作者:
陈经 (亚洲视觉科技)
计算机处理围棋复杂的能力压倒了人类:AlphaGo技术原理分析
2015 年11 月,“美林谷杯”首届世界计算机
围棋锦标赛在北京举办,连笑七段(现八段,名
人、天元)与获得冠军的韩国程序Dolbram 进行指
导对局。连笑让四子轻松获胜,局中Dolbram 还
犯了可笑的错误,执着地耗费大量劫材反复提劫
想吃一块连环劫净活的棋(图1)。Dolbram 受让五
子也输了,直到受让六子才战胜了连笑。

图1 看到计算机被连环劫迷惑,连笑七段在对局中笑得很开心
围棋中让五子大约有超过50 目的巨大起始
优势,程序却还是输了,职业棋手们认为程序实
力非常一般。围棋程序还明显有各类“bug”,出
现的愚蠢招法连业余棋手都不如。这种情况
下,围棋界难以对计算机围棋的实力给出太高
评价。
围棋界并非不知道AI已经在国际象棋上战胜
了人类。但棋手们以及围棋算法开发者们公认,
与围棋相比,国际象棋的变化还是过于简单了。
对围棋局面数量的简单估算是3
361
种(19×19 个位
置每处3 种状态),但由于无气的棋子会被提吃,
很多局面是不合法的。普林斯顿的研究人员动用
超级计算机,算出19×19 格围棋的精确合法局面
数为2081681993819799846994786333448627702
865224538845305484256394568209274196127380
153785256484516985196439072599160156281285
460898883144271297153193175577366203972470
64840935,这是一个171 位的数字。国际象棋
的局面数约为10
46
,因此从局面数来说围棋比国
际象棋要复杂得多。对围棋艺术更熟悉的人会知
道,围棋的复杂并非只靠状态空间大,而是有
“非线性”、“非平凡”的艺术性:棋子位置稍有
不同局势就可能倒转,选点不多的局部死活正确
行棋次序需要精妙的逻辑推理,人类数千年实践
积累出并仍在发展的“棋理”(如围棋十诀)富有
哲学与人文含义。
棋手们相信,面对计算机,围棋的复杂是人
类的朋友。这种复杂让计算机算法举步维艰,既
难以突破搜索空间的限制,又无法用代码实现人
类含义模糊且数量众多的“棋理”。而人类用理
解力的优势,建立棋形、大龙、厚势等概念,以
此为基础展开逻辑推理,甚至有“手割”这样的
高级分析逻辑。而且人类高手还有优秀的直觉,
绕过庞大的推理树,直接产生高质量的局面候选
点。对计算机有所了解的棋手认为,计算机可能
在局部计算上利用穷举死算的威力占得上风,但
在更高级的全局思维与棋理上弱于人类,从而因
“境界”的差距而毫无机会。
应该如何下围棋,人类有很多知识与教育传
承体系。网络出现后,高手们互相对局的机会极
大增加,成长为顶尖高手需要的时间缩短,少年
高手层出不穷。与前辈相比,棋手们的整体实力
和顶尖选手的绝对棋力都有上升。在法国研究者
Remi Coulom 开发的等级分系统中(媒体称为
