本文内容非商业用途可无需授权转载,请务必注明作者及本微信公众号、微博ID:唐僧_huangliang,以便更好地与读者互动。
关于新一代
Xeon SP
服务器平台的东西写了一些,其中
7
月
11
日整理的《
Intel Xeon Scalable
处理器资料抢先看:存储应用、
HPC
性能提升
》中有些高性能计算方面的测试对比。当时有朋友留言说为什么只列出资料没有解析?主要是那天时间关系,以及数字还不够全面,一直再等待更有价值的资料。
今天我看到一份《
Performanceand Energy Efficiency of Dell PowerEdge servers with Skylake-SP
》,觉得值得拿出来跟大家分享了,当然也包含我个人的理解分析。总的原则就是高中化学老师常说的一句话——“结构决定性质”,
从性能测试数字反过来看
CPU
设计
,我觉得比单纯研究理论更有实际意义吧:)
在这份白皮书中包含的测试项目有:
SPECint_rate_base2006
整数计算、
SPECfp_rate_base2006
浮点计算、
Linpack
高性能计算、
STREAM
内存带宽、
SPECpower_ssj2008
电源效率、
SPECjbb2015 Java
虚拟机,以及
SAP SD Two-Tier ERP BenchMark
。
CPU
统一采用顶级的
XeonPlatnium
(白金)
8180
,
24
条
16GB DDR4-2667
内存(
SAP
测试使用
24 x 32GB
内存)。
1
、
Xeon SP vs. Xeon E5 v4
核心效率计算
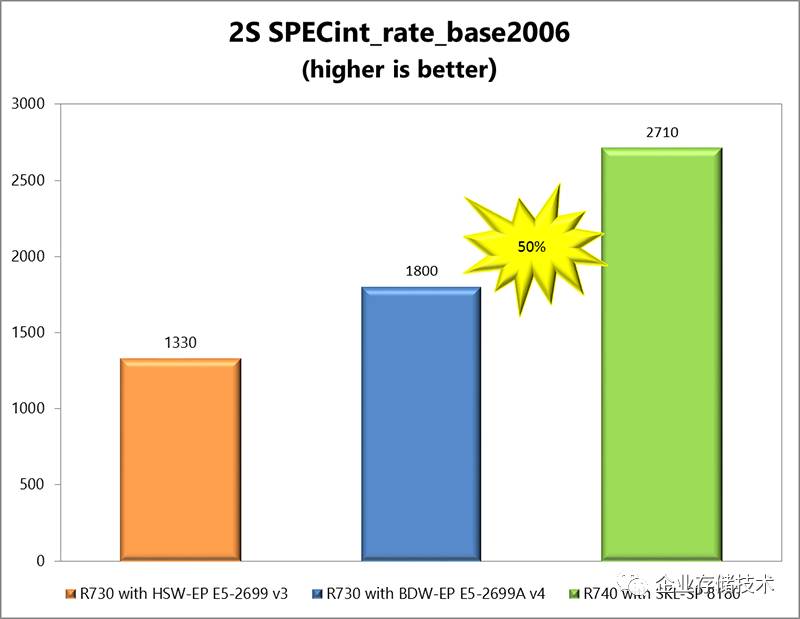 对比测试平台为
R740
和上一代的
R730
,服务器设计可以参考《
Dell PowerEdge R740xd
解析:服务器只看参数那就错了
》
对比测试平台为
R740
和上一代的
R730
,服务器设计可以参考《
Dell PowerEdge R740xd
解析:服务器只看参数那就错了
》
单从
SPECint_rate
