编者按:腾讯暨 KDD China 大数据峰会在深圳举行,其中香港科技大学教授、第四范式首席科学家杨强做了一期以《从深度学习到迁移学习》为主题的演讲,本文主要阐述了杨强教授在会中讲解迁移学习本质以及其在产业界的实际应用,由亚峰、亚萌、宗仁联合编辑。
迁移学习是什么?
简单讲,就是能让现有的模型算法稍加调整即可应用于一个新的领域和功能的一项技术。迁移学习能够将适用于大数据的模型迁移到小数据上,实现个性化迁移。
人类很自然就具备举一反三的迁移能力,如我们学会骑自行车后,学骑摩托车就很简单了;会打羽毛球,再学打网球也就没那么难了。
迁移学习在产业界的实际应用
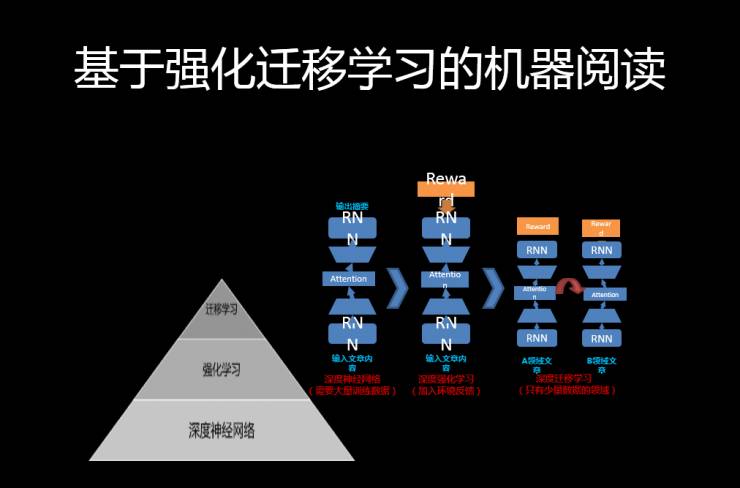
1.迁移学习在机器阅读中的应用
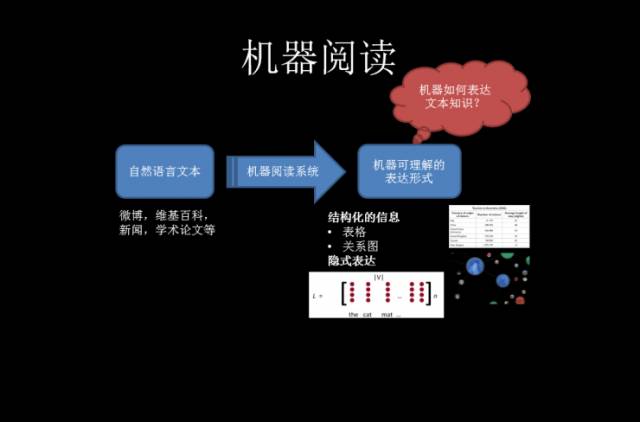
所谓“机器阅读”,就是把自然语言文本转化为机器可以理解的模式,然后机器根据这个模式对个人进行服务。
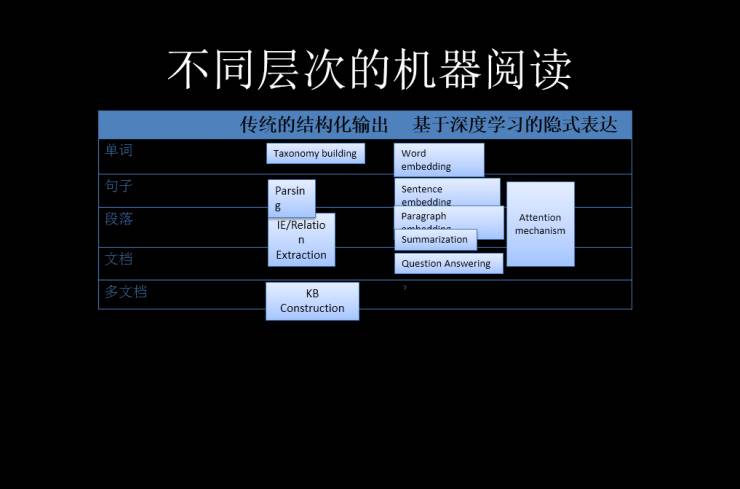
这个模式可以从不同的层次进行“理解”,比如可以在字、句子、段落、文档和多文档当中产生各种隐式表达,而这些表达可以用空间的相似度来代替,这样加一个词,可以映射到高维空间。
有了这种表达之后,可以拿一句话到比如说 LSTM 里 ,对应的就是输出,这个输出就会给我们对话一个现象。
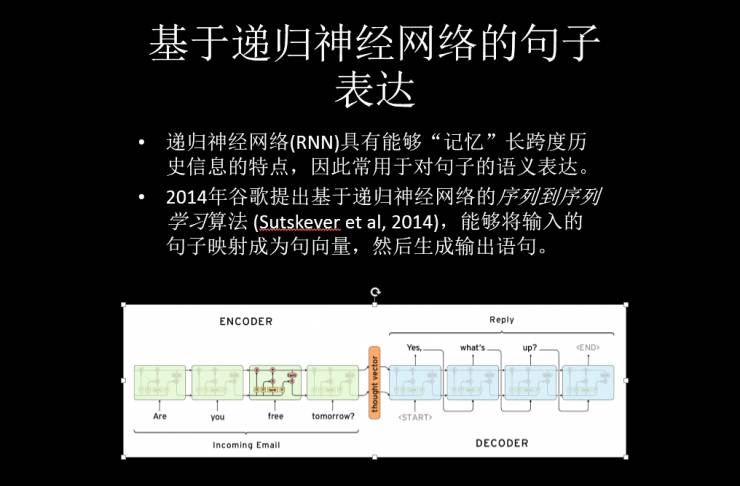
