
文末有喜
作者简介:

胡凯
bilibili, 运维负责人
从系统测试到自动化测试到性能测试再到运维,对服务端的兴致带他一步步走近互联网、步入运维行列。丰富的经历,让他对运维有着独特的思考和认知。
前言
随着互联网的高速发展,我们经历的数据量越来越大、越来越重,运维也越来越重要。
有幸参加“GOPS2017·全球运维大会.深圳站”,希望通过本文和大家分享过去一年多时间里B站运维监控系统的发展历程以及我的思考。
一、自动发布
回想
2015
年中入职
B
站,运维部才正在成立。铺面而来的各种事务,压得我和运维小伙伴们喘不过气来。
想想有好多系统要做,虽然忙得没时间也没人做。
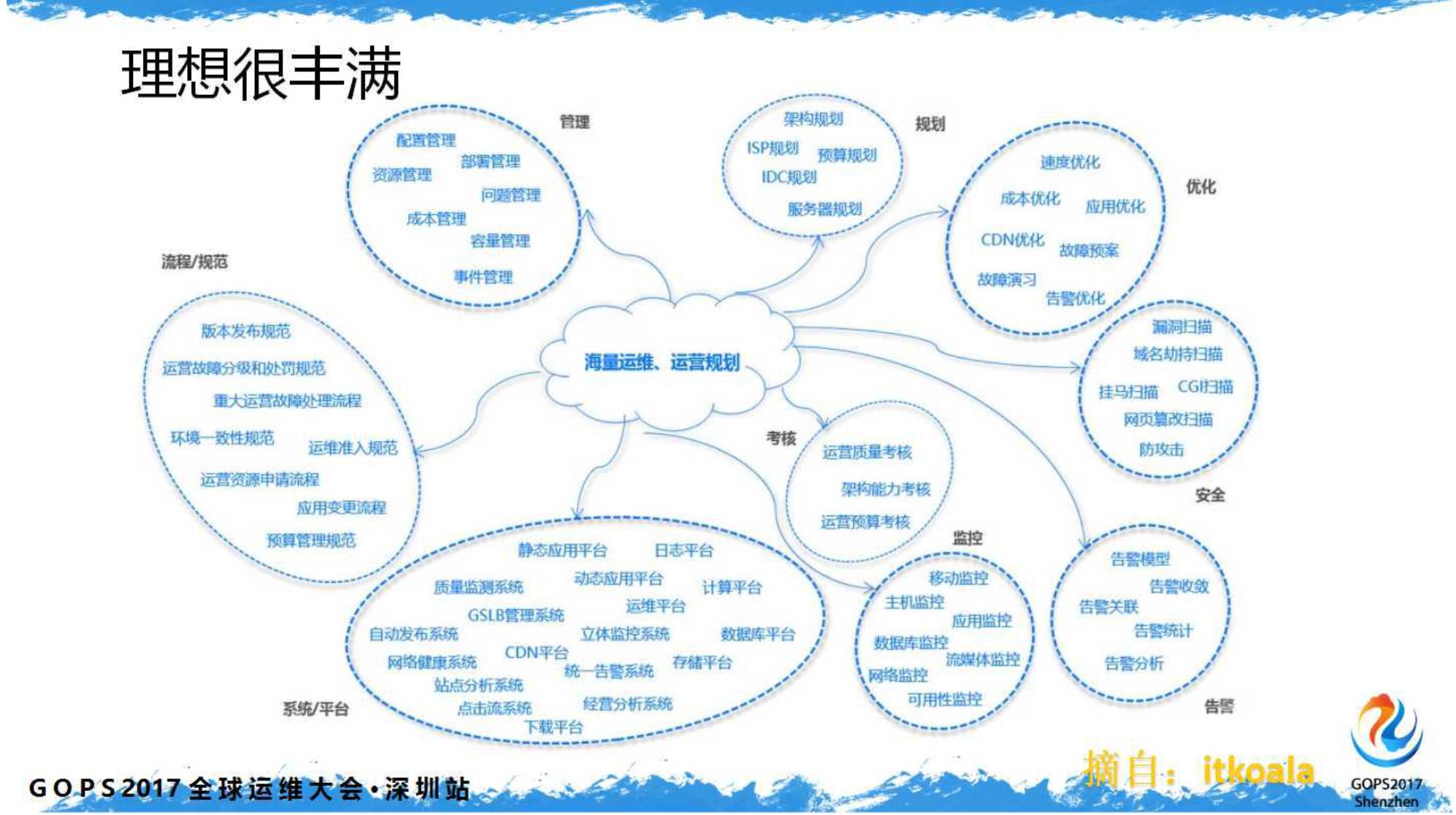
按过往经验,掐指一算:
要寻找破局点、尽早做出第一个改变!