多线程整数测试来看,
2
颗
Xeon Platnium 8180
比上一代最高端的
E5-2699A
提升了
50%
。考虑到是
28
核
vs. 22
核,另外
Xeon 8180
全部核心
Non-AVX Turbo
频率可达
3.2GHz
,而
E5-2699 V4
对应频率只有
2.8GHz
(
E5-2699A
基础频率比
2699
高
0.2GHz
,没有查到详细的
Turbo
水平,有了解的朋友可以给我留言),
两代
CPU
王者的整数计算核心效率很可能是相当接近的
。
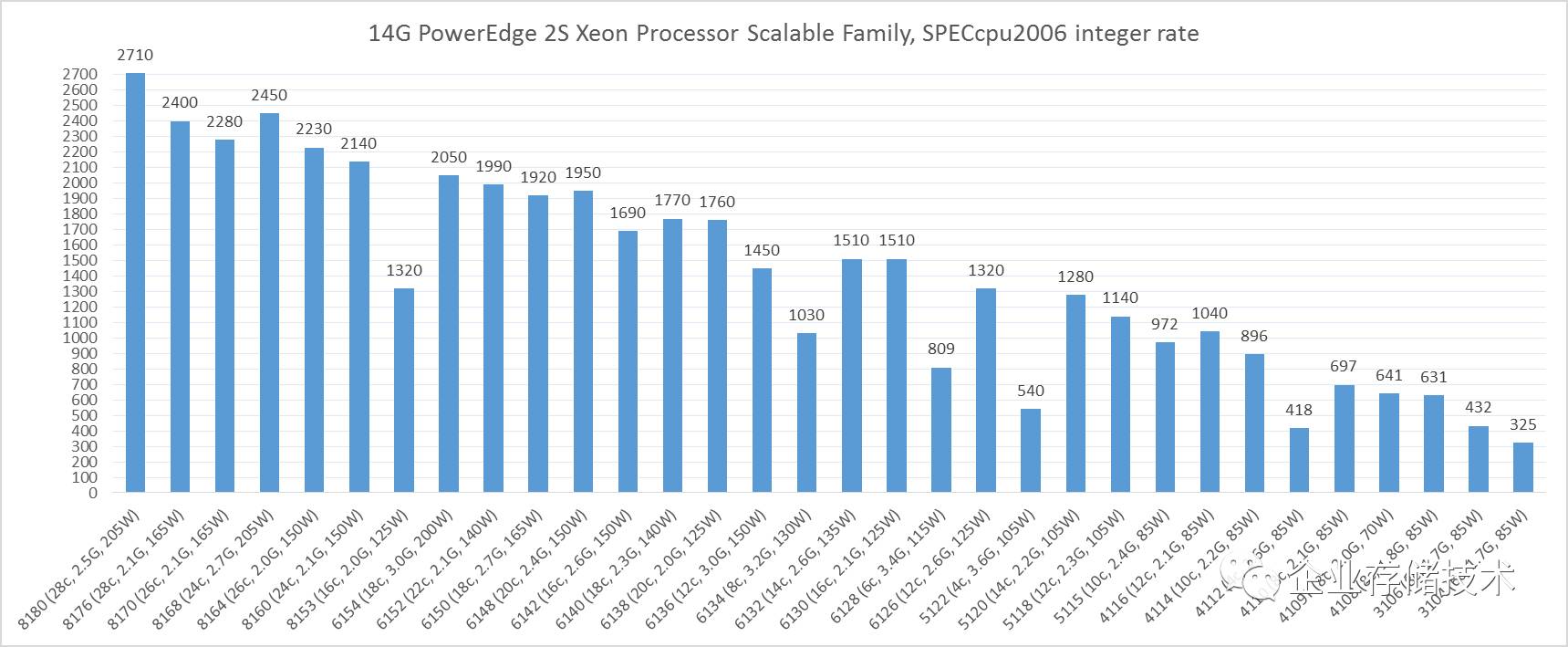
Intel Xeon Processor Scalable
全系列
SPECint_rate
测试对比(点击放大,以下同)
这份白皮书中没有注明
fp2006
编译是否利用到
AVX-512
的价值,猜测可能发挥还不充分?具体原因可以和下文中的
Linpack
测试参照对比。(
扩展阅读:《
IntelSkylake-SP
处理器评测(二)
》
)
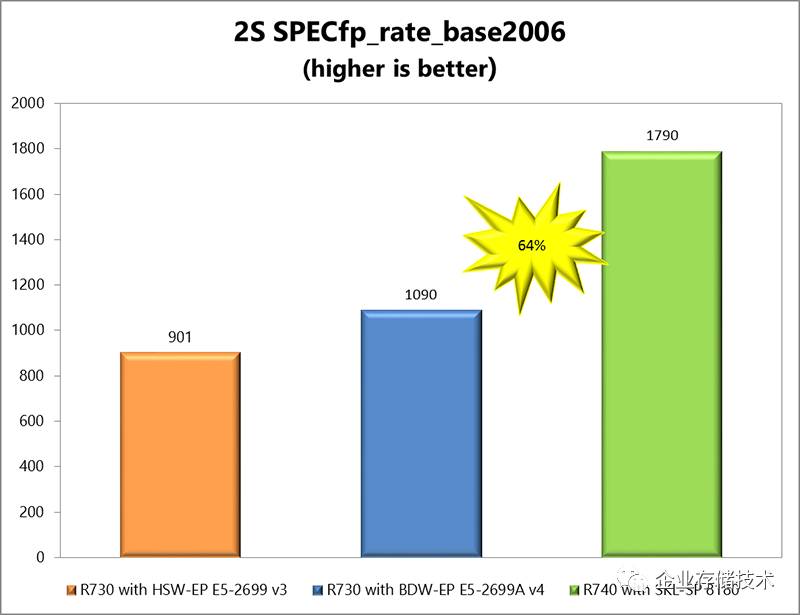
再来看看浮点性能,这里
Xeon Platnium 8180
比
E5-2699A
提升幅度达到了
64%
。除了核心数量之外,
Xeon 8180
全部核心
AVX 2.0
和
AVX-512 Turbo
频率分别为
2.8GHz
和
2.3GHz
,
E5-2699 V4
对应的
AVX Turbo
频率是
2.6GHz
(
E5-2699A
同样不详),这样来看
新一代
CPU
浮点单元设计改进带来的价值还是明显的
。
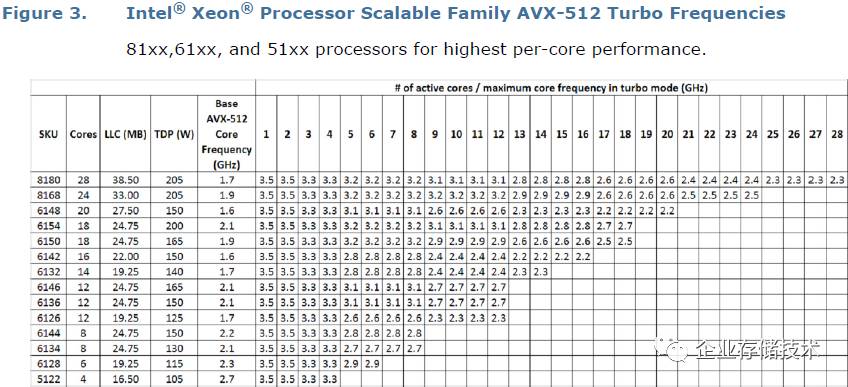
标称
2.5GHz
的
XeonPlatnium 8180
的
基础
AVX-512
频率只有
1.7GHz
,此时
28
核最大
Turbo
也只能达到
2.3GHz
。
关于
Intel CPU
在
执行
AVX
指令时频率有所降低的情况,我在《
低延时应用
&
服务器
TurboBoost
不可得兼?
