问题导读
1.flume的配置你是如何理解的?
2.flume与kafka整合,kafka可以做哪些组件?
3.flume与kafka的区别是什么?
flume是比较常用的大数据技术,那么学习flume,我们还需要思考flume,这样理解才能在遇到问题的时候,更容易解决,使用起来更加的得心应手。下面介绍了flume的相关内容及个人的理解。
flume应用
一般来讲,我们接触flume可能更早一些。flume如何安装可参考
让你快速认识flume及安装和使用flume1.5传输数据(日志)到hadoop2.2
http://www.aboutyun.com/forum.php?mod=viewthread&tid=7949
如果你安装测试过flume,可以知道flume可以传递数据到另外的地方。比如我们可以传递本地文件到hadoop文件,比如搜集日志到hadoop,然后通过mapreduce或则spark处理。这也是比较常见的。
flume解析
flume有哪些内容,我们刚开始学习的时候,几乎都是复制黏贴的方式。对于它们几乎不怎么理解,或则只是停留在表面的理解。所以导致我们产生异常或则错误的时候,就不知道怎么解决了。
这里解析下flume,可以知道我们在干什么,我们遇到错误的时候,能够知道哪里出现了问题。
channel的作用
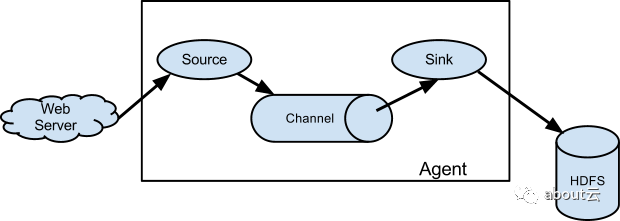
flume传递数据,包含三个组件:source,channel,sink.
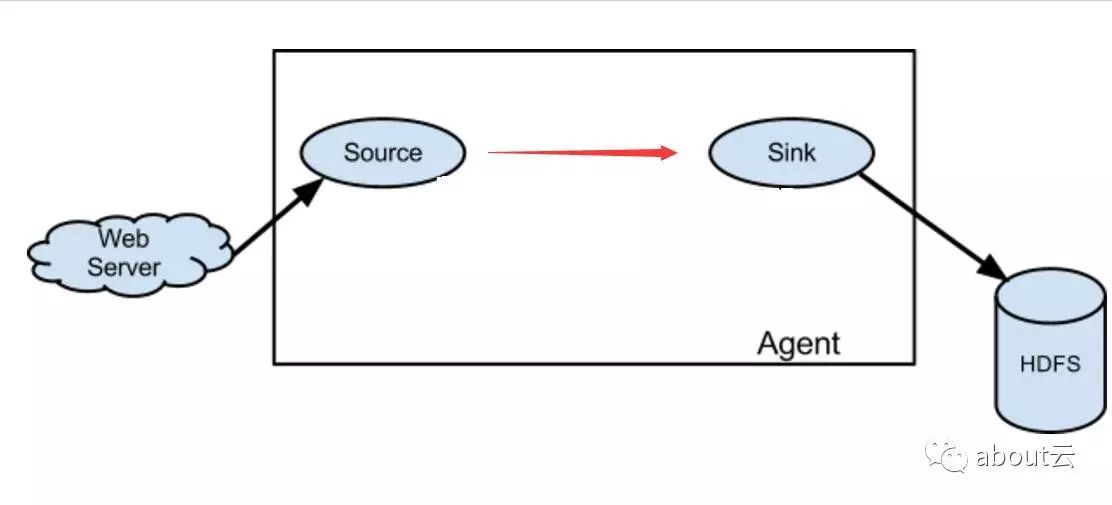
那么如果我们来开发flume,我们会如何开发。好像channel这个不是必须的。因为有了数据源source和数据传递目标sink,应该就可以了。为何还需要channel。感觉channel是多此一举。
从正常的角度来说channel确实是不需要的。但是有一个前提,source和sink要保持同步。也就说,source发送一条数据,sink需要立即消费和保存一条数据。
下图是正常flume
下图是去掉channel的flume。如果一旦数据源频率过快,sink来不及消费保存数据,那么就会造成丢失数据。
如何定制flume
一个灵活的程序,都是可以配置的,最常见的是xml格式文件,当然也可以是其它格式,普通txt也是可以的。所以我们看到无论是那种开源技术,都是可以配置的。甚至对于刚入门的初学者来说,就认为配置文件是必须的。
所以我们这里所说的定制,是对flume的的定义。那么flume该如何定制。
那就是通过对应source、channel、sink的定义。
这里我们只接贴出配置文件
[XML]
纯文本查看
复制代码
?