同时,我们还可以拿 Attention 模型去标明一些问句里面的概念,它可以利用同一个对比相似性找到这个概念。因为其内部隐含的表达是一个 text,把周边字的名称给理解了,它的应用就是可以自动产生文本摘要(Automatic Summarization)。

这个在 Information Retrieval里面叫做 Summarization,过去的 Summarization 做法是“提取式” (Extractive)的。

但是今天 Summarization 可以做到“理解”,并用自己的语言或用户喜欢的语言表达出来。所以这里就要提出一个新的方式,就是既可以结合传统 Summarization,并加入用户反馈(比如用户看了某篇文章、所看时长或点赞行为)。
所以,接下来就可以把模型个性化,给张三看的 Summarization和李四看的 Summarization不一样,就像一篇文章我们需要产生一个吸引眼球的标题,但你给张三和李四看的标题都是不一样的。
2.迁移学习在对话系统中的应用

训练一个通用型的对话系统,该系统可能是闲聊型,也可能是一个任务型的。但是,我们可以根据在特定领域的小数据修正它,使得这个对话系统适应不同任务。比如,一个用户想买咖啡,他并不想回答所有繁琐的问题,例如是要大杯小杯,热的冷的?
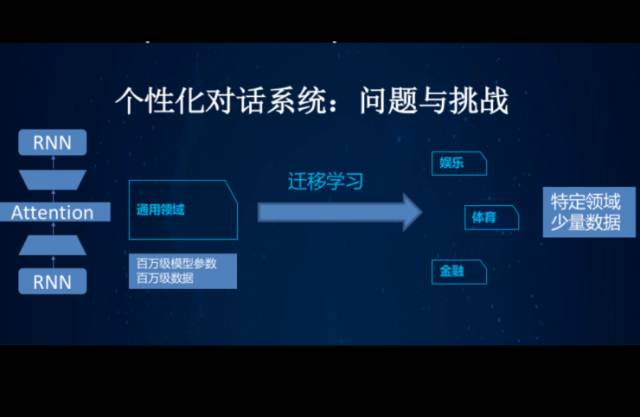
所以我们希望这个系统了解用户的喜好,根据过去的数据分析,一步到位提供一杯符合用户需求的咖啡。
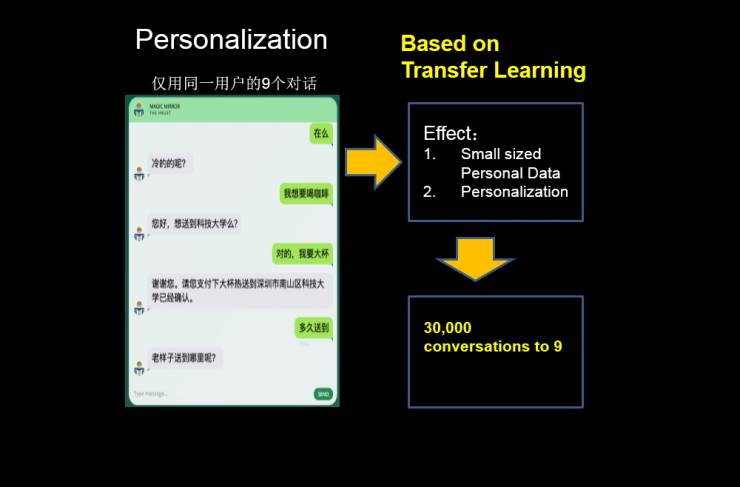
这里举个例子,买咖啡的时候,可能你不喜欢每次都回答所有问题,比如你要大杯小杯啊?热的冷的啊?而是想这个助手了解我,可以根据我们过去的小数据来一步到位。
