没赶上6.8日《1小时机器学习入门》公开课或听过后还想再认真研读一遍的小伙伴们,StuQ为你们准备了本次公开课详翔实的文字稿。
本文为StuQ公开课《1小时机器学习入门》文字整理稿。
我们今天的主题叫做“一小时入门机器学习”,虽然标题听起来有点惊悚,有点像21天学习什么的,但是我跟今天的金老师主要是想跟大家聊一聊如何入门机器学习。本次课程是机器学习的一个前导课程,主要是帮助大家了解一下机器学习的概念和现状,同时让大家对本次课程的背景有一个了解。
在开始之前我先简单介绍一下我和今天给大家分享的金老师。我之前是在思科做云计算方面的工作,后来到Autodesk做平台架构这一层的研发工作。在这个过程中也接触了很多大数据的处理和这种数据的实时处理,以及相关的一些技术。其中也包括了Autodesk方面去从事了一些机器学习的工作。所以今天想跟大家聊一聊。
金老师,就比较厉害了。首先是PHD,现在在老人福祉科技实验室从事一些重要项目的负责工作,主要从事研发工作,对深度学习和图像识别领域甚至是我们现在的TensorFlow和Caffe这种深度学习的框架也非常熟悉,还有相关的开发和改造这方面的经验。看,也是现在大数据实时处理Hurricane分布式框架的主要贡献者之一。我马上也会聊一聊Hurricane分布式框架到底跟机器学习有什么关系。
今天我们主要会讨论三个主题,第一个主题是带大家进入机器学习的世界,我们一起来了解一下自己学习到底是什么,机器学习又如何影响我们的生活,最后来分清机器学习的相关概念,那就是大家了解的机器学习,深度神经网络,大数据,他们之间到底有什么样的关系。或者他们到底有什么区别,我们今天会弄个明白。

其实进入机器学习世界这个事儿挺废话的,大家有没有意识到,其实我们都早已经在一个机器学习包围的世界了,甚至都已经对很多事情熟视无睹。我们举一些例子,比如大家刚刚关注的阿尔法狗以3:0的结果完胜柯洁。至于某乎上关于阿尔法狗和柯洁的问题,更是一抓一大把。所以我们不在这里跟风去解读这个事情,我们来看另外一个事情。

另外一个比较熟悉的主题就是大家生活中会逐渐熟悉的例子,自动驾驶。谷歌的自动驾驶汽车,其实前两年都已经开了两百万英里了,强制报废距离了。对不信任自动驾驶的人来说,这种距离根本没有什么用。但这还是能从一定程度上证明自动驾驶技术已经逐渐成熟。至于Uber和Tesla,则更是在许多汽车上安装了这种数据收集系统,收集更多的数据,其数据量据说远超谷歌。美国还制定了一些自动驾驶相关的法律,为自动驾驶技术打开方便之门。

我们可以看到机器学习和大数据相关的技术已经深入很多领域,现在最热门而成熟的技术估计就是各类生物特征识别,比如人脸识别技术。最近大家应该常常在新闻里面看到,某个站安装了人脸识别设备,识别某个人的脸和身份证,某派出所根据人脸设备抓取识别犯罪嫌疑人,某银行根据人脸识别完成自动开户的工作。
最近最火的应该就是自动驾驶技术,无论是谷歌还是苹果。Google在研究自动驾驶技术,刚开始根本没有人理他,觉得做这件事没有意义,觉得也不太可能。结果这两年各种汽车榜上都开始研究自动驾驶,包括奔驰宝马。然后和汽车相关的企业,比如Uber和Tesla,也开始着手数据研究自动驾驶。国内拿智能汽车来投资的公司更加是多如牛毛。
各种互联网公司都跟风而上。大家最近可能会看到乐视的新闻,太多的我们也就不在这里讨论了。然后是国内比较著名的这种人工智能公司,百度也做了自动驾驶技术,并把相关的这种数据开源了。数据其实是海量数据,我们会讲到这种海量数据怎么跟机器学习做一个结合。了解了这些东西,大家就知道各个公司无论是大还是小,无论是国内还是国外,都开始关注自动驾驶或者说是机器学习和人工智能领域。