》一文中曾经介绍过
DPAT
技术
。可以在多路服务器中只有部分
CPU
运行
AVX
代码时,
设置不同
CPU
运行在各自的频率模式下
,以发挥最大效率。
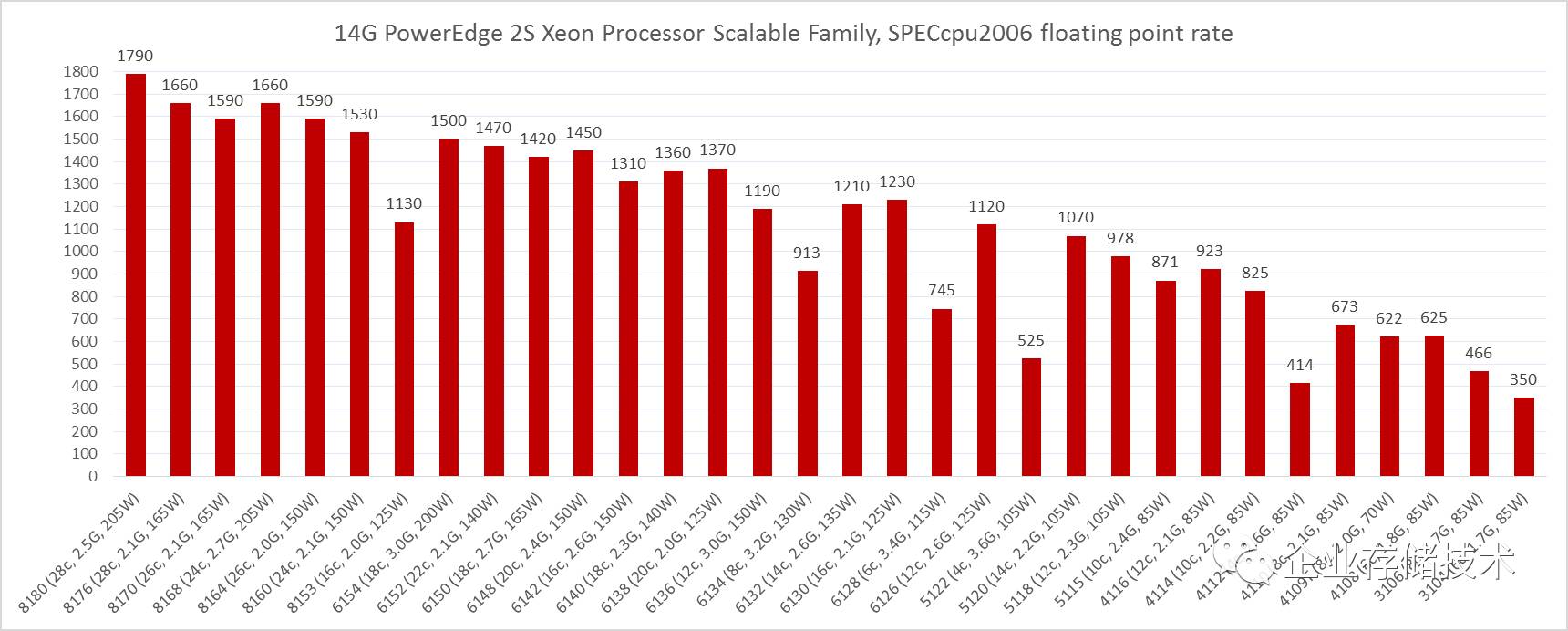
Intel Xeon Processor Scalable
全系列
SPECfp_rate
测试对比
2
、单
/
双
FMA
浮点单元显著影响
HPC
性能
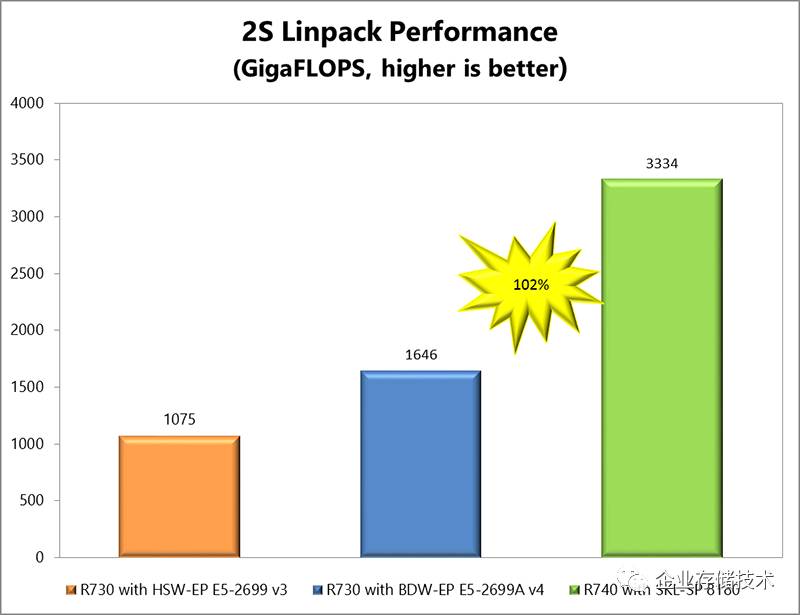
在高性能计算行业流行的
Linpack
测试中,
Xeon Platnium 8180
比
E5-2699A
提高了
1
倍之多
,这里
Dell
也强调了新的
AVX-512
矢量引擎。
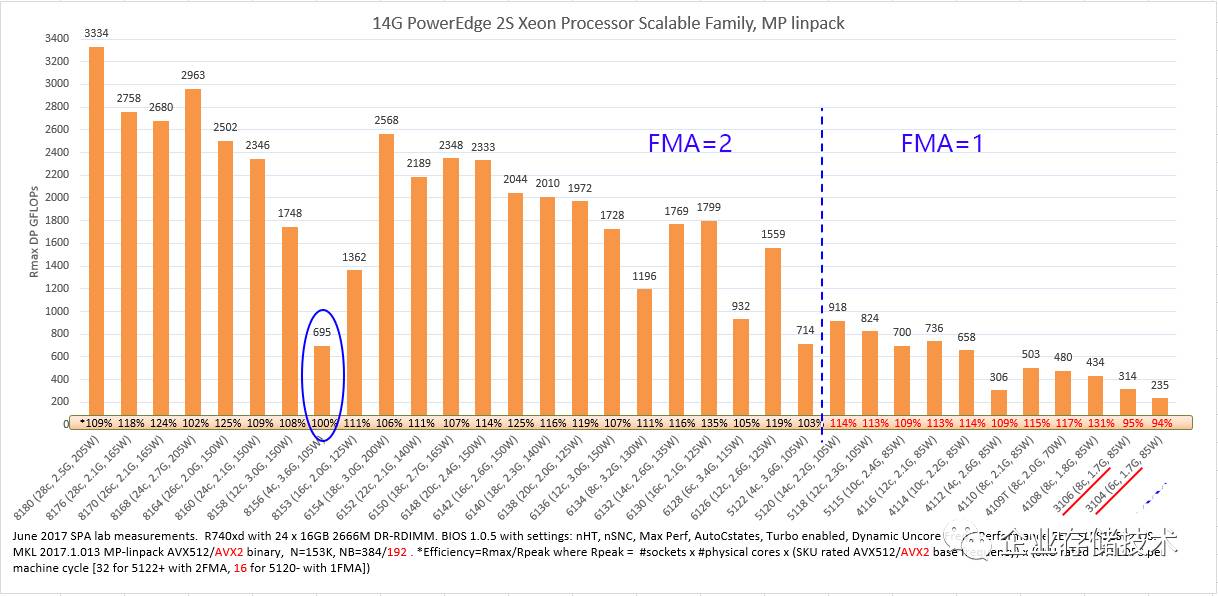
Intel Xeon Processor Scalable
全系列
MP Linpack
测试对比
这个图表稍微展开讲一点。首先除了
Linpack
值之外横坐标轴上还标注了一个
效率
值。下面的注释中介绍了计算方法——
Rmax
(实测)
/Rpeak
(理论值)
,其中
Rpeak=
插槽数
x
物理核心
x AVX512/AVX2
基础频率
x
每机器周期
双精度浮点运算
次数(
Xeon 5122
及以上的
2FMA
型号为
32
,
5120
及以下的
1FMA
为
16
)。
于是我在中间标了一条蓝色虚线,用来区隔
FMA
(
Fused Multiply-Add
,浮点混合乘加运算引擎)的数量。在相近核心数量和主频的情况下,位于
虚线右边的
CPU Linpack
性能大约只有左边的一半
,大家知道做
HPC
该选哪些了吧?
我们看到
Xeon SP
的这个效率值普遍高于
100%
,例外的有两款
6/8
核心的
Xeon Bronze 31xx
低端型号。

从上图可以看出从
Haswell & Broadwell
(
Xeon E5 v3
和
v4
)到
Skylake-SP
之间的变化。上一代
AVX2
指令集提供了
2
个
256-bit
浮点
FMA
,而新一代
Xeon SP
则是
1-2
个
512-bit FMA
。
3
、内存带宽:为什么核心数量少的差?