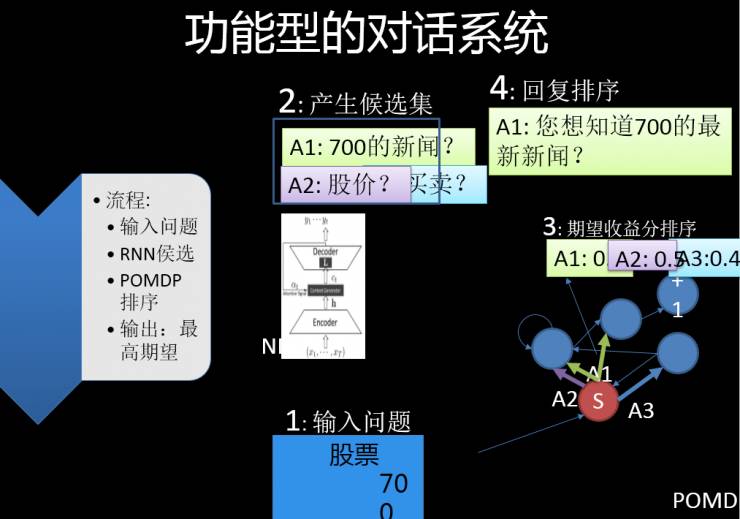
据此,我做了一个推荐系统,把一个在三万个对话基础上做了一个通用型的对话系统,或者说任务型的对话系统,迁移到一个个性化的统计上,变成只有 9 个对话的(小数据)上,就像一个懂你的小秘书。同理,这个也可在金融系统,问一些金融和股票的问题,然后它通过强化学习,给你建议一些 Candidate。并且对收益和用户的需求做排序。

在这个过程中,我们看到:
第一部分是深度学习效果。
第二部分是强化学习效果。
第三部分是迁移学习效果。
最后我要讲最近一些做的迁移学习的工作。如果两个领域,直接迁移是不行的,我们可以找到一些中间的领域。这个我们可以用深度学习的方法,假设我们用一个大数据,已经训练好的一个系统,然后我们现在的目标是到达一个目标领域,若我们不能一步到位的话,会发现一旦我们用的小数据,各种数据的属性相差很多,怎么办呢?我们去找一些中间的领域,中间的领域可以适度的的改变, 并且一些不应该改变的部分不会改变。这样经过合理改变之后,部分数据加以梳理,最后就得到我们要的被迁移数据。
3.迁移学习在舆情分析中的应用
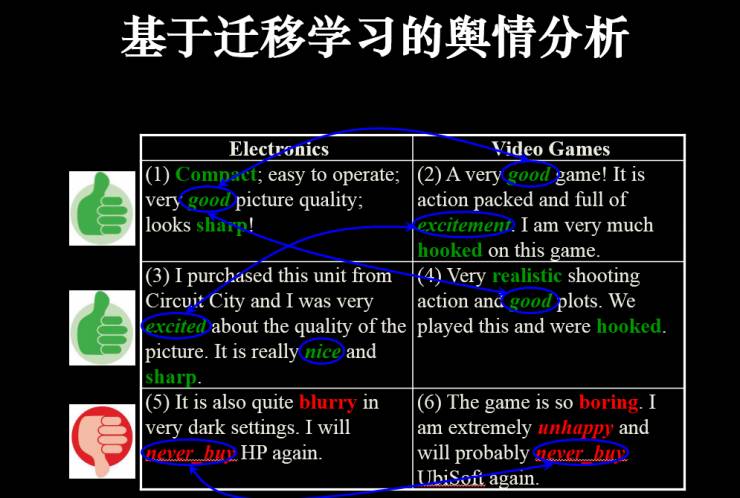
迁移学习也可应用在舆情分析中,如用户评价方面。以电子产品和视频游戏留言为例,上图中绿色为好评标签,而红色为差评标签。我们可以从上图左侧的电子产品评价中找到特征,促使它在这个领域(电子产品评价)建立模型,然后利用模型把其迁移到视频游戏中。这里可以看到,舆情也可以进行大规模的迁移,而且在新的领域不需要标签。
