运行平台:
Windows
Python版本:
Python3.x
IDE:
Sublime text3
作者:
Jack-Cui
源自:
https://blog.csdn.net/c406495762/article/details/72331737
大家都应该有过从百度文库下载东西的经历,对于下载需要下载券的文章,我们可以办理文库VIP(土豪的选择):

有的人也会在某宝购买一定的下载券,然后进行下载。而另一些勤勤恳恳的人,则会选择上传文章,慢慢攒下载券。任劳任怨的人,则会自己一点一点的复制粘贴,复制到word里文字太大,那就复制到txt文件里。而既不想花钱又不想攒下载券,也不想一点一点复制粘贴的人,会选择“冰点文库”这样的下载软件,不过貌似现在“冰点文库”已经不能使用了。当然,还有一些其他破解方法,比如放到手机的百度文库APP里,另存为文章,不需要下载券就可以下载文章。诸如此类的方法,可谓五花八门。而对于学习爬虫的人来说,面对怎样免费下载一个付费的word文章的问题,第一个想到的应该就是:自己写个程序搞下来。
我们以如何下载下面这篇文章为例,分析问题:
URL :
https://wenku.baidu.com/view/aa31a84bcf84b9d528ea7a2c.html
![]()
看到这样的一个文章,如果爬取当前页面的内容还是很好爬的吧。
感觉so easy!至少我当时是这么想的,但是当把文章翻到最下方的时候,我看到了如下内容:
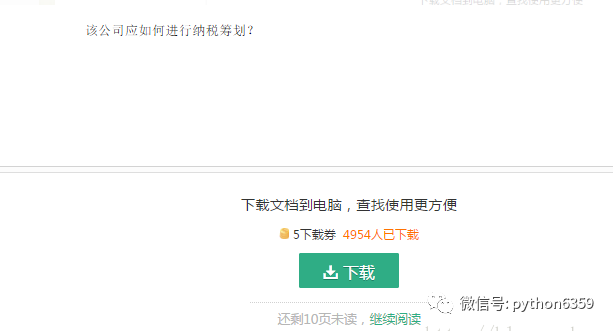
需要点击“继续阅读”才能显示后续的内容,我单爬这一页内容,是爬不到后续的内容的。第一个想到的方法是,抓包分析下,然后我又一次蒙逼了:
Request URL这么长!!最后的expire时间信息好解决,其他的信息呢?不想做无谓的挣扎,因此,我果断地放弃这个方法。
问题:
获取当前页的内容好办,怎么获取接下来页面的内容?
带着这个思考,Selenium神器走入了我的视线。
Selenium
Selenium 是什么?一句话,自动化测试工具。它支持各种浏览器,包括 Chrome,Safari,Firefox 等主流界面式浏览器,如果你在这些浏览器里面安装一个 Selenium 的插件,那么便可以方便地实现Web界面的测试。换句话说叫 Selenium 支持这些浏览器驱动。Selenium支持多种语言开发,比如 Java,C,Ruby等等,而对于Python,当然也是支持的!
安装
pip install selenium
详细内容可查看官网文档:
http://selenium-python.readthedocs.io/index.html
1
/
小试牛刀
我们先来一个小例子感受一下 Selenium,这里我们用 Chrome 浏览器来测试。
from
selenium import webdriver
browser = webdriver.Chrome()
browser.
get
(
'http://www.baidu.com/'
)
运行这段代码,会自动打开浏览器,然后访问百度。
如果程序执行错误,浏览器没有打开,那么应该是没有装 Chrome 浏览器或者
Chrome 驱动
没有配置在环境变量里。下载驱动,然后将驱动文件路径配置在环境变量即可。
驱动下载地址:https://sites.google.com/a/chromium.org/chromedriver/downloads
windows下设置环境变量的方法:
win+r
,输入
sysdm.cpl
,点击确定,出现如下对话框:
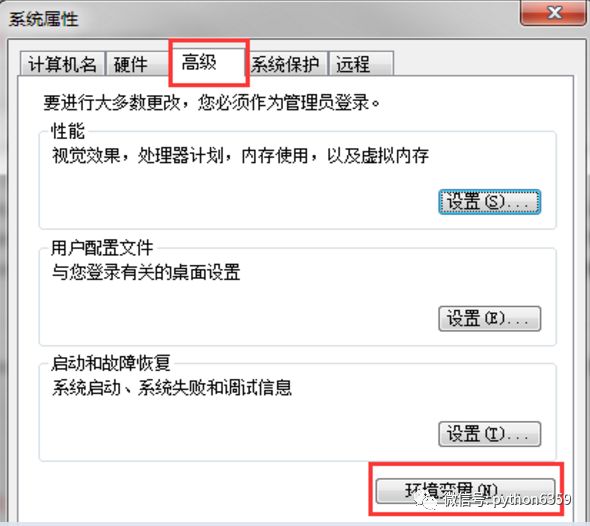
选择高级->环境变量。在系统变量的Path变量中,添加驱动文件路径即可(注意:分号)。
Linux的环境变量也好设置,在
~/.bashrc
文件中export即可,记得
source ~/.bashrc
。
当然,你不设置环境变量也是可以的,程序可以这样写:
from
selenium import webdriver
browser = webdriver.Chrome(
'path\to\your\chromedriver.exe'
)
browser.