Gorating 等级分),就在连笑大胜Dolbram 的2015
年11 月,年仅18 岁的柯洁冲到了3640 分,这是
从未有棋手到过的高度。
但就在之前Deepmind 的AlphaGo 开发团队刚
刚取得了重要突破。在2015 年10 月5—9 日的秘
密对局中,AlphaGo 在正式慢棋比赛里以5:0 战
胜了欧洲冠军樊麾二段(非正式快棋3:2)(图2)。
Deepmind 估计,此时的AlphaGo 的Gorating 等级
分约为3150 分,已经具有职业实力,但离世界第
一柯洁仍有不小差距。

图2 输给AlphaGo之后,樊麾二段难以置信
对AlphaGo 棋力提升速度极具信心的谷歌公
司选择了李世石作为围棋人机大战的对手,并为
此提供了围棋史上最高的100 万美元奖金,让这
次大战瞬间成为焦点。李世石是过去10 年获得世
界冠军数最多的选手,此时年已32 岁不在巅峰状
态但仍然极具实力,2015 年11 月 Gorating 等级分
3540 排名世界第三。接到邀请后,李世石几乎没
有考虑,没提任何条件就接受了。
2016 年1 月28 日,Deepmind里程碑式的论文
在《自然》出版,与樊麾的五盘正式棋谱也公布
了,3 月与李世石的人机大战计划也提出了。棋
界为之兴奋,围棋的世界影响力显然会极大扩
张。棋谱中AlphaGo 的实力虽然让人印象深刻,
但离职业顶尖还有距离,令人羡慕的百万美元丰
厚奖金肯定会归李世石。樊麾的职业段位是在中
国获得的,但是面对AI 发挥如此差劲,可以怀疑
他在欧洲时间太长已经没有职业水平。整个棋界
对AI 的实力没有警惕,虽然科技界有些人预测机
器将5:0获胜,但被认为是不懂围棋的外行话。
2016 年3 月9—15 日的五盘围棋人机大战的
成功超乎想象。围棋AI 战胜人类顶尖棋手这一事
件席卷全球,影响力远远超出了围棋界与科技
界,直接引爆了历史上最火热的一次人工智能热
潮。AlphaGo 以4:1 胜出,让人们看到了人工智能
的无限潜能。当AlphaGo 在第三局以毁灭性的方
式碾压李世石之后,围棋界陷入了无比的震惊与
压抑之中。如同科幻小说《三体》中对战胜三体
星人信心满满的地球人,却被对手一颗小探测器
摧毁了主力舰队。而李世石第四局出人意料获得
了宝贵一胜,揭示了AlphaGo 仍然存在算法缺
陷,为人类反击留存了希望,将这次人机大战推
向了最高潮(图3)。
图3 李世石第四局第78 手下出神之一手击中AlphaGo算法
缺陷的瞬间
整个比赛李世石其实有机会获胜。赛前
Deepmind 就知道AlphaGo 存在缺陷,因此对棋谱
严格保密,仅公布了对樊麾的五局胜局棋谱。如
果李世石知道这个缺陷的触发原理,主动将局势
导向开放空间的接触混战,将有机会多胜几局
从而获得比赛的胜利。如果李世石有警惕性,事
先要求Deepmind 提供几局AlphaGo 的败局棋谱,
找到这个缺陷并不困难。此时的AlphaGo 能够被
后续版本让三子击败,说明存在严重缺陷,被抓
住缺陷时实力会严重下降。