4.迁移学习在推荐系统中的应用
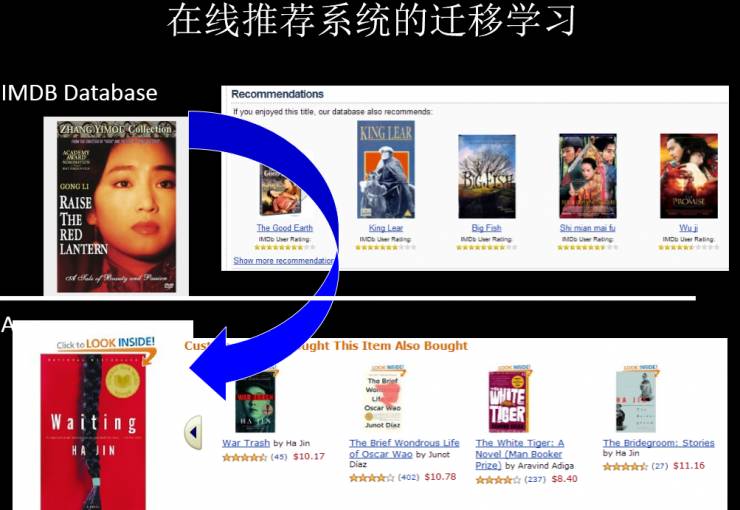
我们之前也与 IMBD 做过在线推荐系统,在某个领域做好一个推荐系统,然后应用在稀疏的、新的垂直领域。
风头正劲的迁移学习

当今全世界都在推动迁移学习,当今 AAAI 中大概有 20 多篇迁移学习相关文章,而往年只有五六篇。与此同时,如吴恩达等深度学习代表人物也开始做迁移学习。
为什么呢?因为要在一个领域找到高质量的数据非常难,而把现成的模型用在高质量数据量少的领域则是非常好的解决方案。
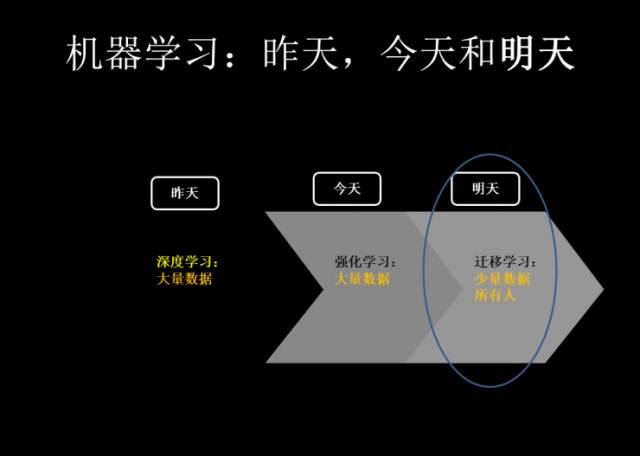
昨天我们在深度学习上有着很高成就,但我们发现深度学习在有即时反馈的领域和应用方向有着一定的优势,但在其他领域则不行。打个比方:就像我在今天讲个笑话,你第二天才能笑得出来,在今天要解决这种反馈的时延问题需要强化学习来做。而在明天,则有更多的地方需要迁移学习:它会让
机器学习在这些非常珍贵的大数据和小数据上的能力全部释放出来。做到举一反三,融会贯通。
附:腾讯暨 KDD China 大数据峰会之前,杨强教授就曾在 2016 年雷锋网承办的 CCF- GAIR 全球人工智能与机器人峰会大会上,深入浅出地为大家讲述了人工智能要取得成功应当具备的五个必要条件和迁移学习的本质。

AI 成功的 5 大必要条件 & 揭开迁移学习的本质

当下人工智能在图像识别、语音识别和大规模的产品推荐方面取得了巨大的成功,那么人工智能的成功应用究竟取决于哪些条件?
