第四范式是国际领先的人工智能技术与服务提供商。2016 年 12 月,第四范式成为史上第一家荣获“吴文俊人工智能科学技术奖”创新奖一等奖的企业,该奖被誉为”中国人工智能界最高奖“。2017 年 5 月,第四范式入选"Gartner 2017 Cool Vendor” , 是国内唯一入榜的通用平台型人工智能公司。第四范式自主研发的“第四范式•先知平台”是国内首个成熟商用的人工智能应用者开发平台,工程师甚至是企业业务人员基于先知平台,能够在 1 人月内开发出适用于本行业的人工智能应用。目前,先知平台已经应用于精准营销、个性化推荐、差异化定价、风险管控、智能投顾等多项业务中,为金融、电信、互联网等领域 100 多家企业成功打造人工智能应用。
2016 年年中时期,正是 Spark 火热的时候,我在浏览知乎的时候,发现了这么一个问题:第四范式的人工智能平台 Prophet 有可能替代 Spark 么(https://www.zhihu.com/question/48743915)?看到这个问题,心里马上充满了疑惑,为什么有了 Spark 和 TensorFlow,他们还要去研发一个自己的人工智能平台。当然,当时的人工智能也没有今年这么火。但是我对这个平台充满了好奇。我开始留意第四范式的一切资料,不过在很长一段时间里,我并没有成功的接触到任何一位范式科学家。但是接触和了解这家公司依然一直放在我的任务清单里。也终于在半年后,我有幸找到了胡时伟老师,向他表达了我强烈的想报道“先知”平台的决心,于是,我们有了这么一篇内容:
为什么已有 TensorFlow 和 Spark,第四范式还要开发“先知”平台?
在这篇文章里,胡时伟和涂威威两位老师,给大家介绍了为什么人工智能系统需要高维大规模机器学习模型,以及“先知”产品的架构实践和模型算法工程优化经验。
这次的分享里,总结了一个完整的机器学习系统需要的部分:
以及“先知”的整体架构:
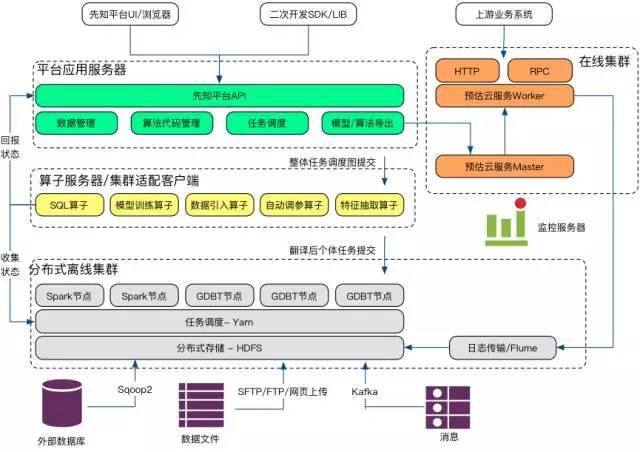
(整体架构图)
另外,涂威威讲了大规模分布式机器学习框架 GDBT,除去计算之外,一个机器学习平台还需考虑的其他因素,比如:通讯、存储、灾备和效率的权衡,还有机器算法框架的语言选择问题。总体来说,这是一次很干货很完整的机器学习平台的技术科普。
今年人工智能开始大火,各大媒体都开始去主动报道第四范式的技术了,也开始看到各种范式科学家的采访文章。随着这些报道,我们也更清楚这家公司的技术实力。而且第四范式也开始注重技术培训,他们发起了“范式大学”的项目,致力于成为“数据科学家”的黄埔军校,校长为第四范式首席科学家,华人界首个国际人工智能协会 AAAI Fellow、唯一的 AAAI 华人执委杨强教授。我由此也再次找到了第四范式,要求他们在 InfoQ 的社群当中组织一次“范式主题月”,给大家更多的讲讲机器学习相关技术。于是有了以下文章。
第四范式联合创始人,产品负责人田枫:机器学习的最小可用产品
想用机器学习提升业务价值,在搭建平台、处理数据、训练算法之前,真正要做的第一步应该是什么?