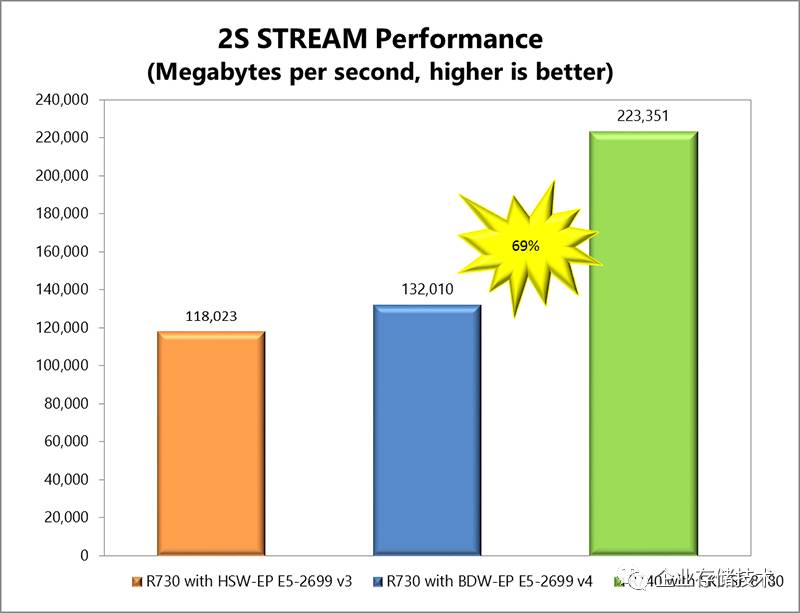
关于这部分使用的测试工具,我在一年前的《
一项
Xeon E5-2600v4
测试数据的背后
》中已经有过介绍,甚至下面要提出的问题都已经有了讨论结果。而这并不影响我们了解新一代
CPU
的内存带宽,
2
颗
8180
的
223.351GB/s
比
E5-2699 v4
提高了
69%
。从
2012
年第一代
Xeon E5
推出就是
4
个内存通道,到上一代
v4
支持
DDR4-2400
;
Xeon SP
提升到
6
通道
DDR4-2667
,算下来实测效率与理论设计比较接近
。
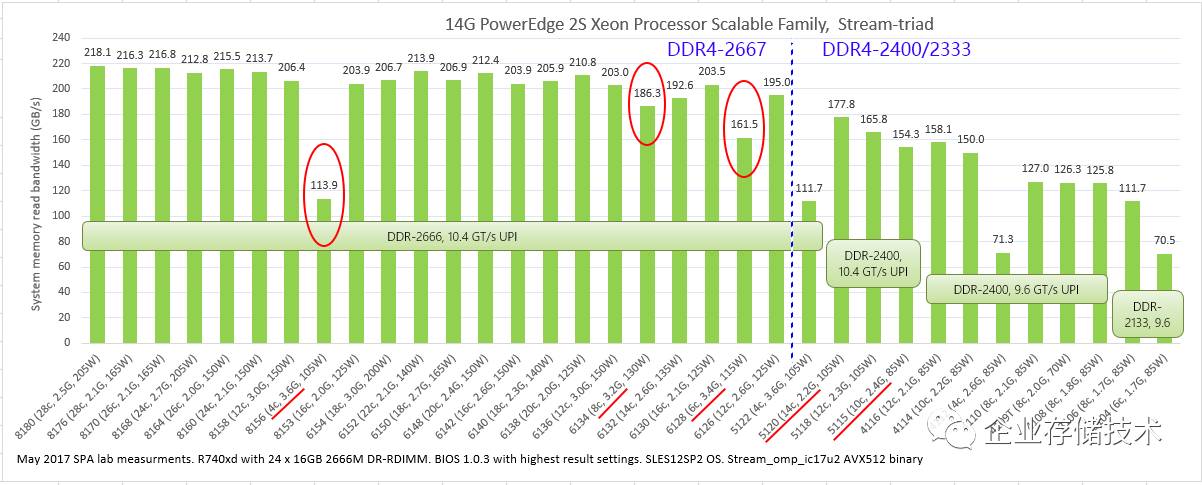
Intel Xeon Processor Scalable
全系列
Stream-triad
测试对比
上图中我用红圈标出几个内存带宽测试偏低的代表,分别还是
4
、
6
、
8