当时最耗精力的就是发布,没多久我们看准了从发布着手,先把劳动力解放出来。于是做了简单的发布系统:

基于
OpenLDAP
和谷歌的“身份验证器”作为认证,
Gitlab
作为代码托管,按需接入
Jenkins
构建,在堡垒机上包装
Ansible
(脚本也在
Gitlab
上),用命令行完成批量部署上线。
初见成效后,简单包装了一个页面、加了发布时间的控制就开心的用起来了。
二、必须做监控
我们服务端典型的应用场景如下图:

用户访问到边缘的
CDN
节点,然后通过二级缓存最后传到核心机房的四层负载均衡
LVS
集群,再通过七层
Tengine
的
SLB
集群按规则分流到各个应用里。
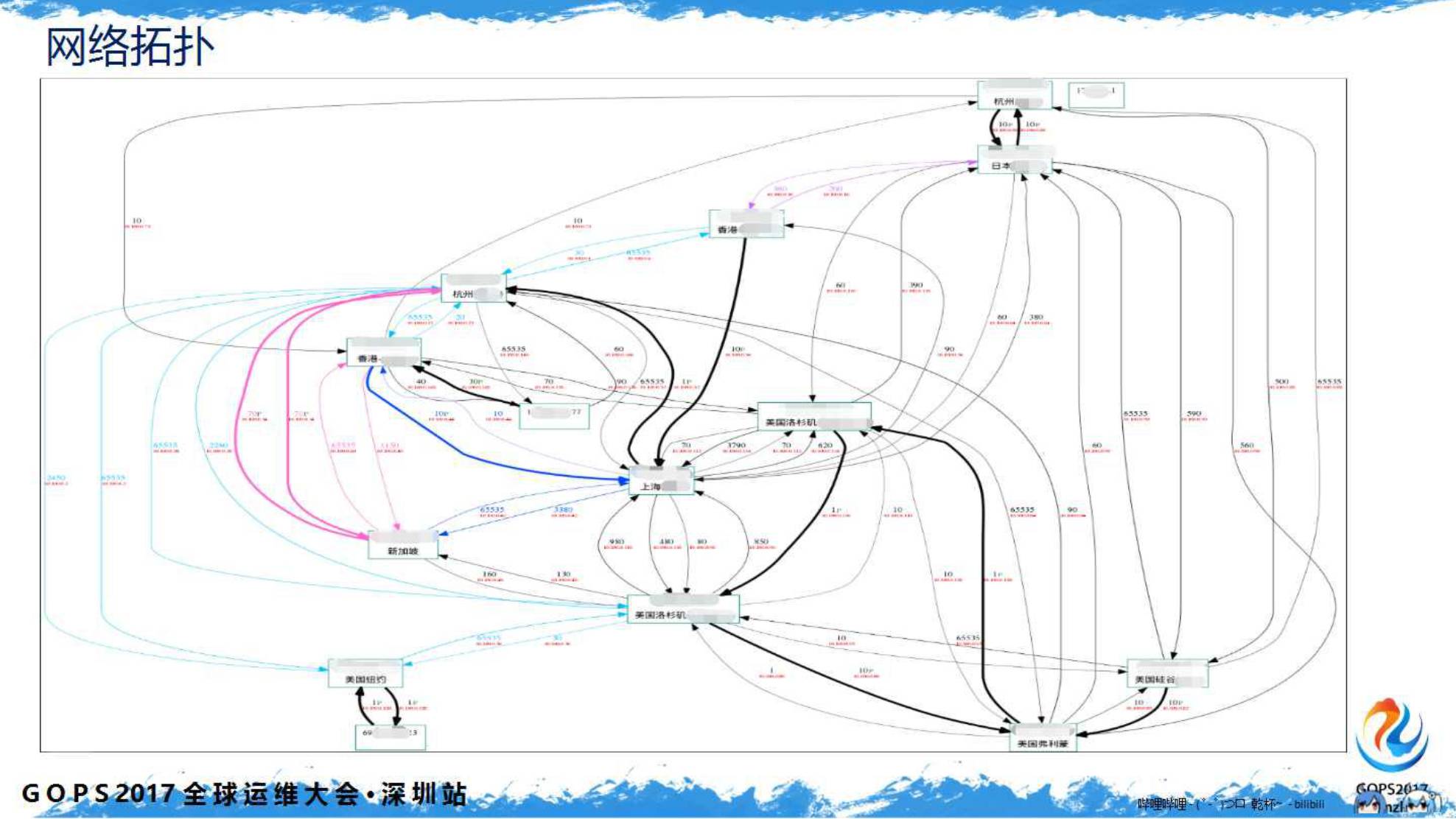
典型的应用后端会有缓存、队列,然后再到数据库。开发语言有
Go
、
Java
、
PHP
、
Python
、
C/C++
等(排名不分先后)
那么问题来了:“监控呢?”
B
站工程师气氛很浓,热爱开源。连
DNS
都自研、
CDN
自建,链路长、监控少,随业务增多定位问题变得非常困难。
三、第一个报警:
ELK
很多人心里都有一套运维自动化系统,而且是闭环的。在有效资源里,从哪里开始呢?