由于有论文与实战表现,AlphaGo 的棋力是
可以深入理解的。这次精彩的人机大战让人们信
服,围棋AI 从算法原理与工程实践上,有能力战
胜人类最顶尖棋手。另一方面,棋手们与研究者
认为,面对围棋的复杂性,围棋AI 仍然存在难于
消除的内在算法缺陷。让棋手们震惊与意外的
是,计算机强大的恰好是人类自豪的全局思维与
境界,而出现问题的反而是人们认为计算机应该
强大的局部计算。科技界的狂野预测成功了,但
事情似乎更有趣一些,围棋也展示了它的复杂。
无论如何,AlphaGo 已经展示了不一样的围
棋观念,让人们知道围棋是自由的,一些人类的
“棋理”只不过是自以为是的错觉。对围棋熟悉
的人,会明白AlphaGo 第二局第37 手在五路尖
冲是一件多么震憾的事(图4)。AlphaGo 出现之
前,棋界由于思想禁锢以及竞技性的原因,布局
单调重复,精彩程度下降,有走入误区的趋势。
AlphaGo 的横空出世,预示着一次新的围棋革命
即将发生。
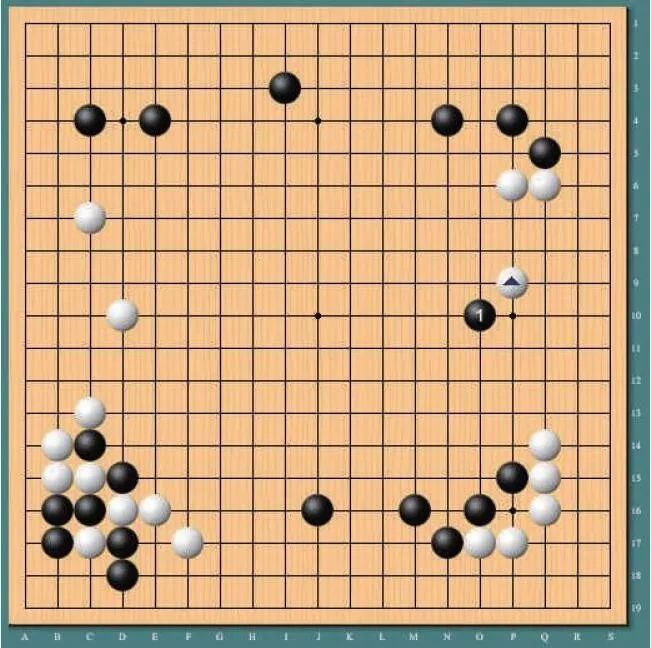
图4 AlphaGo 对李世石第二局,第37 手极具震憾力地在
五路尖冲
2016 年11 月7 日,Deepmind 宣布AlphaGo 又
取得了巨大进步,将于2017 年初复出下棋。人们
普遍推测这是与柯洁的第二次人机大战,但后来
的情况再次让棋界出乎预料,而且出场表演的AI
不止AlphaGo一个。
2016 年11 月,腾讯参考Deepmind 论文开发
的围棋AI“绝艺”取得了重大突破,开始在网络
对弈平台野狐围棋上挑战顶尖高手,并在20 s、
30 s 快棋中战胜了柯洁、朴廷桓等顶尖高手。日
本老牌程序Zen 升级为DeepZenGo 初步具备职业
实力之后,2016 年12 月29 日开始在弈城围棋网
上与职业和业余高手密集测试。绝艺对顶尖职业
的战绩要好于DeepZenGo,但是二者都显现出了
AI 的特点:大局观占优,局部计算会出现各种问
题。棋手们也总结了一些对付AI 的招法,如柯洁
介绍的经验:做大模样,等它打入进来犯错。
几乎与 DeepZenGo 同时,升级后的 AlphaGo
以 Master 为名在网络上与顶尖棋手们进行了5 天
60 局测试,并获得了全胜。虽然20 s、30 s 的快
棋不利于人类棋手发挥实力,但是绝大多数棋局
人类棋手早早就陷入必败局势,这昭示了双方实
力的巨大差距。高手们更看重的是Master 远超绝
艺与DeepZenGo 的创新能力,开盘点三三这类让
棋手们震惊的创新很多。AlphaGo-Lee 版本下的
基本还是人类棋手熟悉的招法,只是大局观偶尔
带来震惊。而Master 下的是另一种围棋,从开局
就展示了不一样的围棋观念。
剩下的悬念是,60 局中Master 由于早早领先
而没有面对复杂的局面,人类棋手在慢棋中有没
有机会制造复杂?AlphaGo 面对复杂会不会出现
计算错误?实力不断进步的绝艺与 DeepZenGo 在
网络与正式比赛中与人类棋手多次对局,似乎为