get
(
'http://www.baidu.com/'
)
path\to\your\chromedriver.exe
是你的chrome驱动文件位置,可以使用绝对路径。
我们通过驱动的位置传递参数,也可以调用驱动,结果如下图所示:
2
/
模拟提交
下面的代码实现了模拟提交提交搜索的功能,首先等页面加载完成,然后输入到搜索框文本,点击提交,然后使用page_source打印提交后的页面的信息。
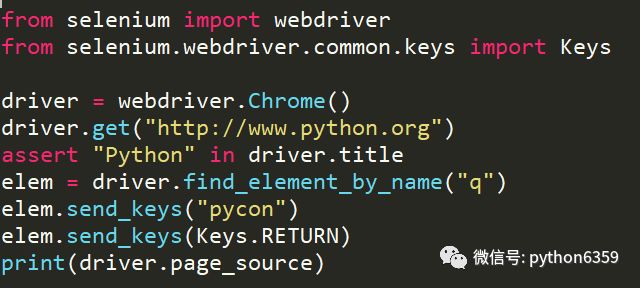
全自动的哦,程序操控!是不是很酷炫?
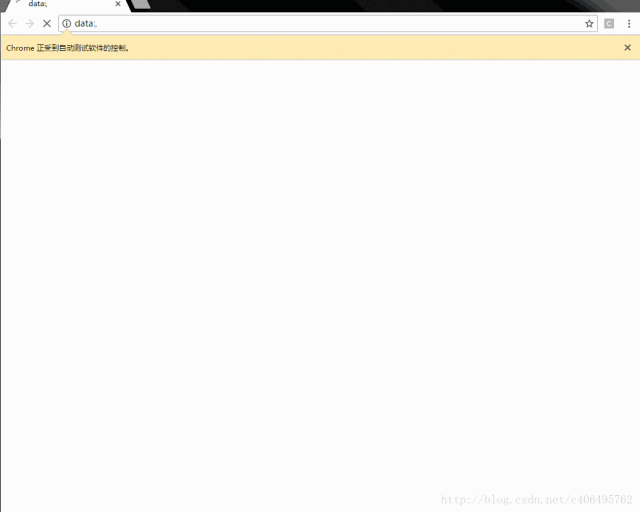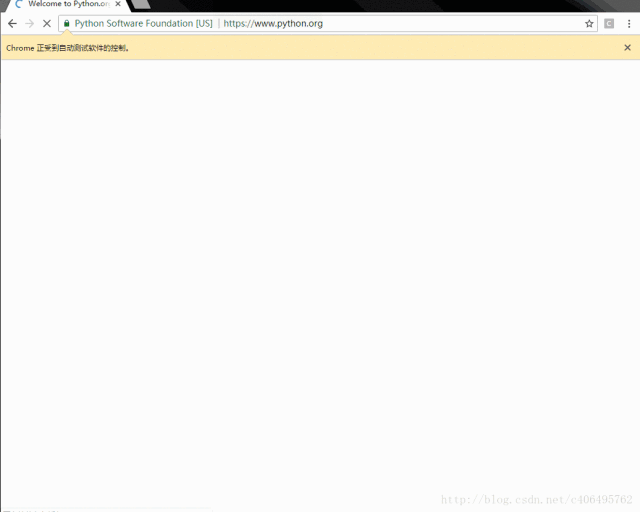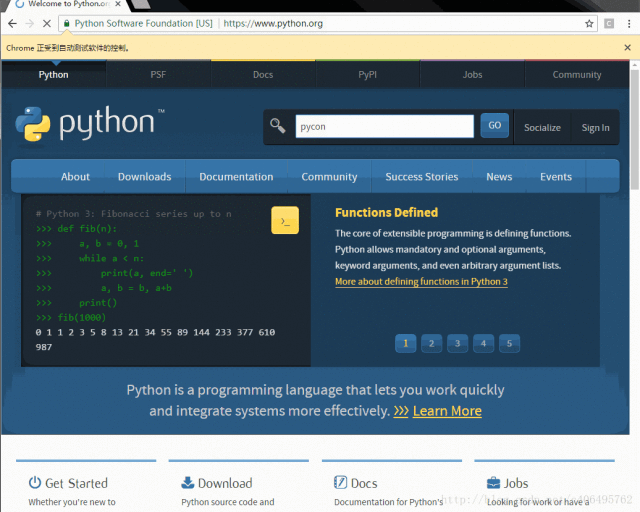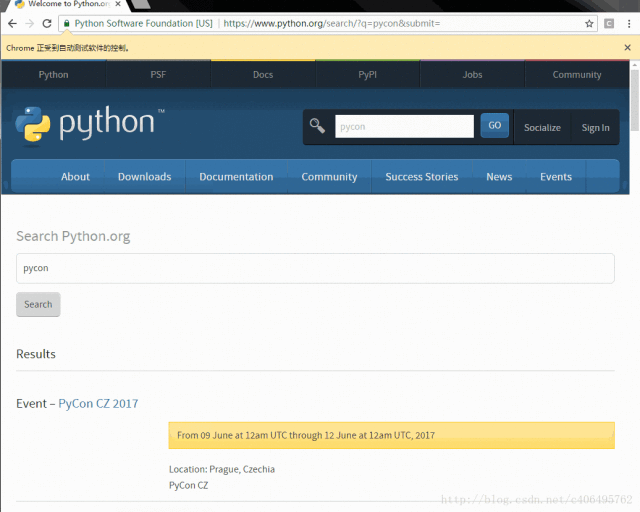
其中 driver.get 方法会打开请求的URL,WebDriver 会等待页面完全加载完成之后才会返回,即程序会等待页面的所有内容加载完成,JS渲染完毕之后才继续往下执行。注意:如果这里用到了特别多的 Ajax 的话,程序可能不知道是否已经完全加载完毕。
WebDriver 提供了许多寻找网页元素的方法,譬如
find_element_by_*
的方法。例如一个输入框可以通过
find_element_by_name
方法寻找 name 属性来确定。
然后我们输入来文本然后模拟点击了回车,就像我们敲击键盘一样。我们可以利用 Keys 这个类来模拟键盘输入。
最后最重要的一点是可以获取网页渲染后的源代码。通过,输出
page_source
属性即可。这样,我们就可以做到网页的动态爬取了。
3
/
元素选取
关于元素的选取,有如下API:
单个元素选取:
find_element_by_id
find_element_by_name
find_element_by_xpath
find_element_by_link_text
find_element_by_partial_link_text
find_element_by_tag_name
find_element_by_class_name
find_element_by_css_selector
多个元素选取:
find_elements_by_name
find_elements_by_xpath
find_elements_by_link_text
find_elements_by_partial_link_text
find_elements_by_tag_name
find_elements_by_class_name
find_elements_by_css_selector
另外还可以利用 By 类来确定哪种选择方式:
from
selenium.webdriver.common.