为什么只在我们这个时代迎来了人工智能发展的高峰期?
对于这两个备受关注的问题,杨教授从人工智能的科学与应用两个方面着手,娓娓道来。
人工智能的科学与应用——相辅相成

人工智能技术的发展大体可以分为两个方面:人工智能的科学与人工智能的应用。
从科学层面谈及人工智能要回归到该研究领域最根本的问题:机器能够思维吗?这个问题最早起源于人工智能之父图灵,之后经过60多年的努力,计算机科学家及各行各业对人工智能感兴趣的人士都竞相研发计算能力更强的计算机,汇聚更多的数据,提出更高级的算法,致力于回答这个最基本、也是最重要的问题。
谈到应用层面,除去人工智能已经为我们的生活带来的便利,我们更关心它对人类未来生活将产生什么样的影响。要将人工智能技术成功地应用于商业领域,既要站在科学前沿,也要具备一定的商业头脑,两者兼备才能在商业浪潮中立于不败之地。
人工智能取得成功的五个必要条件

会上,杨教授言简意赅为我们分享了决定人工智能成功的五个必要条件:
清晰的目标(商业模式)
高质量的大数据 (持续反馈)
清晰的问题定义和领域边界
懂人工智能的跨界人才(擅长应用和算法)
计算能力
首先,要有 “清晰的目标”,即清晰的商业模式,这就好比游戏中明确规定何为赢,何为输,延伸到人工智能在商业领域的应用,即要确定明确的运行模式和运行目的。
其次,高质量的大数据资源是人工智能成功的核心条件。杨教授特别强调,高质量的数据要求收集到的数据能够具备持续性、反馈性,且反馈的方式与内容要与具体的算法相匹配。有人会觉得,在某个领域拥有了几千万个数据样本便具备从事人工智能的条件了,杨教授认为,这种观点是站不住脚的,原因如下:首先,已收集的数据样本可能无法与某个特定的算法相匹配;其次,所用到的算法可能不具备可持续性;最后,得到的反馈方式与内容不一定与期望相符。
第三,清晰的问题定义和领域边界。要求在应用人工智能技术时要对所遇到的问题有清晰的理解与定义,就像下棋一样,在有限定的领域里完成特定的行为操作。
第四,人工智能成功的核心竞争力在于懂人工智能的跨界人才(擅长应用和算法),即我们需要一个既精通人工智能,又在商界游刃有余的人才。当然,很多人会质疑:我们到哪里去找这样的人才?杨教授号召我们做生活中的有心人,善于关注身边会学习的人,着重培养其跨领域才能,这样的人才将具备把两个看似不同的垂直领域联系在一起的能力,在未来能够做出突出的成就。