原计划本是打算自下而上,从主机监控一步步往上走。而后发现不少用户反馈的问题,后端无感知。
鉴于
CDN
日志都在手上,用户最开始接触的就是
CDN
。索性把错误日志给收回来,错误多了就报警。于是
ELK
诞生了:
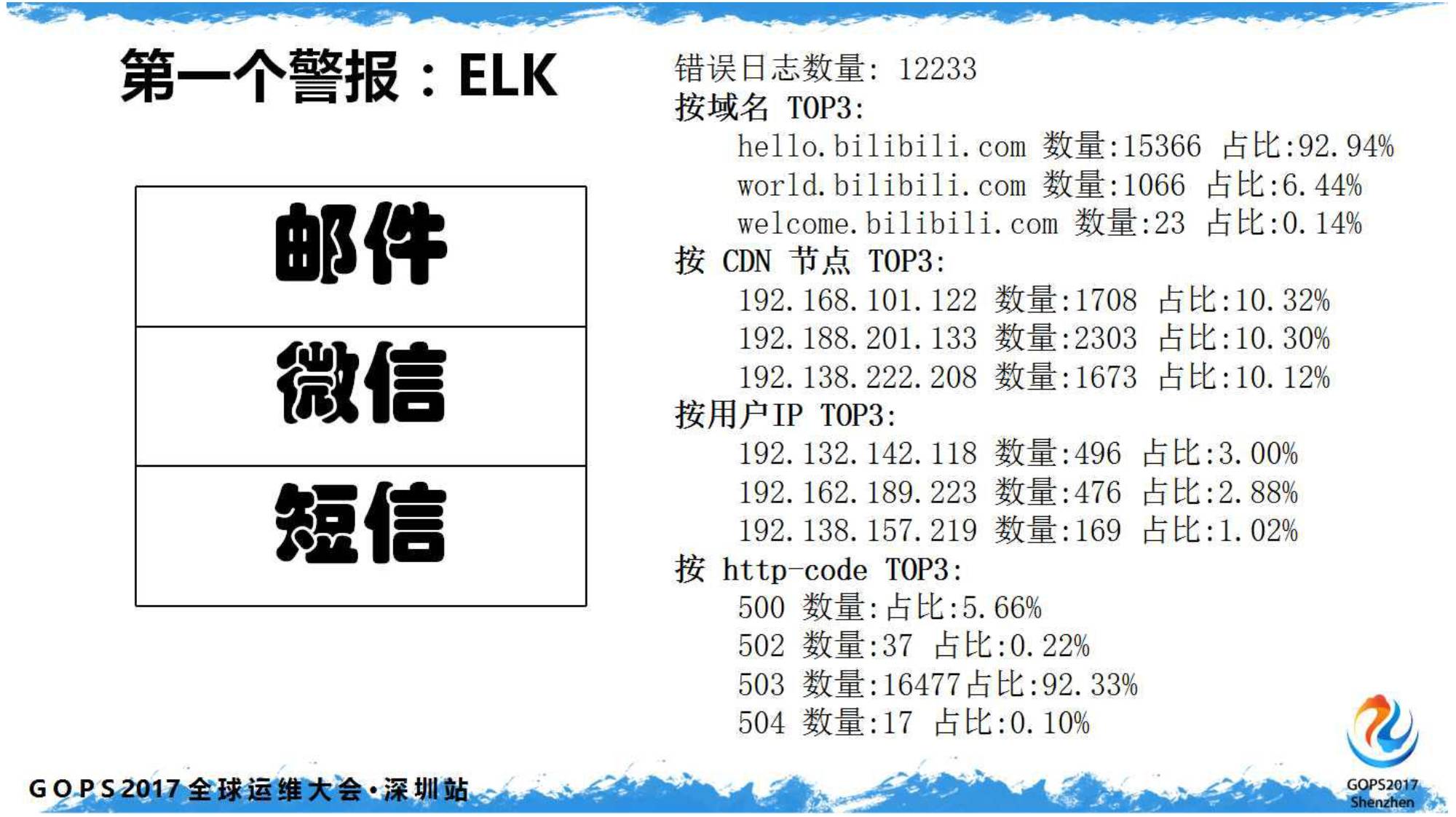
我们仅收错误日志,塞到
ElasticSearch
里,按域名、
CDN
节点、用户
IP
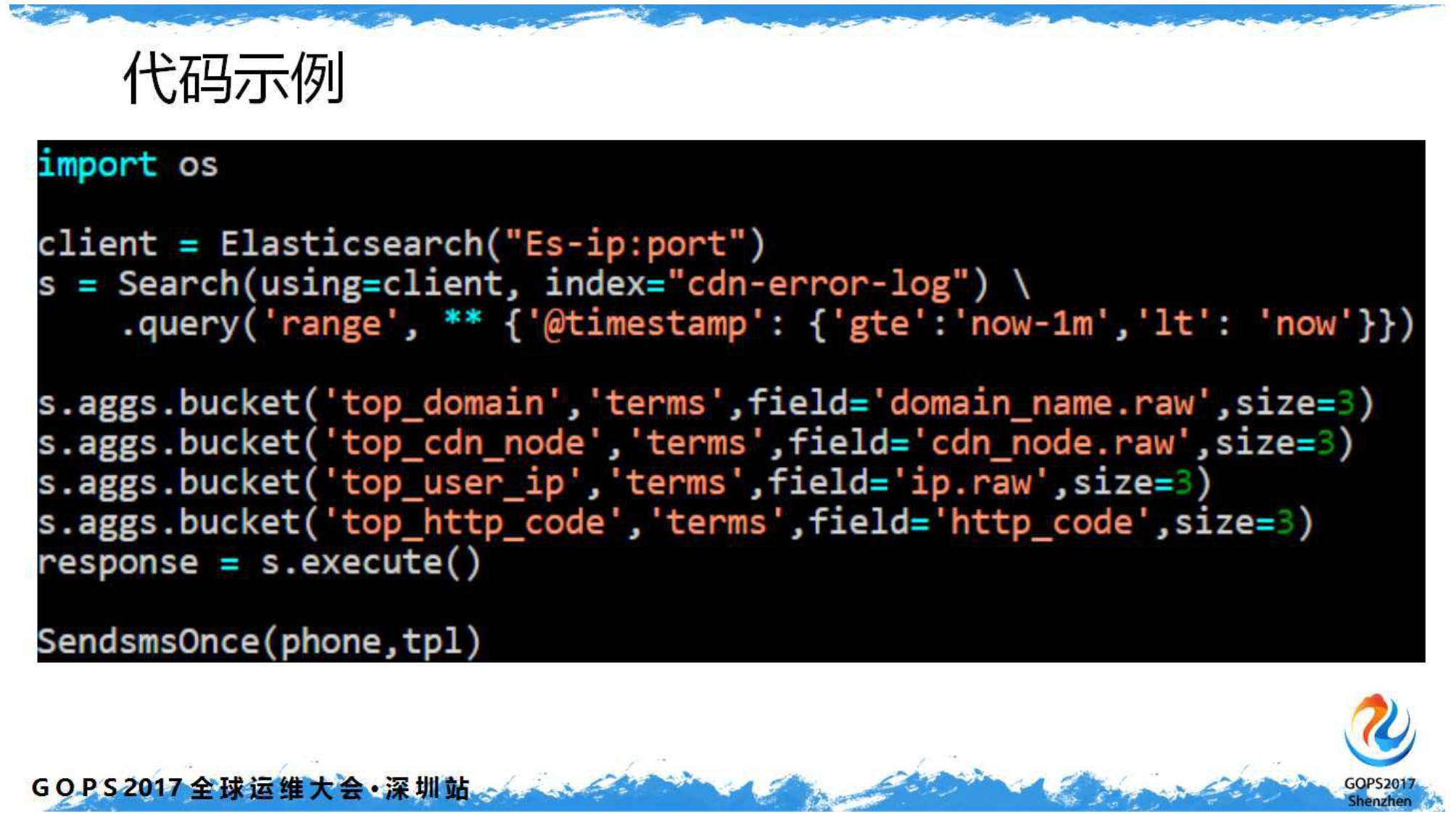
以及错误码进行分类排序。
这样当收到报警短信时,基本第一眼都可以锁定一个故障区域了。随后稍加流程,接入微信完美收工。
