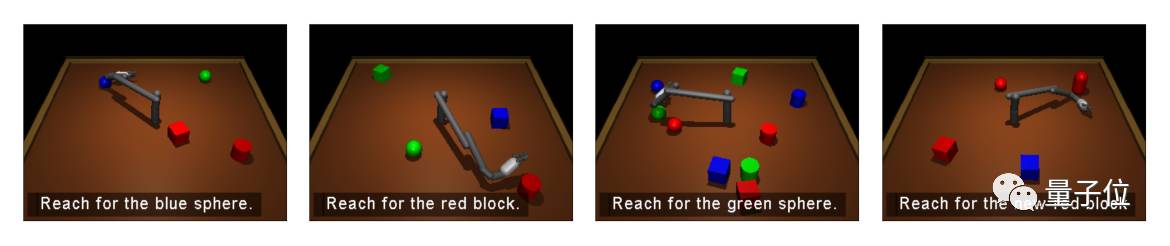
在上图中,最左边一幅的“伸向蓝色球形”是训练环节,其他三幅展示了agent经过这种训练之后的泛化能力,包括目标性质的变化(左二:伸向红色积木)、环境中物体数量的变化(右二:伸向绿色球体,注意这里桌上多了好多积木)、以及新目标性质的出现(右一:伸向新的红色积木)。
DeepMind的这组研究人员称,他们训练的agent学会了根据这种语言的指令在所处环境中找到目标之后,在测试中可以对这种能力进行泛化,执行新的程序,找到在训练中从未提及的目标。他们的agent可以泛化到大范围的zero-shot语义任务。
具体的训练过程和原理,还是请移步论文:
Programmable Agents
https://arxiv.org/pdf/1706.06383.pdf
Misha Denil, Sergio Gómez Colmenarejo, Serkan Cabi, David Saxton, Nando de Freitas
【完】
一则通知
量子位正在组建自动驾驶技术群,面向研究自动驾驶相关领域的在校学生或一线工程师。
李开复、王咏刚、王乃岩
等大牛都在群里。欢迎大家加量子位微信(qbitbot),备注“自动驾驶”申请加入哈~
招聘
量子位正在招募编辑记者、运营、产品等岗位,工作地点在北京中关村。相关细节,请在公众号对话界面,回复:“招聘”。
△
扫码强行关注『量子位』
追踪人工智能领域最劲内容





