
PaddlePaddle 入门和实战

距2017
年
12
月
7
日
由百度公司举办的
“
百度
AI
加速器第一期开营仪式
”成功举办并推出“
燎原计划
”已有一周多时间,根据学员学习的积极程度和产出来看,星星之火已开始升温,这篇文章就是我们优秀学员对于学习的深度体会,作者是百度 AI 技术的忠实学员和践行者,笔记内容和图片等已经作者同意,于我们平台进行发布。
提前声明:本文标题为“
不懂高数
”,并非“
不懂数学
”。如有异议,抗议无效😳
提前透露:后续还会有更加基础入门资料发放。
作者的原始目标
读者
是从事 IT 工作,想学习 AI 技术的专业人员。(敲黑板+严肃脸:咱的读者都是专业的)。当然如果自己看不懂,不如转给朋友同学,让朋友一起懵逼~
PS:(分割线后正文)如果不知道 PaddlePaddle 的深度学习去哪儿入手,可以去极客学院的官网企业入口,点击进入
百度 AI 图像技术课程
。
正文开始:
首先是我们本节课程地址:http://www.jikexueyuan.com/course/4031.html

1. 学前准备
本视频讲的就是AI基础知识,让新用户打好理论基础,并且希望通过本次视频和学习笔记,逐步将AI爱好者引导至百度PaddlePaddle开源框架。如果是非IT人员仅仅想了解行业,还是建议看《猿人的第一次直立行走》这篇文章。
本视频讲了主要这些内容:
-
什么是机器学习
/
深度学习,以及简单分类。
-
什么是模型。
-
什么是假设函数。
-
什么是损失函数。
-
(重点)梯度下降训练模型。
-
一个典型案例的说明和准备
-
(重点)数据预处理
-
设计假设函数和损失函数
-
训练和观测结果
水
多数人对AI学习的概念很模糊,以为这是个半年时间就能学有所成的技术,但是“做AI”和“用AI”的区别很大。“做AI”的要求很高,我从各个渠道获取的信息,不是藤校硕博就别梦想自研算法了;但“用AI”的要求并不高。
以这一节入门培训视频为例,有数学基础更好,没有高数基础听起来会很吃力,但多听几次查查百科也能听懂;实验实操部分使用的Docker部署环境和Jupyter电子书操作,对计算机水平要求也不高,能安装运行起Docker,能读懂Python常规语法即可。
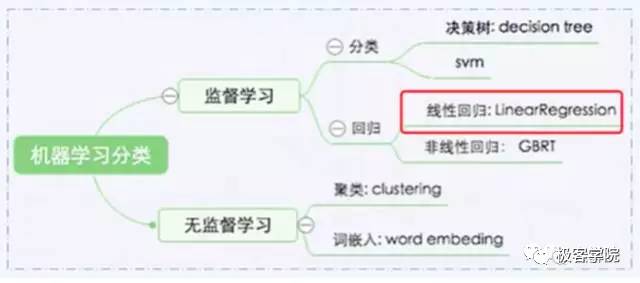
2. 深度学习和机器学习的关系
深度学习是机器学习的最热门分支,这句话足以解释深度学习和机器学习的关系。机器学习可以分为有监督学习和无监督学习,监督学习主要解决分类和回归问题,无监督学习最主流的算法是聚类和词嵌入。
今天的课程只讲解监督学习的线性回归问题,这个经典的模型足以解释在深度学习中遇到的大部分基础问题。
3. 模型是什么
在监督学习过程中,一个Feature(特征)和对应的Label(标签)被称为一个样本(example),所有样本的集合被称为数据集(dataset)。图片识别过程中,原始图片是特征,图片的实际内容是标签;语音翻译过程中,原始语音是特征,输出的文字是标签;本节课的房价预测实验中,房价有关的13类信息是特征,预估出的房价是标签。