核心
Xeon SP
中表现最好的型号。在继续讨论之前,我们有必要先看看上一代
Xeon E5 v4
中出现的类似情况。
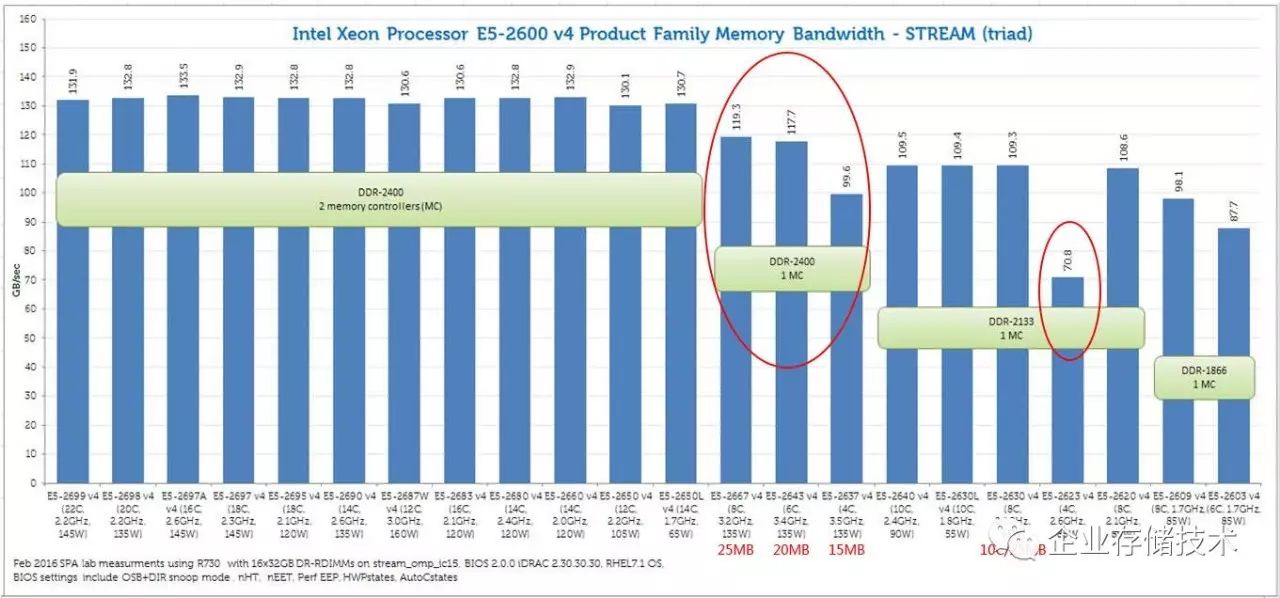
上图表为双路E5-2600 v4服务器测试结果
在《
一项
Xeon E5-2600v4
测试数据的背后
》一文中,我曾经提到过同样标注
76.8GB/s
内存带宽的
CPU
中,有的实测性能偏低,于是这一代
ark.intel.com
上都不标了(
/
笑)。
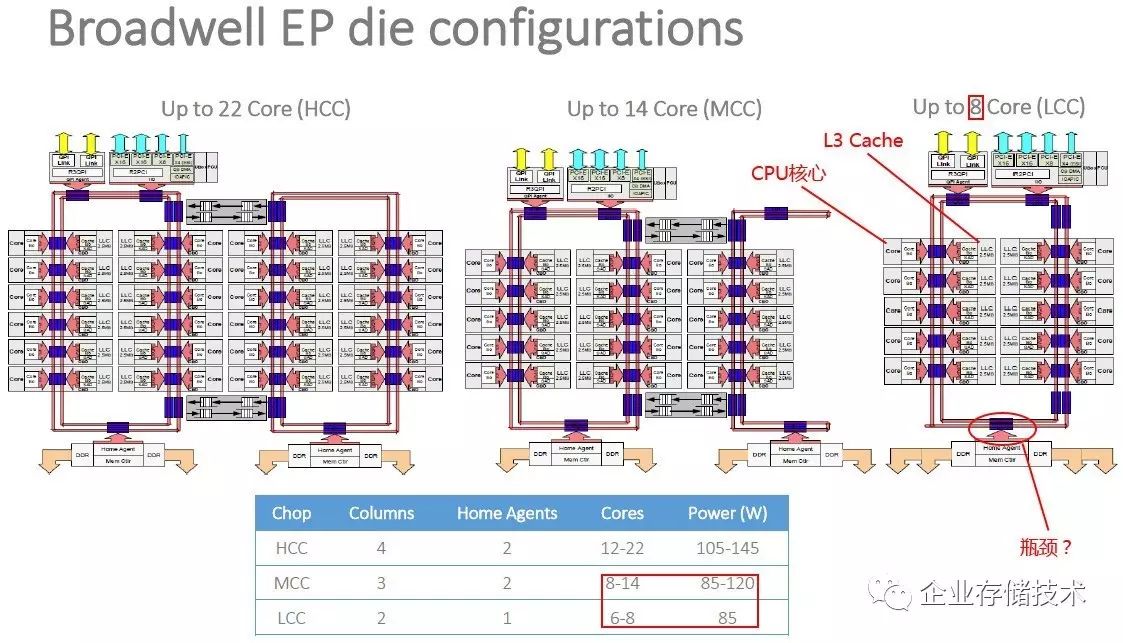
根据上面的
CPU
设计我进行过粗浅的分析,当时的过程大家可以点击链接阅读,我在这里就不重复了,重点是下面对
Xeon SP
的讨论。
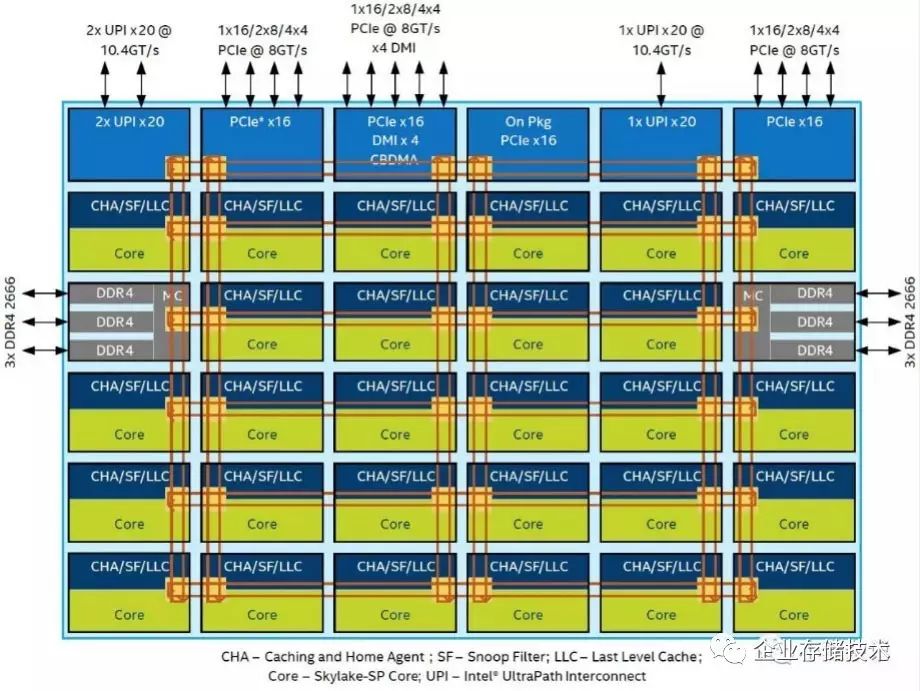
这两张图引用自小麦老师的《
为什么
Xeon SP
叫“可扩展处理器”?