最后,杨教授提出,强大的计算能力是人工智能技术在各领域成功应用的硬实力。在计算能力方面,我们有云计算、并行计算、GPU,这都为人工智能的发展奠定了坚实的基础。
人工智能已经取得的成就——强化学习与迁移学习
此外,杨教授提到,人工智能已经在机器学习领域已经取得了突出的成就,特别是在深度学习方面,此外,还特别强调了强化学习与迁移学习的应用前景。
强化学习
杨教授讲到,
强化学习的优点在于它不仅能够学习人的行为,而且能够更好地使用延迟反馈功能
。以Google DeepMind采用的强化学习流程为例,我们可以将这个
流程图
理解为一个计算机内部的表达形式,一个矢量,这个矢量与我们得到的反馈信息相结合,将有助于改进我们采用的策略。流程图中的策略,简单来讲,就是我们平常的行为规划,工作规划,就好比游戏中的一个动作就对应一个策略,这个策略再返回来,产生一个新的界面,如此我们便能够进行持续学习。在这个循环过程中,我们只有到最后才能够获得反馈,称之为延迟的反馈。就好比我们投资一只股票,过了很长时间才知道收益如何。
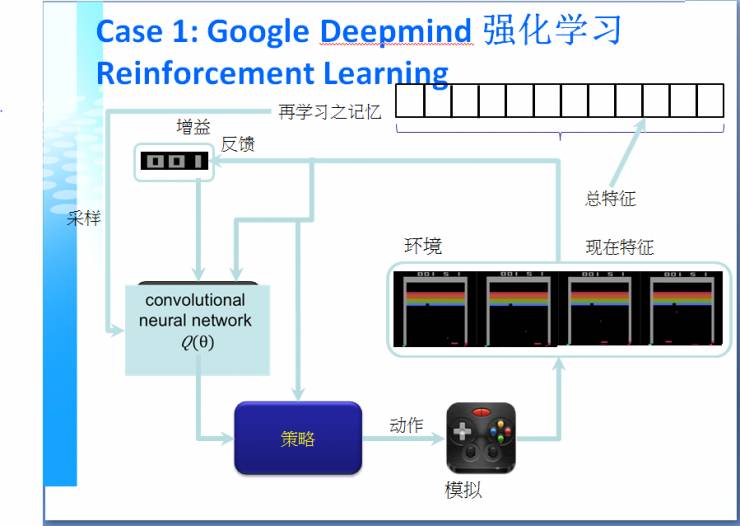
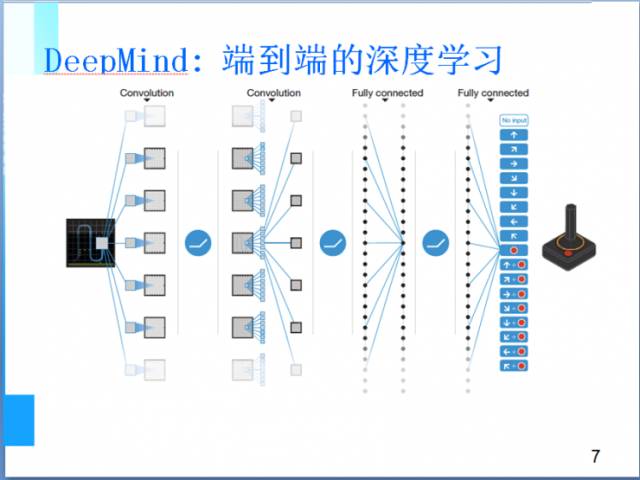
但是,这个循环暴露出强化学习的一个局限性:人们永远无法准确定义这个策略里的空间,我们称之为“状态空间”,即强化学习的结果具有不可预测性。说到这里,杨教授以Google DeepMind的第二个目标——
端到端的深度学习
为例。当该有的状态预先在学习器内表达好后,就形成了一种从输入端到输出端的端到端的深度学习模型,经过几百次的训练学习后,机器将能够学会如何更好地玩一个游戏。
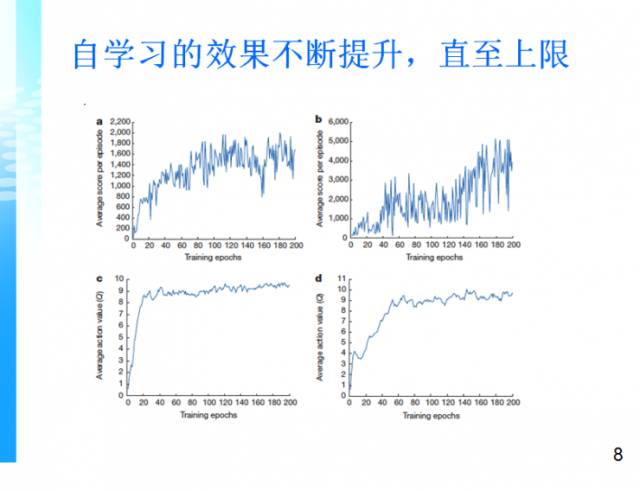
以下各个图对应不同游戏的学习效果。图中横轴表示随着游戏轮数越来越多,机器的自学习效果不断提升,直至达到上限。
迁移学习
迁移学习是深度学习与强化学习的结合体,能够将适用于大数据的模型迁移到小数据上,实现个性化迁移,这样一来能够避免数据寡头的出现。
杨教授提出一点:
大数据设计出来的模型用于小数据上,它的副产品就是个性化。这就是迁移学习的目的。