另外一个比较热闹的圈子就是智能医疗。在智能医疗领域,我们也希望能把更多的领域给大家分享一下。其实大家都知道,现在人都非常喜欢养生,所以从智能手环开始,穿戴设备层出不穷。大家要知道在传统情况下,要做一个医疗器械,其实有很高的门槛。现在这些设备一不抽血二不化验,只要根据外部的各种数据去拟合大家的健康状态,完全没有审核门槛,想做就做。当然还有很多真的去做医疗健康数据的公司,根据各种评估数据和体验数据来做健康管理的工作。
总结一下,机器学习已经不是一个陌生的东西了,无论这东西能不能用,是炒个噱头还是脚踏实地的做技术,我们都已经离不开大数据和机器学习了。
到底什么是机器学习呢,我们现在来进入主题。这里用一张图来概括一下机器学习的过程。
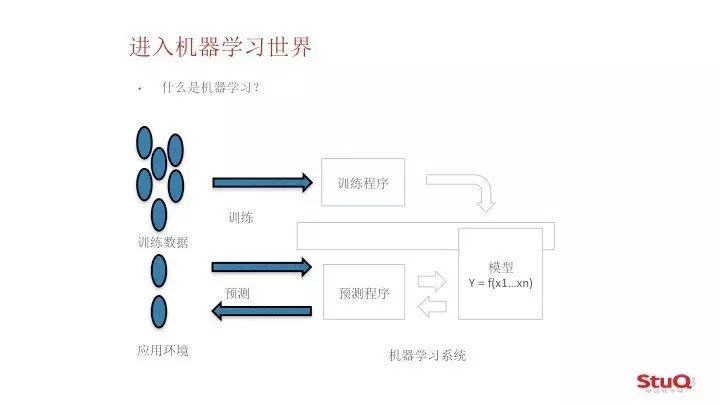
我们这里做一个简单的例子,我们小时候去学校上数学课,老师给大家发课本,课本里的内容会帮大家梳理,梳理完课本的知识点之后会给大家布置作业,在大家做完布置的作业之后,老师还会给你批改作业。经过小学一二年级的艰苦奋斗,终于学会了加减乘除。
对于机器学习本身来说,跟我刚才举的这个例子非常类似。我们可以将机器看做一个人,然后要给他准备一系列的数据,这些数据就是课本的知识来源。当然一堆乱七八糟的废数据肯定是没有用的,所以我们要帮机器整理好数据。整理后的数据其实就形成了我们所谓的课本,然后我们要给自己安排一个老师,告诉机器如何使用这些数据,梳理这些知识点之间的关系。这就是我们的训练程序和模型。现在有了课本,有老师,机器就可以开始学习了。
我们把这里的学习过程叫做训练,这里训练是一个专业术语。在训练完之后,我们会生成一个含有具体参数的模型,这个模型就是机器学习的结果,也就是那些存储在我们脑子里的知识。以后当有人去问机器这个问题的时候,机器就会使用这个模型,来处理问题的输入,这里的模型也是一个专业术语。生成一个输出来回答用户输入的问题,这个过程叫做预测,预测也是术语。
就像在学校里面,要怎么样检测学生的学习成果呢?所以我们就会输入一堆的测试数据,给我们的机器学习系统,机器学习系统,根据这个模型给我们相应的答案,我们比较一下测试数据的正确答案和机器给出的答案,就可以给机器学习打一个分数,这个分数就是测试的准确率。当然我们大家经常会说学习好累呀,相比之下,机器可能比我们还要苦,学习完一个知识之后可能要一下子做几万道题。
我们在这里梳理一下整个机器学习的大致流程,
首先我们会整理一系列的数据给训练程序,这些数据就叫做训练数据,我们再给训练程序指定一个现成的模型学习方法,训练程序就会乖乖根据我们的训练方法读入数据,并得到学习后的模型,这个模型可以抽象成一个泛化的函数,作用就是输入一堆的自变量,这些自变量指的就是训练数据当中的一些特征,这里的特征也是一个术语,然后得到最后的因变量也就是问题的答案。
机器学习里面的模型包含算法,但并不是传统意义上的算法。训练程序得到的最终的模型,是一种根据数据判断的一个感觉,不是一个特定的数学模型。这样的模型很难被人类直接去阅读和理解,这也是机器学习当中一个精妙和美的存在。
理论上讲,我们在这个情况下,就可以拿这个模型到实际的生产环境中去应用了,不过在这之前呢,还有两步我们需要去做:
-
第一步输入训练数据
,看看得到的模型能否正确处理训练数据。只有准确率达到一定的水平,我们才能进入下一步,也就是说机器学习的这个模型能不能满足我们的要求。
-
第二步输入一堆测试数据
,然后让模型给出结果,然后我们再来看看得到的准确率到底如何。如果两步当中有一步不满足,我们只能修改训练数据。那么回到我们最早的例子,也就是换课本,因为课本不行,所以学生要重新学习,或者换老师,换老师就是换训练方法和模型。直到两个准确率都足够,我们才能真正的把这个模型应用到实际的生产环境中去。