此提供了一些有利证据:人类棋手在慢棋中确实
有机会等到AI的漏洞而获胜。
这个悬念在2017 年5 月23—27 日AlphaGo 与
柯洁的三盘人机大战后终结了:柯洁有能力制造
复杂局面,AlphaGo 有能力应对复杂局面,处理
复杂局面的能力超过人类想象。
第二局柯洁表现非常好,Deepmind 负责人哈
萨比斯在局中两次根据后台数据公开称赞。至
119 时,黑白双方共有多达9 块棋没有安定搅杀在
一起,还有天下大劫要开,之前从未有棋手面对
Master 实现这种局面(图5)。局中柯洁本人与一些
职业棋手、棋迷都感觉有机会了,情绪激动。但
是这个局面AlphaGo 还是完美地应对下来了,柯
洁开劫出现误算迅速失败。
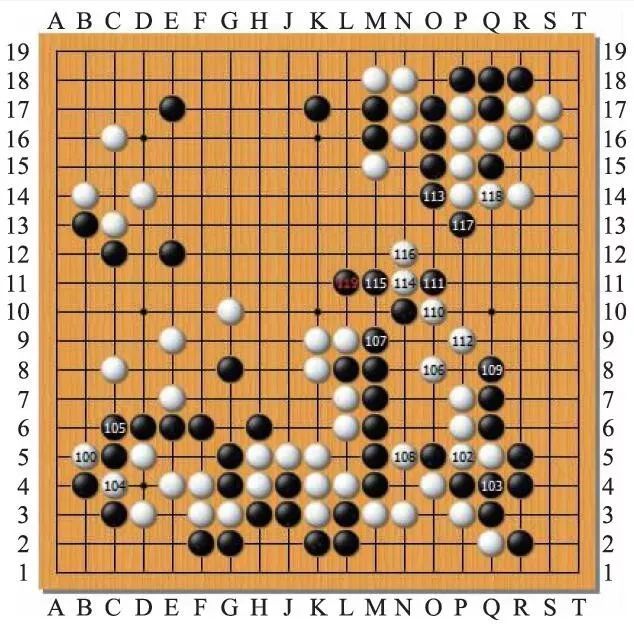
图5 第二局柯洁执白对AlphaGo时的复杂局面
赛后Deepmind 公布了AlphaGo 的50 局自战
谱,2017 年7 月又在围棋TV公布了另外5 局自战
的详解。这些自战谱对抗非常激烈,复杂的局面
很多。冷静下来的棋手们认识到,也许柯洁在第
二局的“机会”只是一种错觉,局势还在AlphaGo
的控制之中。
围棋确实比国际象棋复杂得多,但现在情势
倒转过来了。围棋的复杂在之前让人类遥遥领先
于AI,然而一旦算法取得突破,遥遥领先的迅速
变成了AI。人类还有希望和国际象棋AI 下和,
但围棋复杂的局面远远超过了人的能力,即使最
顶尖高手可能也得接受被AI 打到让二子的苦涩结
果。与AI 进行极限对局需要的计算量,是人类
大脑承受不了的,双方就像跑车与博尔特一样,
不是合适的对手。与柯洁赛后,Deepmind 宣布
AlphaGo退役可以理解,与人类的分先对局已没有
意义。在围棋上,人类败于计算机虽然比国际象棋
晚了一段时间,但败得更彻底,差距要大得多。
AlphaGo 的自战谱让人们认识到,它与自己
对战时才需要拿出全部本领,已经不是在用人的
方法来下棋了。双方差距极其接近、每步背后都
有极多计算、步步紧绷的极限对弈方式,棋手们
连理解都有困难,自己上场跟不了多少步就会犯
错脱轨败阵。柯洁一开始对围棋AI 的实力并不信
服,但通过实战仔细体会AI 的棋力之后,柯洁认
为,“人类数千年的围棋都是错的,甚至没有一
个人沾到围棋真理的边”,“围棋没有什么不可
能”。与AlphaGo的三局大战后,柯洁仿佛得到了
境界提升,对多位世界冠军在内的人类对手22 连
胜(2017 年7 月19 日才被时越九段终结),Gorating
等级分最高冲到了3681,并在网络上让二子与职
业低段对局胜多负少。
AlphaGo-Ke 能100%战胜Master 版本, 能让
三子战胜AlphaGo-Lee,由于Deepmind 仍未公布
详细论文,这种让人难以置信的实力进步尚只能
从算法原理上作出一些推测。本文将在第二节介
绍围棋AI 算法的主要技术,对围棋AI 处理围棋
复杂的能力为何超过了人类作出技术解释。
图6 中的3 人是AlphaGo团队的核心成员。哈