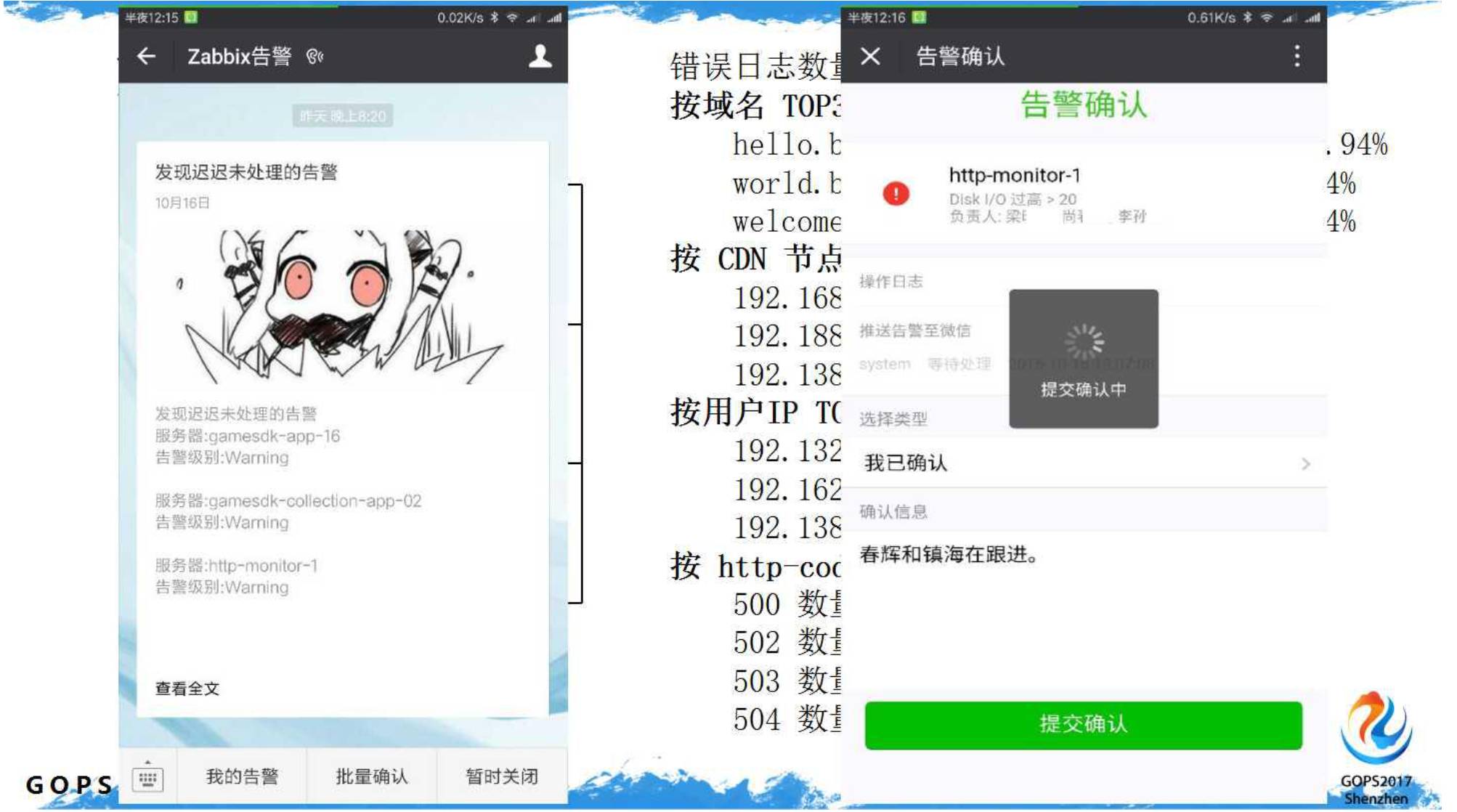
以下是报警短信的代码片段,计划任务第分钟执行(很土很有效)。另外还有个脚本监控错误日志的数量,但数量为零时也会报警(你懂的)。
四、可惜还是你:Zabbix
做完
CDN
监控,我们想回头把基础监控做起来。经过开源、自研
各种讨论,综合下来还是选择了
Zabbix
。因为它实施快、报警策略灵活、会用它的人多容易招。
五、监控交给你:Statsd
好,
CDN
前端的错误监控,应用底层的系统监控都有了。应用自身的监控怎么做呢?根据当时同事的过往经验看,怎么熟怎么来。那就
Statsd
吧!
