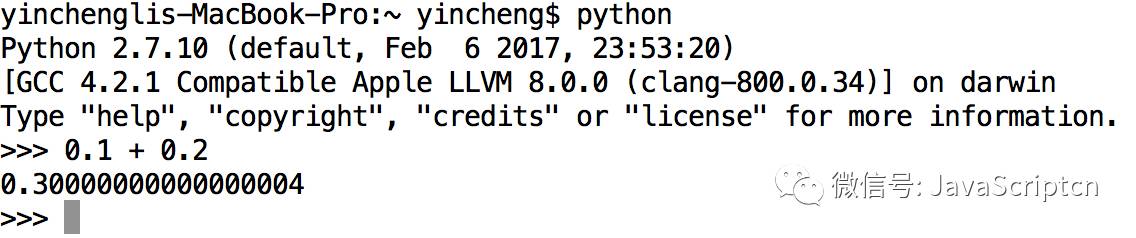
0.1 + 0.2不等于0.3这是一个普遍的问题,例如在JS控制台输入将得到0.30000000000000004

在python的控制台也是输出这个数:
在C里面运行以下代码,指定输出小数位为57位:
printf("%.57f", 0.1 + 0.2);
将得到:
0.300000000000000044408920985006261616945266723632812500000
那我们的问题来了,为什么计算机计算的0.1加0.2会不等于0.3?
首先我们来看一下JS能够表示最大数是多少,如下所示,打印Number.MAX_SAFE_INTEGER和Number.MAX_VALUE:

JS能表示的最大整数为9e16,能表示的最大正数为1.79e308,这两个数是怎么得来的呢?先来看一下整数在计算机的存储方式。
我们知道计算机是使用二进制存储数据的,整数也是同样的道理,整数可以分成短整型、基本型、长整型,占用的存储空间分别为16位、32位、64位,如果操作系统是32位的,那么使用长整型将会慢于短整型,因为一个数它需要分两次取,而在64位的操作系统,一次就可以取到8个字节或64位的数据,所以使用长整型不会有性能问题。另外,32位的操作系统内存只能识别到2 ^ 32 = 4G,而现在的电脑内存动不动就是8G、16G,所以现在的电脑基本都是64位的,不比前几年。
32位有符号整型的存储方式如下图所示:

第一位0表示正数,1表示负数,剩下的31位表示数值,所以32位有符号整数最大值为:
2 ^ 31 – 1 = 2147483647
即21亿多,如果要表示全球人口,那么32位整型是不够的。同理,64位有符号整型能表示的最大值为:
2 ^ 63 – 1 =
9223372036854775807
这是一个19位数,mysql数据库的id字段就经常用长整型表示,那为什么JS能表示的最大整数只有16位,而不是19位呢?这个要先说一下浮点型在计算机的存储方式。
现在浮点型的存储实现基本按IEEE754标准,符点数分为单精度和双精度,单精度为32位,双精度为64位。
在十进制里面,一个小数如0.75可以表示成7.5 * 10 ^ -1,同样地在二进制里面,0.75可以表示成:
0.75 = 1.1 * 2 ^ -1
即0.75 = (1 + 1 * 2 ^ -1) * 2 ^ -1,其中幂次方-1用阶码表示,而1.1由于二进制整数部分都是1,所以去掉1留下0.1作为尾数部分(因为都是1点多的形式,所以这个1就没必要存了)。因此0.75在单精度浮点数是这样表示的:
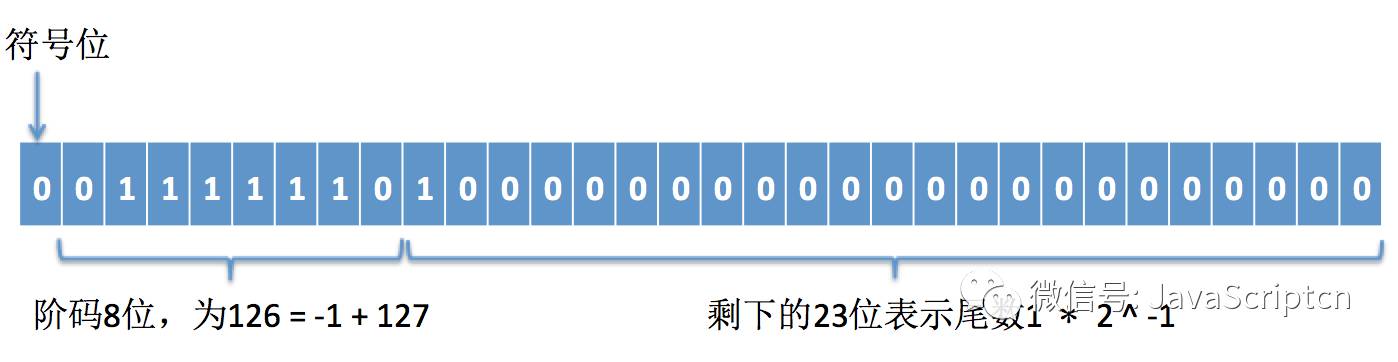
注意阶码要加上一个基数,这个基数为2 ^ (n – 1) – 1,n为阶码的位数,32位的阶码为8位,所以这个基数为127,8位阶码能表示的最小整数为0,最大整数为255,所以能表示的指数范围为:(0 – 127) ~ (255 – 127)即-127~128,上面要表示指数为-1,需要加上基数127,就变成126,如上图所示。
而尾数为0.1,所以尾数的最高位为1,后面的值填充0.
反过来,如果知道一个二进制的存储方式,同样地可以转换成10进制,如上图的计算结果应为:
(1 + 1 * 2 ^ – 1) * 2 ^ (126 – 127) = 1.5 * 2 ^ -1 = 0.75
那么0.1又该如何表示成一个二进制呢?
由于0.75 = 1 * 2 ^ -1 + 1 * 2 ^ -2,刚好可以被二进制精确表示,那0.1呢?没办法了,0.1无法被表示成这种形式,只能是用另外一个数尽可能地接近0.1(同理1/3无法在10进制精确表示,但是可以在3进制精确表示,只是我们习惯了10进制)。
我们可以用一小段
C代码
来研究一下0.1被存储成什么了,如下代码所示:
void printBits(size_t const size, void const * const ptr)
{
unsigned char *b = (unsigned char*) ptr;
unsigned char byte;
int i, j;
for (i=size-1;i>=0;i--)
{
for (j=7;j>=0;j--)
{
byte = (b[i] >> j) & 1;
printf("%u", byte);
}
}
puts("");
}
double a = 0.1;
double b = 0.1;
printBits(sizeof(a), &a