萨比斯创立了Deepmind公司,认为机器可以通过
自我对弈解决一切完全信息博弈问题。席尔瓦的
算法天才对AlphaGo 的强大至为关键,有多种算
法创新。黄世杰在人机大战时代替机器落子,他
对围棋AI开发多年的积累作用很大。

图6 AlphaGo团队负责人德米什·哈萨比斯,以及两位核心算法研究者大卫·席尔瓦
与黄世杰
国际象棋与围棋一局的步数与每步的选择都
很多,搜索树极大。将棋局展开一定的步数,对
展开的局面建立局面评估函数,代替之后的搜
索。这个剪枝非常有效,让深蓝在国际象棋上战
胜了人类。席尔瓦与黄世杰十多年前开始开发
围棋AI 时就知道,这个方法对围棋行不通,搜索
太复杂,评估函数也很难建立。早期围棋AI 的
代表是中山大学教授陈志行退休后开发的“手
谈”,曾连续6 次获得计算机围棋
世界冠军,但棋力不高,连业余
初段都达不到。
取得突破的是“蒙特卡罗树形
搜索” (Monto-Carlo Tree Search,
MCTS),早期代表程序是Coulom
开发的CrazyStone。想象从一个
围棋局面展开一个深度为d 的搜
索树,派多只蚂蚁从根节点随机
选择分支往下爬。爬到叶子节点
时,就一人一手直接下完(rollout)终局数子给出
结果,胜蚂蚁活,负蚂蚁死。时间到了,就统
计蚂蚁的死活,活蚂蚁最多的分支就是当前的
行棋选择。这个框架绕开困难的局面评估函
数,而是直接精确计算终局胜负,海量模拟至
终局用获胜概率代替局面评估。AlphaGo 以及其
他围棋AI 局中不断报告的“ 胜率”, 就是指
MCTS 中的模拟胜率。每个推荐选点都会给出对
应胜率,不同选点的胜率接近,可以随机选择一
个,所以围棋AI 自我对弈或者与人对弈并不会重
复局面。
随着AlphaGo 的新闻效应,很多人也知道了
MCTS。但是单纯的MCTS作用不大。CrazyStone
和MoGo 等程序取得棋力突破,是应用了MCTS
加上UCB(Upper Confidence Bound)公式的UCT方
法,选择搜索分支时有了很强的针对性,不将
算力浪费在无意义的分支上。UCT使得MCTS在
有希望的分支上扩展步数超过之前的d,增强了
搜索能力。理论证明,只要模拟次数够多,概率
结果就会逼近真实搜索结果。概率搜索可以随
时停下给出当前结果,方便围棋AI 的时间控制:
快速停下来给出一个过得去的结果,具备快棋能
力的AI 更受棋界欢迎。AlphaGo 并非凭空产生,
也应用了MCTS与UCT。
大的框架有了,程序细节就更为关键,例如
rollout 策略对棋力非常关键。MCTS 的后期代表
程序是Zen,在行棋细节上作出了很大改进。虽
然在UEC 杯接受职业棋手指导时还要被让3—5
子,但在2011 年前后,Zen 已能战胜一般业余棋
迷,进步让人印象深刻。这时的高水平围棋AI 还
会犯一些愚蠢的错误,但已经展示了一个很大的
优势:大局观很好。依靠MCTS 天生的全局思
维,围棋AI 的大局观已经超过了一些布局不好的