-
机器学习是不是万能良药?我们首先需要想清楚, 机器学习作为特别牛的技术, 它能解决什么样的问题。
-
一个业务问题,可能有各种千奇百怪的坑,假设我们初步判定可以通过机器学习来解决他,那么应该通过怎样的转化,避开这些坑,把业务问题变成机器学习的问题。
-
如果有一个好的可以转化成机器学习的问题,我怎么去设计机器学习的开发节奏,估算它的投入产出比,如何分阶段去推动问题的建模和应用。
这次分享,基于第四范式在机器学习工业应用方面的大量成功案例和经验,不涉及算法,不涉及平台,但是却是机器学习产生价值过程中最关键的步骤之一。
机器学习的最小可用产品:人工智能应用的敏捷开发
第四范式互联网业务负责人周开拓:手把手教你完成机器学习模型
周开拓老师分享了如何使用大规模机器学习解决真实的业务问题,以基于大规模机器学习模型的推荐系统中的一个指标,即“点击率”作为试点,介绍如何用机器学习来搭建推荐系统的完整过程。
这次分享总结起来是这么几个点:
-
如何使用机器学习来剖析一个问题,我们用了推荐系统的例子。
-
我们如何构造一个推荐系统的样本、数据并进行建模,当我们有一个非常好的机器学习工具的时候,我们可以把精力聚焦在业务上,在怎么找到好的数据上,以及在怎么定义好的目标和规划上。
-
我们描述了机器学习系统是如何和其他系统发挥作用的,机器学习就像发动机,汽车当然需要发动机,但只有发动机车是跑不起来的,你还需要周边的配件,这是系统化的工程。
同时这篇文章阅读人数过万,转发人数过千。
2017 年,你还在用用户画像和协同过滤做推荐系统吗?
第四范式先知平台架构师陈迪豪:打造机器学习的基础架构平台
陈迪豪老师和大家分享《打造机器学习的基础架构平台》的话题,主要介绍了机器学习底层原理和工程实现方面的内容。
基础架构(Infrastructure)相比于大数据、云计算、深度学习,并不是一个很火的概念,甚至很多程序员就业开始就在用 MySQL、Django、Spring、Hadoop 来开发业务逻辑,而没有真正参与过基础架构项目的开发。在机器学习领域也是类似的,借助开源的 Caffe、TensorFlow 或者 AWS、Google CloudML 就可以实现诸多业务应用,但框架或平台可能因行业的发展而流行或者衰退,而追求高可用、高性能、灵活易用的基础架构却几乎是永恒不变的。
Google 的王咏刚老师在《
为什么 AI 工程师要懂一点架构
》提到,研究院并不能只懂算法,算法实现不等于问题解决,问题解决不等于现场问题解决,架构知识是工程师进行高效团队协作的共同语言。Google 依靠强大的基础架构能力让 AI 研究领先于业界,工业界的发展也让深度学习、Auto Machine Learning 成为可能,未来将有更多人关注底层的架构与设计。
因此,这次的主题包括了以下的几个方面:
-
基础架构的分层设计;
-
机器学习的数值计算;
-
TensorFlow 的重新实现;
-
分布式机器学习平台的设计。
根据业务的需求,我们可以选择特定的领域进行深入研究和二次开发,利用轮子和根据需求改造轮子同样重要。
在机器学习与人工智能非常流行的今天,希望大家也可以重视底层基础架构,算法研究员可以 理解更多工程的设计与实现,而研发工程师可以了解更多的算法原理与优化,在合适的基础架构平台上让机器学习发挥更大的效益,真正应用的实际场景中。
从算法实现到 MiniFlow 实现,打造机器学习的基础架构平台
我们在大数据杂谈上曾经发过一篇科普文章:
迁移学习:数据不足时如何深度学习
,讲了迁移学习的基本概念。
“我认为实现人工智能的难度无异于建造火箭。需要有一个强大的引擎,还有大量的燃料。如果空有强大的引擎但缺乏燃料,火箭肯定是无法上天的。如果只有一个单薄的引擎,有再多燃料也无法起飞。如果要造火箭,强大的引擎和大量燃料是必不可少的。以此来类比深度学习的话,深度学习引擎可以看作火箭引擎,而我们为算法提供的海量数据可以看作是燃料。 — Andrew Ng”
我们知道,近年来数据量的迅猛增长和计算能力的提升是推动这一波人工智能热潮的主要原因之一。但在实际业务中,我们会发现在很多情况下,数据量较小,不足以支撑 AI 去解决实际问题。而迁移学习能够通过发现大数据和小数据问题之间的关联,把知识从大数据中迁移到小数据问题中,从而打破人工智能对大数据的依赖。