》
“
网格互连
”这张图已经不新鲜,我在《
AMD EPYC
官方资料乌龙?谈服务器
CPU
互连效率
》一文中就引用过。这里重点看左右
2
个
3
通道
DDR4
内存控制器,上图是
28
核心
Xeon SP
的示意。
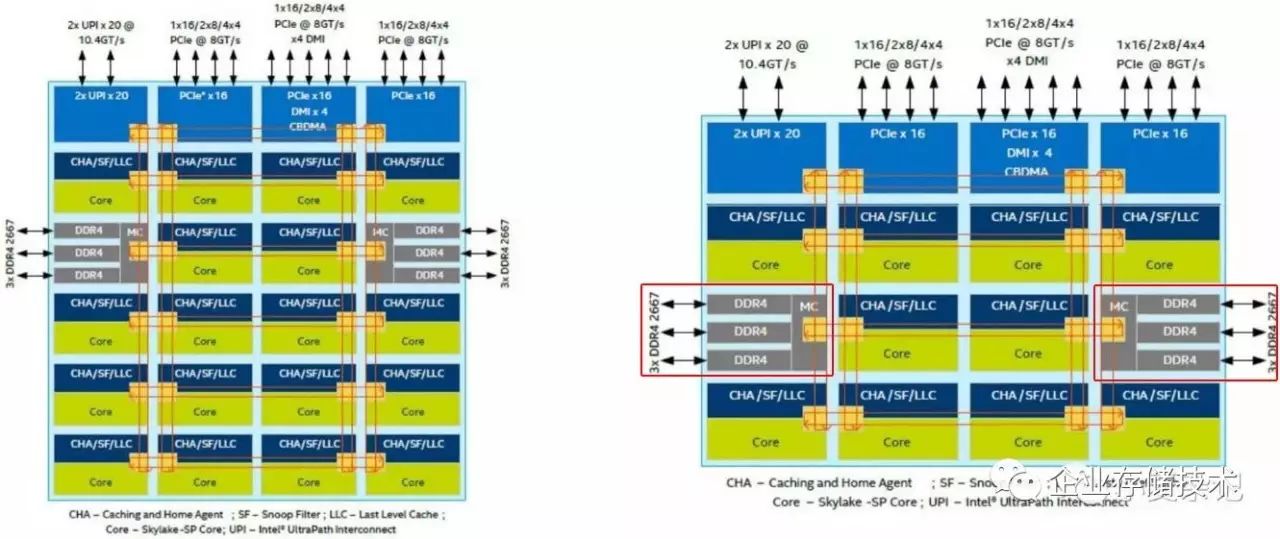
上图则是
18
核心和
10
核心的另外两种设计,单纯看
内存控制器部分应该与更多核心的
Xeon SP
型号相同
。所以这部分的结论也比较简单——
Cache
容量在一定程度上影响了
CPU
内存带宽的发挥
。我们知道
Skylake
这一代服务器的每核心
L2Cache
容量提升,而
L3 Cache
降低,所以我不再将问题主要归咎于
L3 Cache
。
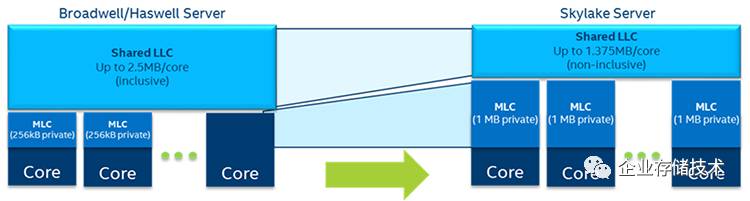
由
Xeon E5 v3/v4
到
Xeon SP
,每核心专用
MLC
(
L2 Cache
)容量从
256KB
增加到
1MB
,而共享
LLC
(
L3 Cache
)则从每核心
2.5MB
降低到
1.375MB
,总体效率应该有提高。
4
、电源效率:为什么要对比四路服务器?
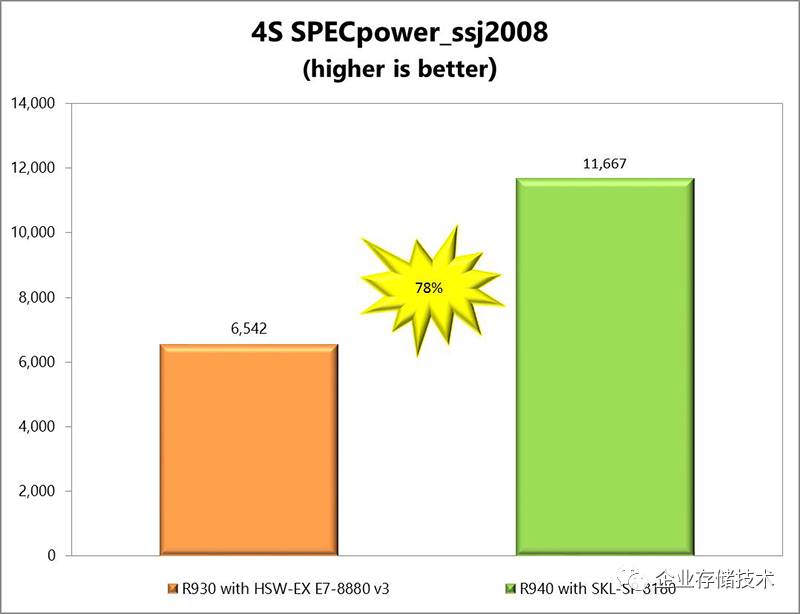
在看到
78%
提升的同时,我们还注意到对比平台换成了四路的
R940
(参见《
Dell PowerEdge R940
解析:四路顶配服务器维护平民化
》)和
R930
,
Xeon Platnium
本身就支持
4-8
路。
这里不做详细分析,只讨论一点——为什么对比四路而不是双路平台。如果您看过《
四路
Xeon SP
服务器内存减半:
Intel
葫芦里卖的什么药?