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
agent1表示代理名称
agent1.sources=source1
agent1.sinks=sink1
agent1.channels=channel1
#配置source1
agent1.sources.source1.type=spooldir
agent1.sources.source1.spoolDir=/usr/aboutyunlog
agent1.sources.source1.channels=channel1
agent1.sources.source1.fileHeader = false
#配置sink1
agent1.sinks.sink1.type=hdfs
agent1.sinks.sink1.hdfs.path=hdfs://master:8020/aboutyunlog
agent1.sinks.sink1.hdfs.fileType=DataStream
agent1.sinks.sink1.hdfs.writeFormat=TEXT
agent1.sinks.sink1.hdfs.rollInterval=4
agent1.sinks.sink1.channel=channel1
#配置channel1
agent1.channels.channel1.type=file
agent1.channels.channel1.checkpointDir=/usr/aboutyun_tmp123
agent1.channels.channel1.dataDirs=/usr/aboutyun_tmp
|
这里解析下上面的配置:首先是对flume的agent的配置。对于代理取了一个名字agent1。
agent1里面包含三个组件,这三个组件也分别取一个名字:source1,sink1,channel1
agent1表示代理名称
agent1.sources=source1
agent1.sinks=sink1
agent1.channels=channel1
我们为什么给他们取名字,是为了方便下面我们给他们定义。不取名字会带来什么后果。如下图,如果多个channel或则sink,我们就无法区分和定义了。
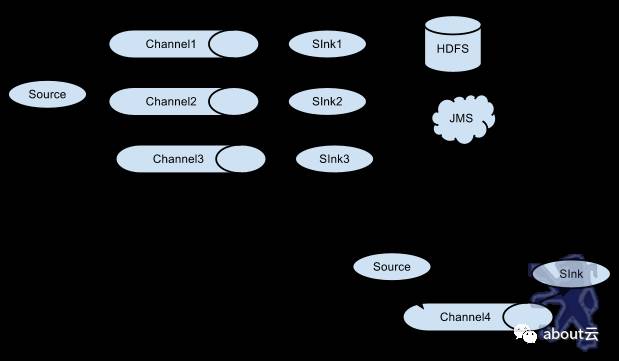
取名之后,我们分别对他们定义。
[XML]
纯文本查看
复制代码
?
|
1
2
3
4
5
|
#配置source1
agent1.sources.source1.type=spooldir
agent1.sources.source1.spoolDir=/usr/aboutyunlog
agent1.sources.source1.channels=channel1
agent1.sources.source1.fileHeader = false
|
先来解析一条
agent1.sources.source1.type=spooldir
上面是说agent1的数据源,source1的类型是spooldir。上面看上去很复杂,但是其实就定义了那么几项:
spoolDir,channels,fileHeader 分别是目录,使用哪个channel,及是否添加Header等信息。
sink同样的道理
[XML]
纯文本查看
复制代码
?
|
1
2
3
4
5
6
7
|
#配置sink1
agent1.sinks.sink1.type=hdfs
agent1.sinks.sink1.hdfs.path=hdfs://master:8020/aboutyunlog
agent1.sinks.sink1.hdfs.fileType=DataStream
agent1.sinks.sink1.hdfs.writeFormat=TEXT
agent1.sinks.sink1.hdfs.rollInterval=4
agent1.sinks.sink1.channel=channel1
|
配置了sink1的类型,hdfs路径,file类型,格式,滚动时间,使用channel等。
通过上面,我们或许就明白了,flume的各种配置。也能轻易读懂别人是如何配置的。
flume与kafka整合
flume与kafka整合应该是用的比较多的,而且这也是一个难点。这里只是简单说下。
1.kafka作为数据源
kafka作为数据源其实kafka消费者,从kafka topic读取消息。如果你有多个kafka数据源运行,你可以配置他们为同一个Consumer Group。它们只能读取topics的一个分区.
这里只介绍下一些必须的属性,更多可参考官网
属性名称:
type值为
org.apache.flume.source.kafka.KafkaSource
kafka.bootstrap.servers值为kafka作为数据源的broker的列表。格式为host:端口例如localhost:9092
kafka.consumer.group.id:这个不是必须的。默认为flume。
kafka.topics:kafka消费者从topics 列表读取消息
kafka.topics.regex:定义了一组topic.比 kafka.topics有更高的优先级.是对kafka.topics的重写。
过时的属性
topic,groupId,zookeeperConnect分别替换为
kafka.topics,kafka.consumer.group.id,kafka.bootstrap.servers 链接 kafka cluster
下面举两个例子
多个topic的配置
[Bash shell]
纯文本查看
复制代码
?
|
1
2
3
4
5
6
7
|
tier1.sources.source1.
type
= org.apache.flume.
source
.kafka.KafkaSource
tier1.sources.source1.channels = channel1
tier1.sources.source1.batchSize = 5000
tier1.sources.source1.batchDurationMillis = 2000
tier1.sources.source1.kafka.bootstrap.servers = localhost:9092
tier1.sources.source1.kafka.topics = test1, test2
tier1.sources.source1.kafka.consumer.group.
id
= custom.g.
id
|
使用正则订阅topic
[Bash shell]
纯文本查看
复制代码
?
|
1
2
3
4
5
|
tier1.sources.source1.
type
= org.apache.flume.
source
.kafka.KafkaSource
tier1.sources.source1.channels = channel1
tier1.sources.source1.kafka.bootstrap.servers = localhost:9092
tier1.sources.source1.kafka.topics.regex = ^topic[0-9]$
|