by
import
By
driver.find_element(
By
.XPATH,
driver.find_elements(
By
.XPATH,
By类的一些属性如下:
ID =
"id"
XPATH =
"xpath"
LINK_TEXT =
"link text"
PARTIAL_LINK_TEXT =
"partial link text"
NAME =
"name"
T
AG_NAME =
"tag name"
CLASS_NAME =
"class name"
CSS_SELECTOR =
"css selector"
这些方法跟JavaScript的一些方法有相似之处,
find_element_by_id
,就是根据标签的
id属性查找元素,
find_element_by_name
,就是根据标签的name属性查找元素。
举个简单的例子,比如我想找到下面这个
元素:
type
=
"text"
name=
"passwd"
id=
"passwd-id"
/>
我们可以这样获取它:
element =
driver.find_element_by_id(
"passwd-id"
)
element =
driver.find_element_by_name(
"passwd"
)
element =
driver.find_elements_by_tag_name(
"input"
)
element =
driver.find_element_by_xpath(
"//input[@id='passwd-id']"
)
前三个都很好理解,最后一个xpath什么意思?这个无需着急,xpath是非常强大
的元素查
找方式,使用这种方法几乎可以定位到页面上的任意元素,在后面我会
进行单独讲解。
4
/
界面交互
通过元素选取,我们能够找到元素的位置,我们可以根据这个元素的位置进行相应的事件操作,例如输入文本框内容、鼠标单击、填充表单、元素拖拽等等。由于篇幅原因,我就不一一讲解了,主要讲解本次实战用到的鼠标单击,更详细的内容,可以查看官方文档。
elem = driver
.find
_element_by_xpath(
"//a[@data-fun='next']"
)
elem
.click
()
比如上面这句话,我使用
find_element_by_xpath()
找到元素位置,暂且不用理会这句话什么意思,暂且理解为找到了一个按键的位置。然后我们使用click()方法,就可以触发鼠标左键单击事件。是不是很简单?但是有一点需要注意,就是在点击的时候,元素不能有遮挡。什么意思?就是说我在点击这个按键之前,窗口最好移动到那里,因为如果这个按键被其他元素遮挡,click()就触发异常。因此稳妥起见,在触发鼠标左键单击事件之前,滑动窗口,移动到按键上方的一个元素位置:
page = driver.find_elements_by_xpath(
"//div[
@class
='page']"
)
driver.execute_script(
'arguments[0].scrollIntoView();'
, page[-
1
])
#拖动到可见的元素去
上面的代码,就是将窗口滑动到page这个位置,在这个位置,我们能够看到
我们需要点
击的按键。
5
/
添加User-Agent
使用webdriver,是可以更改User-Agent的,代码如下:

使用Android的User-Agent打开浏览器,画风是这样的

Selenium就先介绍这么多,对于本次实战内容,已经足够。那么接下来,让我们聊聊xpath。
这个方法是非常强大的元素查找方式,使用这种方法几乎可以定位到页面上的任意元素。在正式开始使用XPath进行定位前,我们先了解下什么是XPath。XPath是XML Path的简称,由于HTML文档本身就是一个标准的XML页面,所以我们可以使用XPath的语法来定位页面元素。
假设我们现在以图所示HTML代码为例,要引用对应的对象,XPath语法如下:
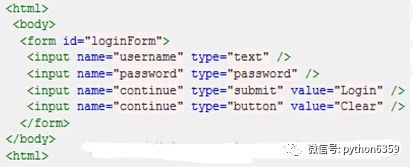
绝对路径写法(只有一种),写法如下:
引用页面上的form元素(即源码中的第3行):
/html/
body
/form[
1
]
注意
-
元素的xpath绝对路径可通过firebug直接查询。
-
一般不推荐使用绝对路径的写法,因为一旦页面结构发生变化,该路径也随之失效,必须重新写。
-
绝对路径以单/号表示,而下面要讲的相对路径则以
//
表示,这个区别非常重要。另外需要多说一句的是,当xpath的路径以
/
开头时,表示让Xpath解析引擎从文档的根节点开始解析。当xpath路径以
//
开头时,则表示让xpath引擎从文档的任意符合的元素节点开始进行解析。而当
/
出现在xpath路径中时,则表示寻找父节点的直接子节点,当
//
出现在xpath路径中时,表示寻找父节点下任意符合条件的子节点,不管嵌套了多少层级(这些下面都有例子,大家可以参照来试验)。弄清这个原则,就可以理解其实xpath的路径可以绝对路径和相对路径混合在一起来进行表示,想怎么玩就怎么玩。
下面是相对路径的引用写法:

Xpath功能很强大,所以也可以写得更加复杂一些,如下面图所示的HTML源码。
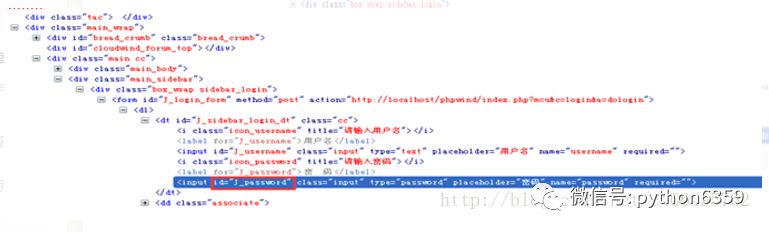
如果我们现在要引用id为“J_password”的input元素,该怎么写呢?我们可以像下面这样写:
/
/*[@id='J_login_form']/dl/dt/input
[
@id
=
'J_password'
]
也可以写成:
//
*[
@id
=
'J_login_form'
]
/*/
*/input[
@id
=