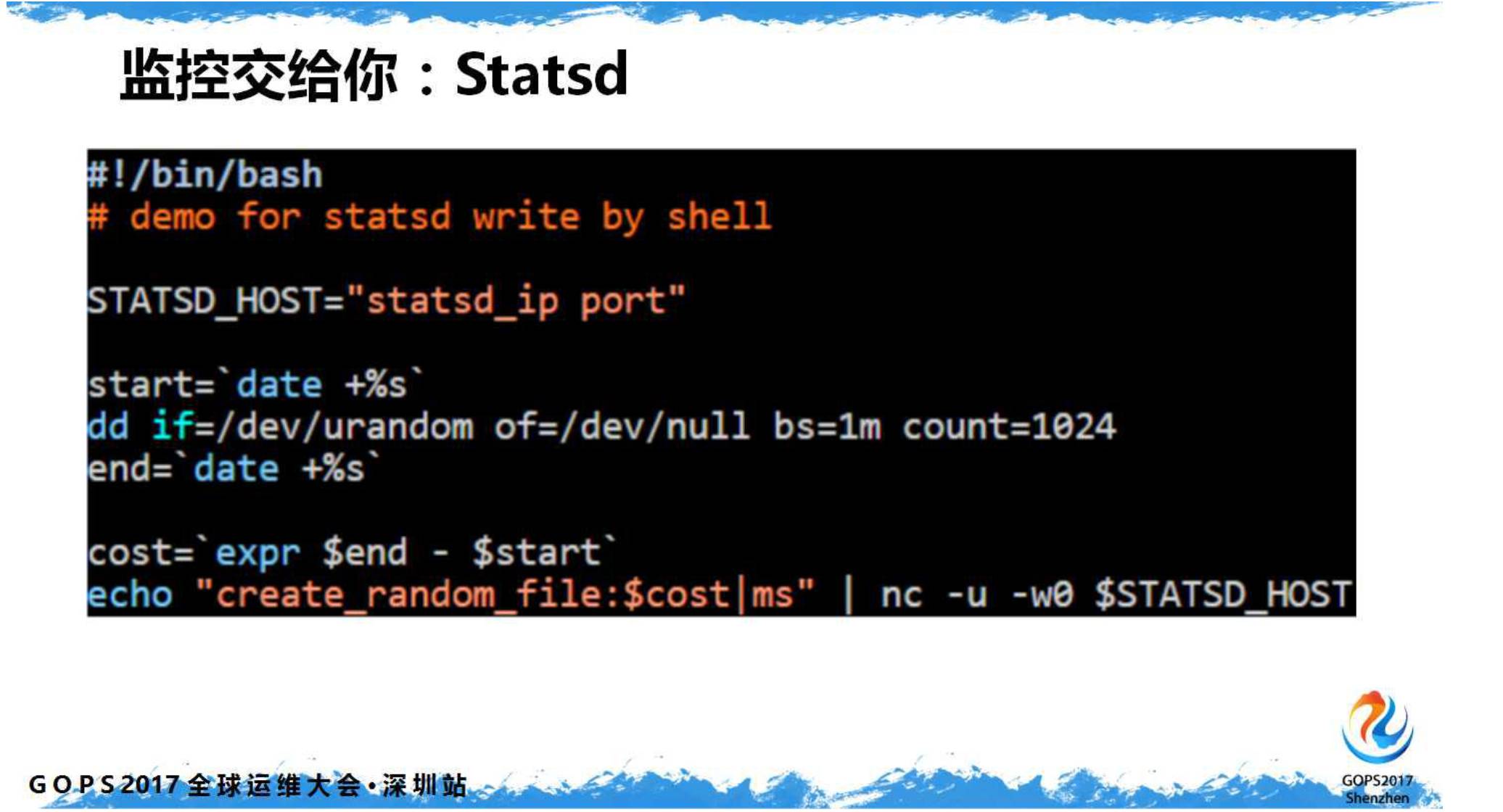
Statsd
用起来比较简单,只需要开发在他关注的代码前后加上锚点就可以了。
默认是
UDP
协议上报数据(天生自带异步光环),不容易出现由于监控影响到程序本身。下图是在
Shell
脚本里做
Statsd
监控的示例代码:
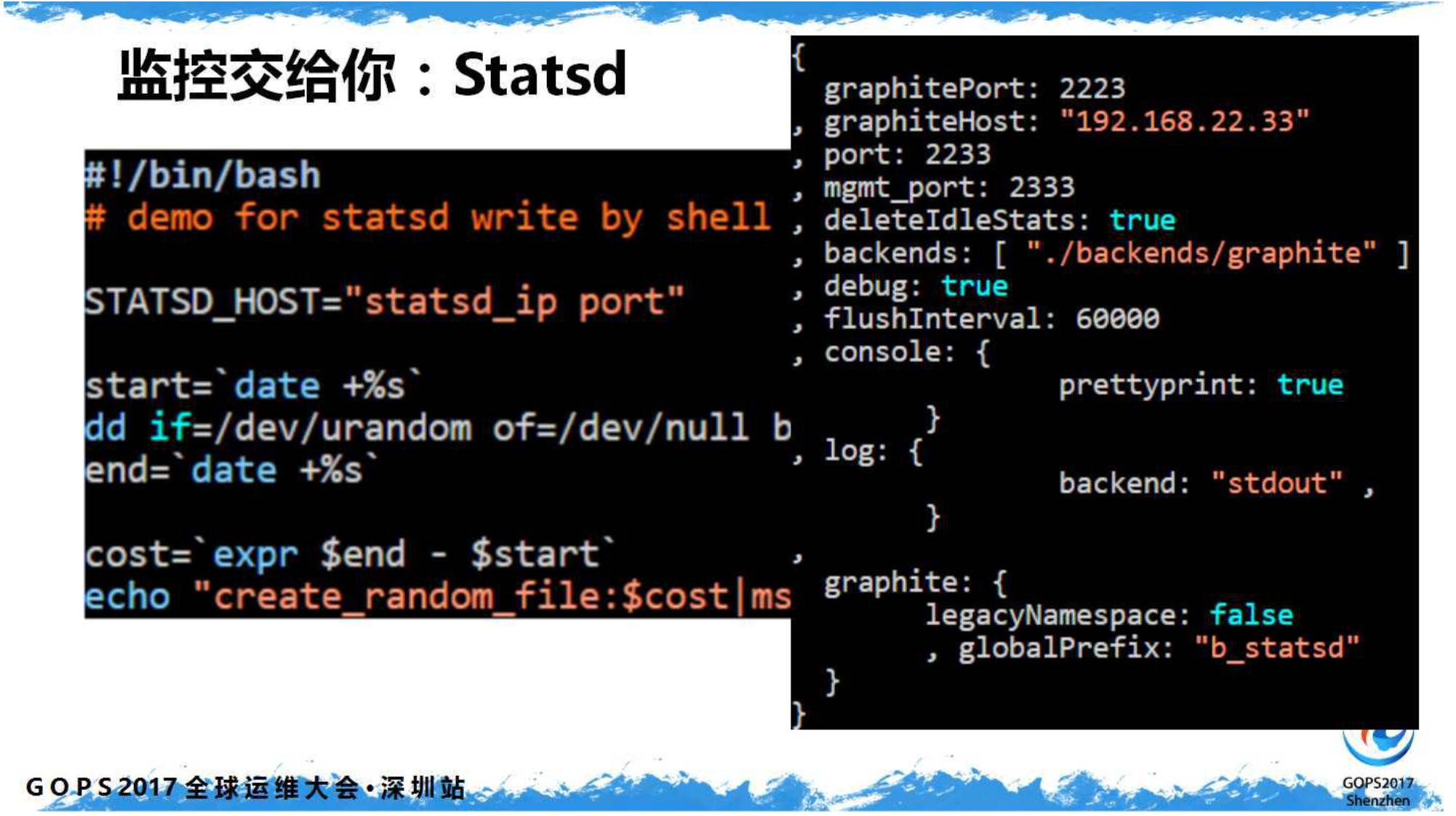
搭好一套
Statsd
收集器,配置一下
Graphite
就能出图了:
前端用
Grafana
包装一下,一个完整的
APM
监控闪亮登场。以下图例为某接口的平均响应耗时:
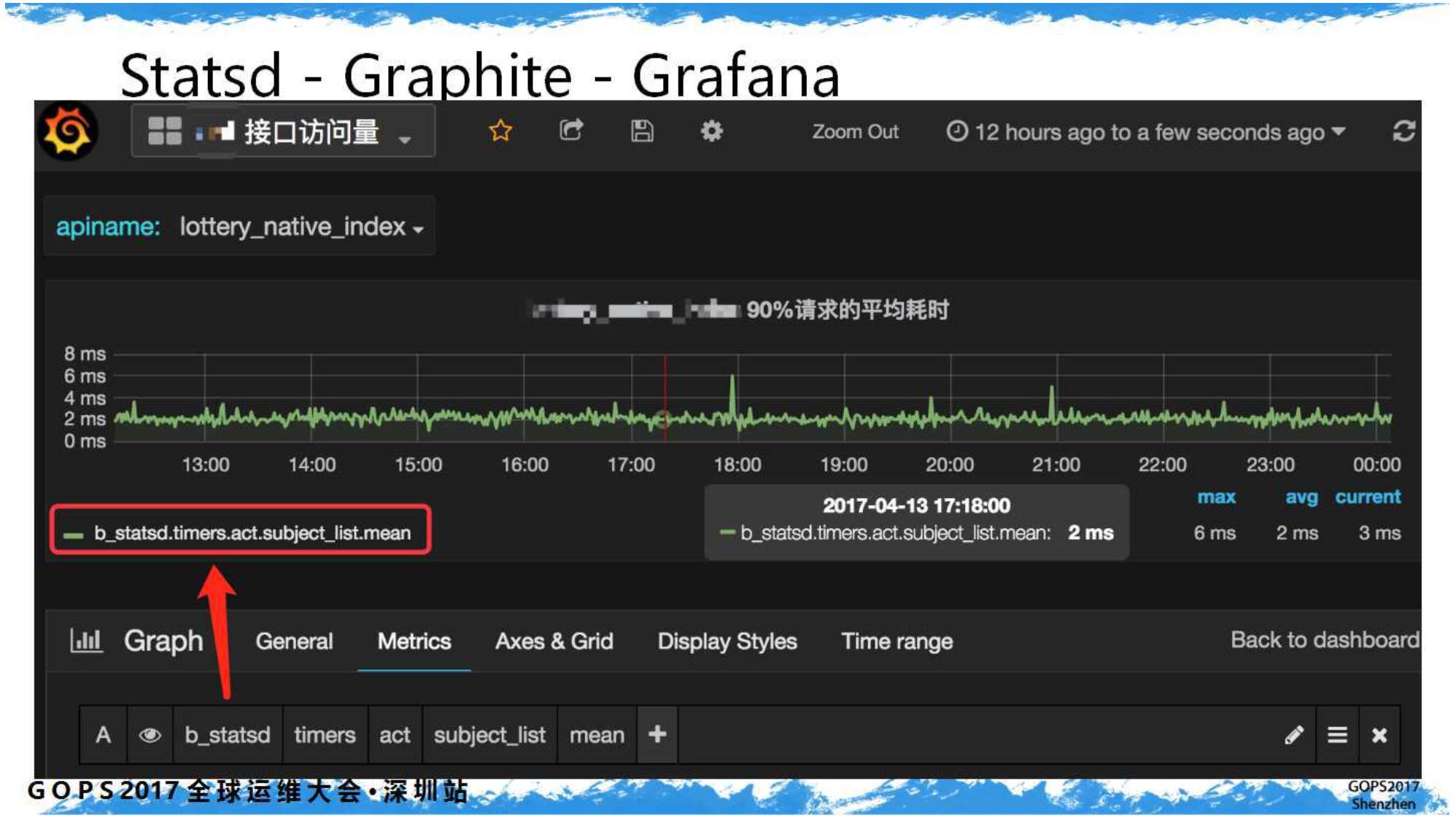
