成员介绍:
本项目为亓颢博老师开设的《深度学习》课程第七小组的期末项目,小组成员为统计学院20级本科生张钰佳,21级本科生罗张星汉,22级本科生林凡予,22级本科生陈欣雨,22级本科生曾婧如。
项目简介:
在校园环境中,学生、教职员工时常会遗失一些个人物品,如耳机、雨伞、手机、文具等。这些遗失物品不仅给失主带来不便,也增加了校园管理部门的工作量。在北师大,目前找回校内丢失物品的渠道主要依赖于小喇叭等平台,或是公众号“北师大失物招领”推送。这种方式效率较低,存在一定的信息不对称问题,容易错过招领信息。
基于校园失物招领的实际需求,本项目搭建了一个基于深度学习的失物招领系统,实现了一套高效便捷的校园失物信息匹配检索工具。系统包含三大关键模块:基于目标检测的图像分类、图像文字识别(OCR)、文本到图像检索。系统首先利用YOLOv8目标检测模型对失物招领志愿者上传的图片进行校园卡/其它物品的二分类,并框定校园卡位置。其次,对框定的校园卡区域进行OCR处理,提取学生学号,用于通过校园邮箱自动通知失主。最后,对于其它遗失物品图片,系统基于OpenAI提出的CLIP模型,将文本和图像嵌入到同一语义空间,实现文本到图像的跨模态检索功能。
实现原理:
遗失物品可以分为校园卡和其它物品两大类。对于校园卡,该系统能够通过自动识别遗失的校园卡,并通过OCR技术获取学号并自动发送邮件通知失主;对于其它物品,该系统对其他物品进行文本-图像检索,从而实现高效的失物招领流程,具体流程图如下:
 图 1 项目流程图
图 1 项目流程图
1. 基于目标检测的图像分类——YOLOv8
对于用户上传的任意失物图片,首先要对其进行校园卡/其它物品的二分类,再按照类别进行不同的处理。而用户上传的图片通常有以下问题,一是图片中除了校园卡还包含其它无用的文字信息,二是有一张图片里出现多张校园卡的情况,这两种情况都会影响OCR的结果。为实现该目标,我们先标注了2000张图片作为训练集微调YOLOV8模型,再将模型运用到剩余的图片上,一方面进行校园卡/其它物品的图像二分类,一方面进行在图片中框出校园卡位置的目标检测,从而防止OCR扫描到其他无关文字。
YOLOv8是目前YOLO系列算法中最新推出的检测算法,可以完成检测、分类、分割任务。YOLOv8提供了一个全新的SOTA模型,包括P5 640和P6 1280分辨率的目标检测网络和基于YOLACT的实例分割模型。基于缩放系数也提供了N/S/M/L/X尺度的不同大小模型,用于满足不同场景需求。
YOLOv8在前几代YOLO模型的基础上进行了改进,引入了更先进的架构设计和技术。在 Backbone(主干网络)方面,YOLOv8 采用了更先进的 CSPDarknet 作为主干网络,相比之前的 Darknet 架构,CSPDarknet 在特征提取能力和计算效率方面都有所提升;在Neck(特征融合层)方面,YOLOv8 使用了 Path Aggregation Network (PANet) 或 Feature Pyramid Network (FPN) 来进行多尺度特征融合,这种方法可以整合不同尺度的特征,增强检测效果,提高小目标检测的准确性。此外,YOLOv8 的Head(检测头)也进行了优化和改进,能够更精确地进行类别预测和边界框回归,进一步提高了整体的检测性能。具体的模型结构如下图所示:
 图 2 YOLOv8模型框架
图 2 YOLOv8模型框架
2. 图像文字识别(OCR)
对被分类为校园卡的图片,我们对其进行图像文字识别(OCR)。为了提高识别的准确率,在项目实际操作中我们调用了百度提供的API。由于校园卡上包含学生的姓名、学号、院系等信息与学生邮箱相匹配,因此我们可以基于OCR提取出来的这些信息向失主发送邮件以实现系统的自动通知功能。
光学字符识别(Optical Character Recognition,OCR)是一种将印刷或手写文本从图像、文档扫描件或照片中自动识别并转换为可编辑和搜索的文本数据的技术。OCR技术的广泛应用提升了文档处理的自动化和效率。OCR系统的工作流程如下:
(1)图像预处理:
-
-
二值化:将灰度图像转换为二值图像,以便于后续处理。
-
(2)文本检测:
-
-
版面分析:识别图像中的文本区域和非文本区域(如图片、表格)。
-
(3)文本识别:
使用深度学习模型将提取的特征与字符数据库进行匹配,从而识别出字符。
目前流行的基于深度学习的技术有CRNN和attention。本项目采用的百度智能云OCR技术主要基于CRNN,将CNN与RNN结合,最后经过一个转录层计算CTC损失,得到最终结果,其结构图如下:
 图 3 CRNN网络结构图
图 3 CRNN网络结构图
3. 文本到图像的检索——CLIP
对被分类为其它物品的图片,我们将图像和文本映射到同一个嵌入空间,进行相似度匹配,采用CLIP模型,最终实现了文字-图像检索功能。
CLIP (Contrastive Language–Image Pre-training) 是由OpenAI开源的基于对比学习的大规模图文预训练模型。对比学习着重于学习同类实例之间的共同特征,区分非同类实例之间的不同之处。CLIP的模型架构如下:
(1)对比式无监督预训练
 图 4 CLIP结构图(1)
图 4 CLIP结构图(1)
如图,假设我们有N个图像与它们各自的描述集合。对比式无监督预训练的目的是同时训练图像编码器和文本编码器,产生图像嵌入[I1, I2 ... IN]和文本嵌入[T1, T2 ... TN],其方式为:对正确的嵌入对,(其中i=j),最大化余弦相似度;对不相似的对,...(其中i≠j)最小化余弦相似度。
(2)Zero-Shot分类
 图 5 CLIP结构图(2)
图 5 CLIP结构图(2)
如图,首先,我们提供一组文本描述,这些文本描述被编码为文本嵌入。然后,图像被编码成图像嵌入。最后,CLIP计算图像嵌入和文本嵌入之间的成对余弦相似度。具有最高相似度的文本提示被选择为预测结果。
应用展示:
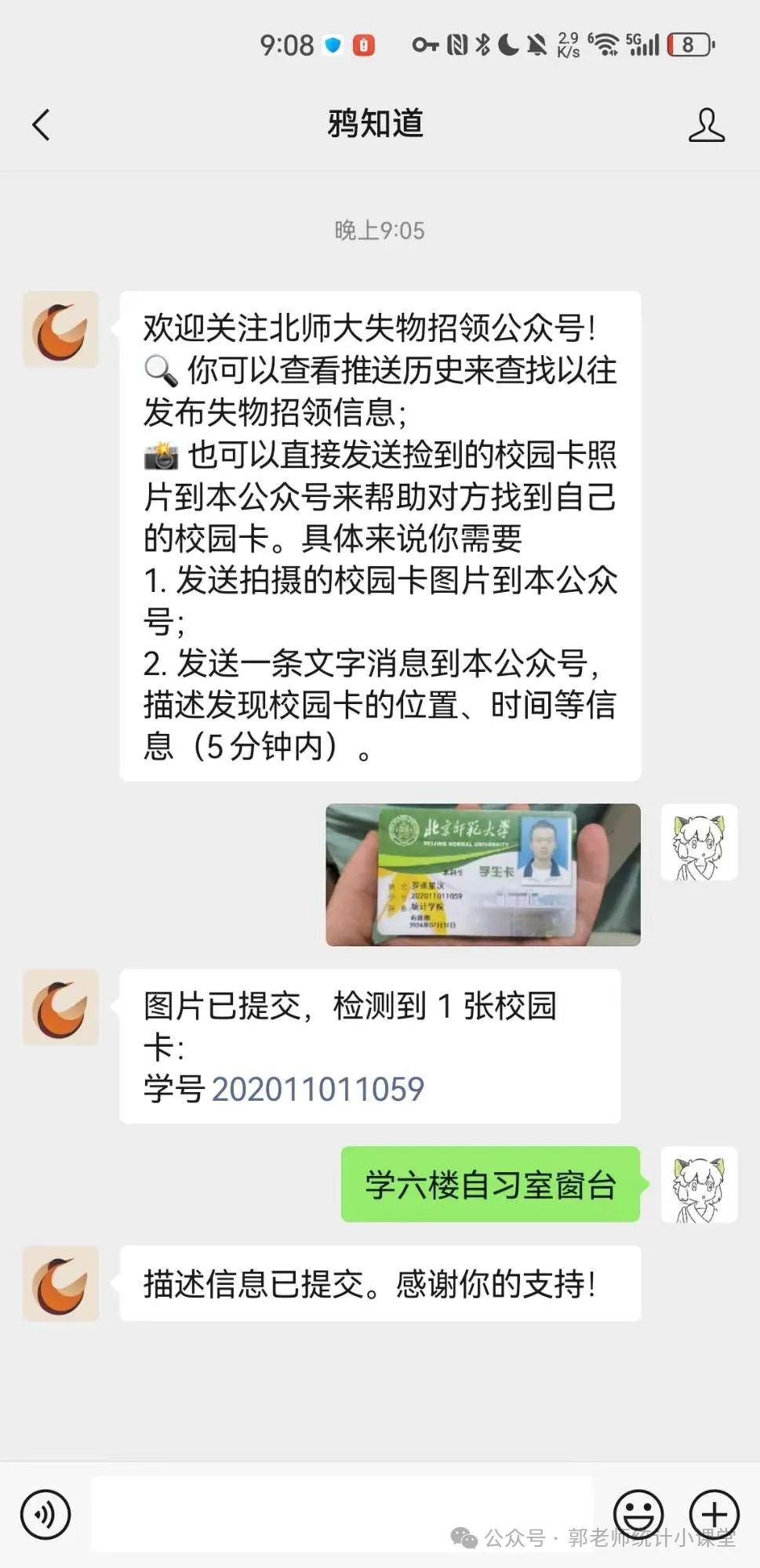
1. 校园卡主动召回:公众号提交校园卡照片
关注北师大失物招领公众号(此处使用个人公众号测试),并提交捡到的校园卡照片,附捡到地点位置描述信息。