但是这里就存在两个问题,一个在训练数据上表现很好的模型到底效果好不好呢?其实不一定,就像在现实生活当中,课本会告诉我们1+1等于2,但是他不会告诉我们9999+1等于1万。课本上的内容总是有限的,我们要学会方法的本质,然后举一反三。
举一反三,才是真正厉害和关键的地方,对于机器来说也是如此
。机器要从训练数据当中找出其规律所在,才能去应付现实世界当中的实际问题,不然就成了一个只会做试卷题目的傻学生。刚才我看到有人说做高考题目也能做到很高的分数,对不对,这里我想大家也应该有所感悟。
但是现实当中确实有很多在训练和测试上表现非常好,但是在现实中却不怎么样的模型。我们将这种现象叫做
过拟合
,大家注意这里的过拟合也是一个术语。对于很多模型来说,如果数据量过小,就很容易出现这种过拟合的问题。就像孔子所说,“举一隅不以三隅反,则不复也。”
模型设计不当的话,给再多数据其实也没有用
。如果训练出来一个模型是过拟合的,其实并没有什么用,没有什么价值。在这里呢,
我们把模型的需求称之为模型的泛化能力
。这个泛化能力大家可以注意一下,也是一个术语。
所以所有的客户在使用机器学习产品的时候,都需要使用自己的数据去验证模型的使用价值,对于我的实际需求来说,到底管不管用。当然了,如果某一个人是个数学天才,他可以想到如果有学生作弊,把自己学过的题目告诉老师,让老师试卷上都是这些题目,那这个学生很高几率得一百分对不对?那更不用说机器了。如果他遇到的数据都是训练数据,那这个准确率就“呵呵呵”了。我们把这种情况称之为
机器的作弊
。
接下来我们来看看和机器学习相关的几个名词,什么是大数据,什么是机器学习,什么是深度神经网络,我们今天就来把这三个说清楚。
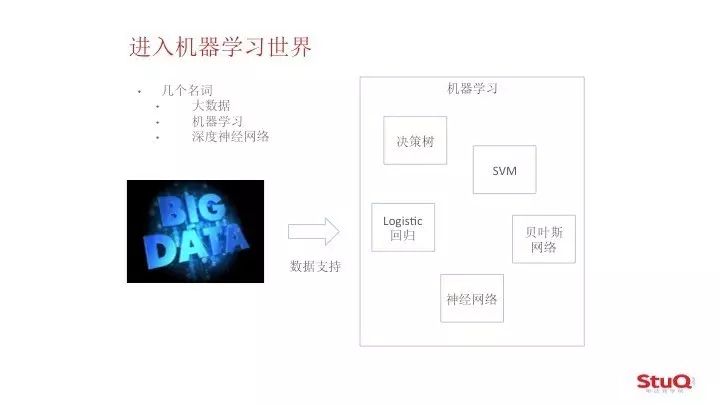
首先来说什么是
大数据
,其实大数据是最先火起来的词语,现在搞IT的,拿几万份样本做个模型,就说自己是搞大数据的了。现在大数据和云平台很多时候一样都成为了一个噱头,但是当你真正遇到各种大数据的时候,问题并没有想的那么简单。其实我一直觉得国内能做大数据的非BAT莫属,所以涌现了很多批这种处理大数据的专用公司,后面我们会介绍一下。
第二就是
机器学习
,我们刚刚详细讲了机器学习大概是怎么回事儿。
然后这里最热的就是深度学习了,所谓
深度学习
呢,其实就是深度神经网络,就是层数非常深的神经网络。神经网络就是人工神经网络,30年前就有这个东西了,并不是什么特别新的概念,但为什么现在这么火呢?其实是这个东西遇上了一个非常好的时代,所以就发扬光大了。神经网络其实就是机器学习中的一种,其他的什么决策树呀,SVM呀,贝叶斯网络呀,各种各样的数学模型完全数不过来。那么深度神经网络又是怎么回事呢?其实深度神经网络只是人工神经网络的一个小分类,其实并没有什么高大上的东西,听起来非常玄乎。但是它的效果好,现在各个公司都跟风去用这个深度神经网络。为什么这十几年来深度学习热起来了?其实最主要的原因,我觉得还是遇上了一个好的时代,具体是为什么呢,我们后面也会详细去讲。
干货太多,我们分两次看,好消化~
《1小时机器学习入门》(下) 我们稍后更新......
想更深入了解深度学习?
这里有一套为想求职/转行/加薪人工智能领域的同学量身定制的大课《3个月成为AI实战工程师——深度神经网络实战》,
现在报名,还有早鸟票哦~

还有 3 个
200元
本课程优惠码【
STUQ628
】,先抢先得!点
「 阅读原文 」
立即使用。