运用迁移学习把在一个数据领域已经建立的非常好的模型,应用到另一个领域,这样既节省了资源,又能够节省时间,效果又好。
杨教授谈到,我们人很自然就具备这种举一反三的迁移能力,比如我们学会骑自行车后,学骑摩托车就很简单了;会打羽毛球,再学打网球也就没那么难了。
在演讲中,
杨教授总结了迁移学习的四种实现方式,每一种方式都很直观。

第一种为样本迁移
,就是在数据集(源领域)中找到与目标领域相似的数据,把这个数据放大多倍,与目标领域的数据进行匹配。样本迁移的特点是:1)需要对不同例子加权;2)需要用数据进行训练。

第二种为特征迁移
,就是通过观察源领域图像与目标域图像之间的共同特征,然后利用观察所得的共同特征在不同层级的特征
间进行自动迁移。
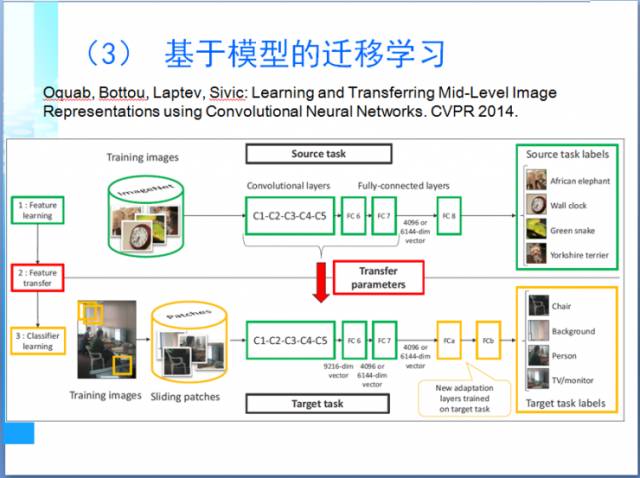
第三种为模型迁移
,其原理时利用上千万的图象训练一个图象识别的系统,当我们遇到一个新的图象领域,就不用再去找
几千万个图象来训练了,可以原来的图像识别系统迁移到新的领域,所以在新的领域只用几万张图片同样能够获取相同的效果。模型迁移的一个好处是我们可以区分,就是可以和深度学习结合起来,我们可以区分不同层次可迁移的度,相似度比较高的那些层次他们被迁移的可能性就大一些。

第
四种为关系迁移
,比如社会网
络,社交网络之间的迁移。
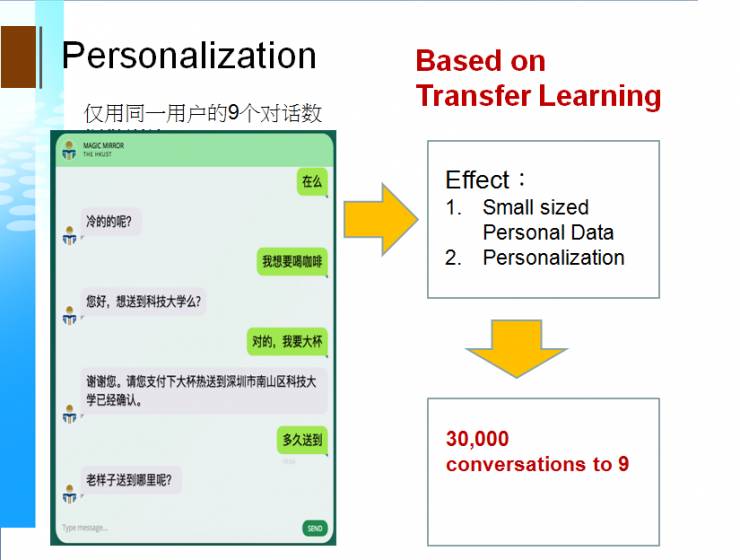
迁移学习的最终目的就是实现AI for Everyone。比如我们利用一个由训练三万个的对话模式获得的大对话模型可以迁移到个人的小型对话中,这种基于强化学习所获取的个性化效果非常具有实用性,因为我们不用繁琐地问用户很多同样的问题。此外,杨教授在会上曾提到一个愿景——利用迁移学习,即使是自身没有条件获得大量训练数据的小公司也可以按照自己的需要应用大公司训练出来的模型,从而普及AI的应用,从而克服数据“寡头”现象。不论怎样,迁移学习是一种极具潜力的解决方案,将在未来大显身手。
运用“魔镜对话系统”实例阐释人工智能成功的五个必要条件
此外,杨教授用一个人工智能技术应用的热点——对话系统,清晰地阐明上述五个条件对人工智能技术发展所产生的推动性作用。
现有对话系统的应用原理
一般来讲,市场上现有的对话
系统可以分为两类:闲聊类与功能类。