》可能想到原因了吧?新一代四路
Xeon SP
不需要大量的
SMI2
内存桥接芯片
,
CPU
整合的内存控制器直连
DIMM
,所以更加
省电
哦:)
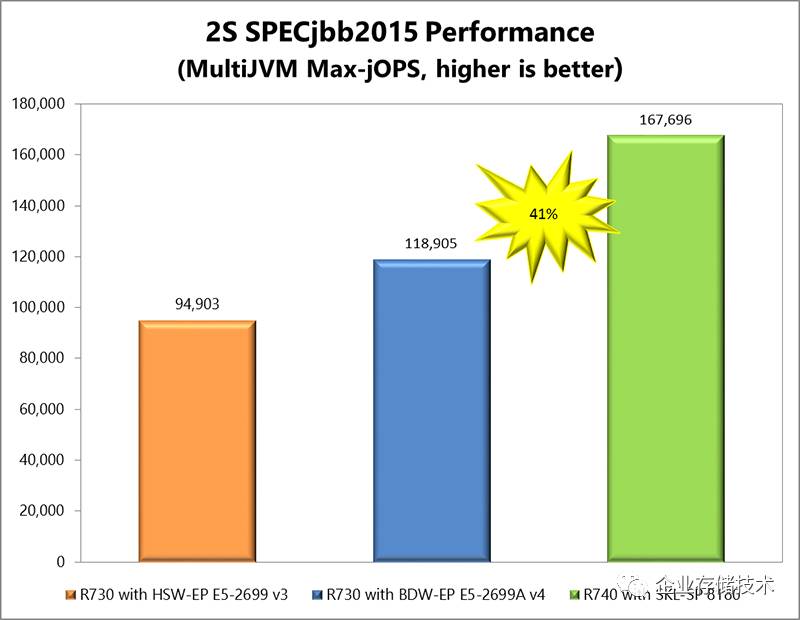
SPECjbb2015
是
贴近实际应用的
JVM
测试
,瓶颈不完全在于
CPU
,
XeonPlatnium 8180
的领先幅度没有前面单纯的计算
/
内存带宽
Benchmark
那么大了。
5
、
SAP SD2 ERP
测试:创造新纪录无悬念
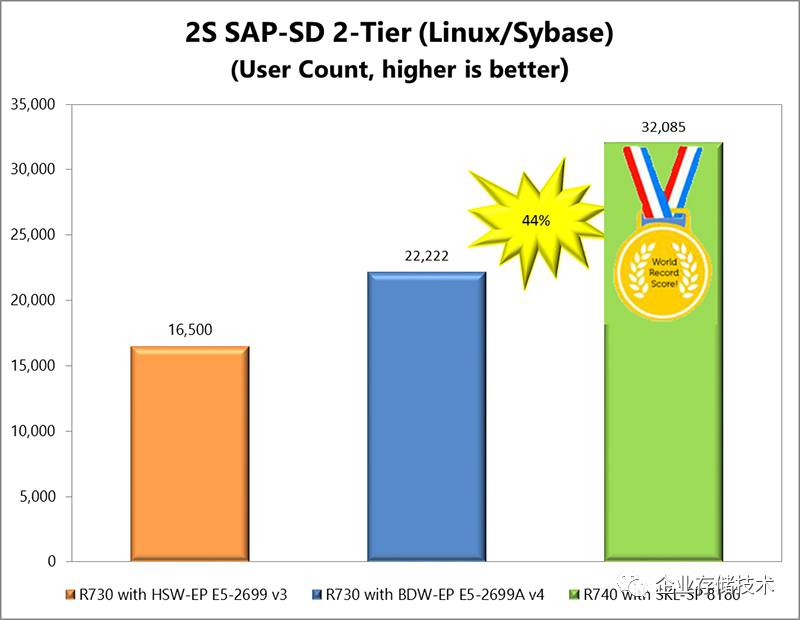
SAP-SD 2-Tier
全称为
Sales andDistribution (SD) Standard Application Benchmark
,两层
Internet
配置(简称
SD2
)。该测试衡量的是
ERP
软件的处理性能
,支持多种操作系统和后端关系型数据库,上面图表引用的都是
SAP
网站公布的数值,运行了
Linux
系统和
Sybase ASE
数据库。
配置
Xeon Platnium 8180
的
PowerEdge R740
服务器,
SD2
测试
32,085
用户数比上一代
R730
提高了
44%
。做为参考,我还查看了四路
PowerEdge R930
的最高测试结果为
43,300
,而
新一代
R940
则提高到了
62,500
(见下图)。

最后列出本文中引用Benchmark结果的白皮书出处,希望对大家有帮助。如果您觉得我的分析写的还凑合,也欢迎直接转发哦:)

参考资料
《
Performance and Energy Efficiency of DellPowerEdge servers with Skylake-SP
》
http://en.community.dell.com/techcenter/extras/m/white_papers/20444326
注
:本文只代表作者个人观点,与任何组织机构无关,如有错误和不足之处欢迎在留言中批评指正。
进一步交流
技术
,
可以
加我的
QQ/
微信:
490834312
。如果您想在这个公众号上分享自己的技术干货,也欢迎联系我:)
尊重知识,转载时请保留全文,并包括本行及如下二维码。感谢您的阅读和支持!《企业存储技术》微信公众号:
huangliang_storage

长按二维码可直接识别关注
历史文章汇总
(传送门):
http://chuansong.me/account/huangliang_storage