六、百花齐放:Grafana
网传
Grafana
有插件可以直接通过
API
读取
Zabbix
的监控数据,然而没多久新版本的
Grafana
就默认自带了此光环。
然后我们就开心的给
Zabbix
装上了
Grafana
套件,和
Statsd
的监控数据整合在一起、易用性加一分。
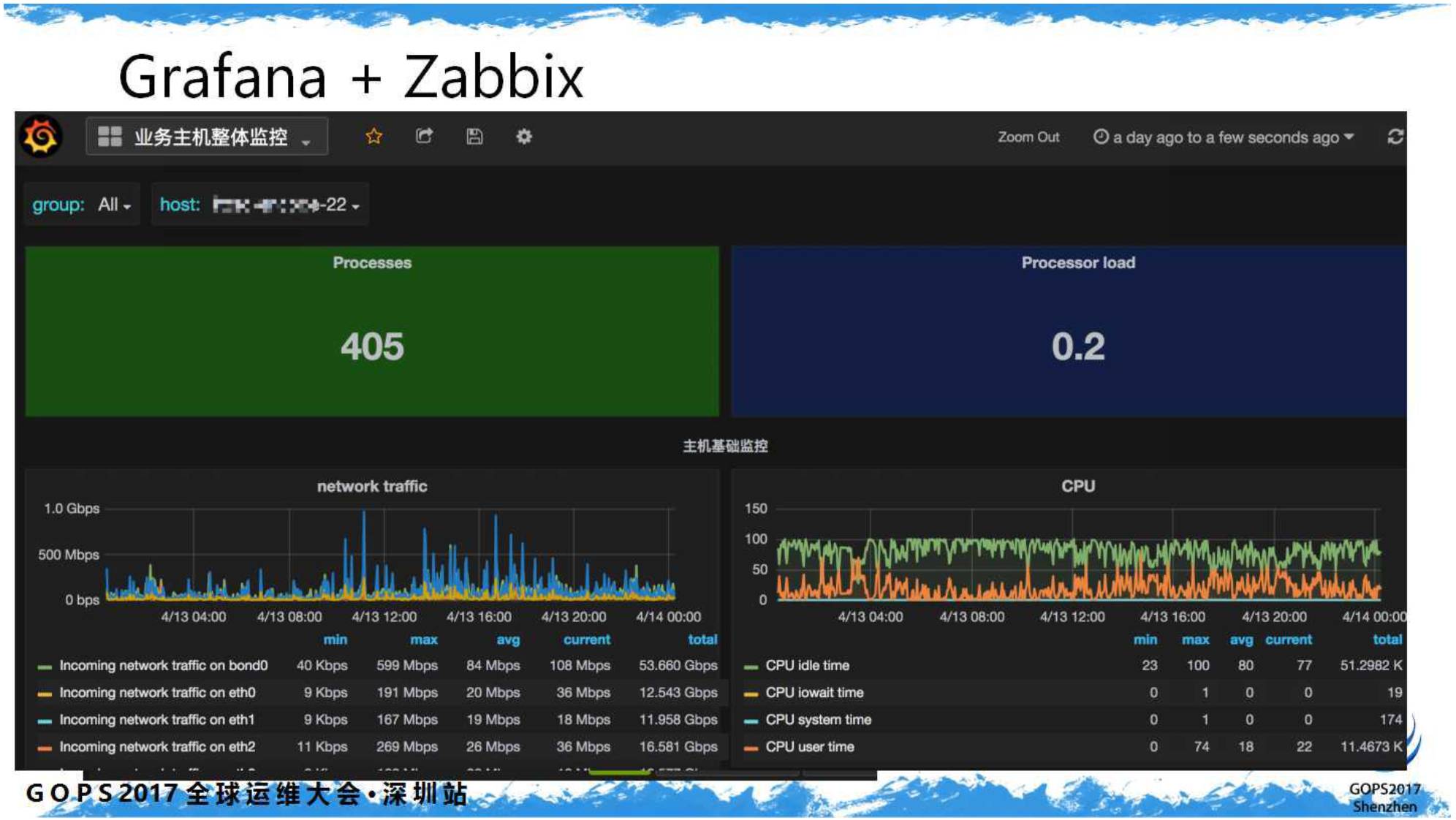
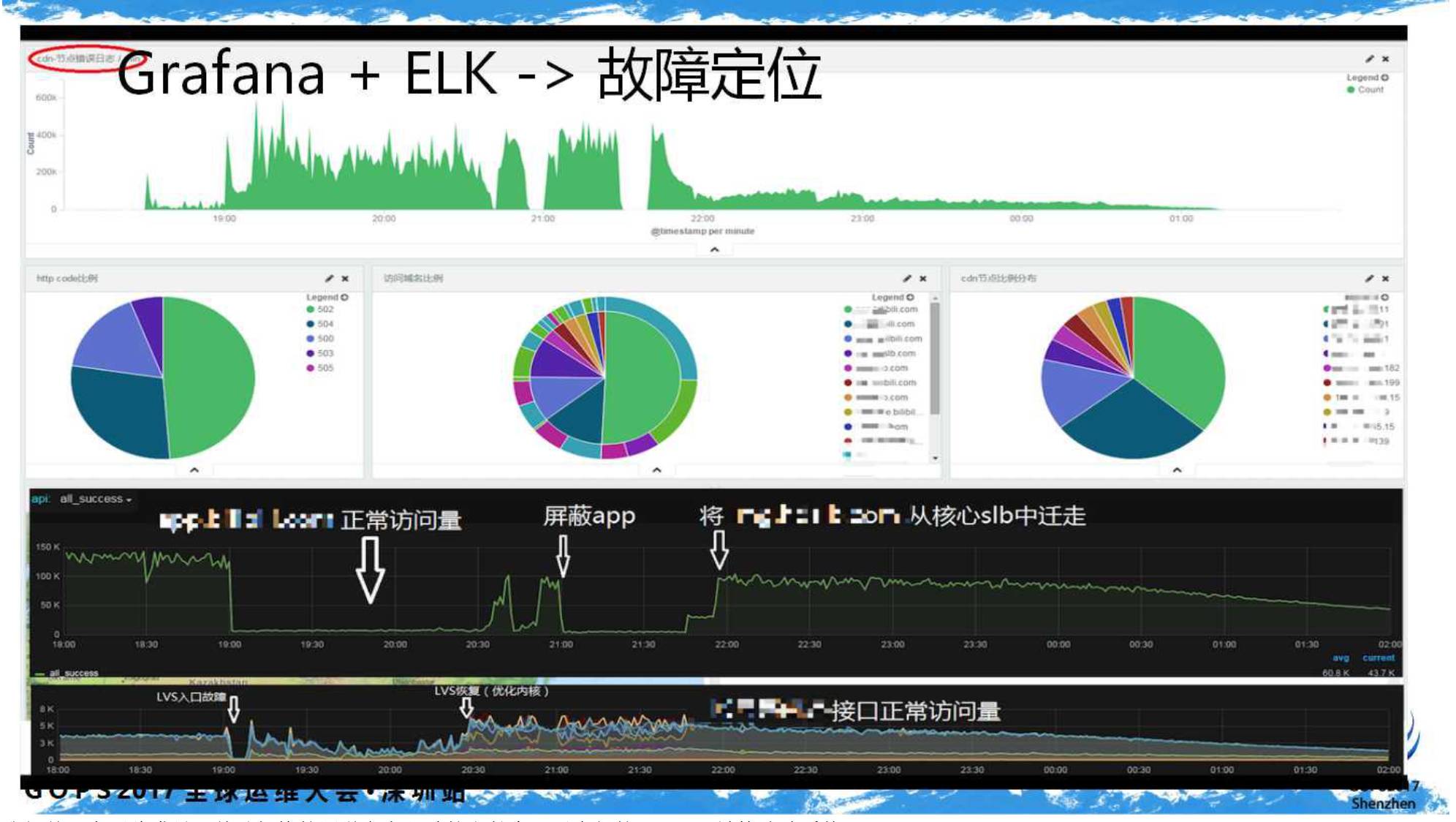
此时结合
CDN
错误监控、应用层
APM
监控、底层数据监控,联运查问题某些时候感觉很舒适。下图为一次故障过程的追踪:
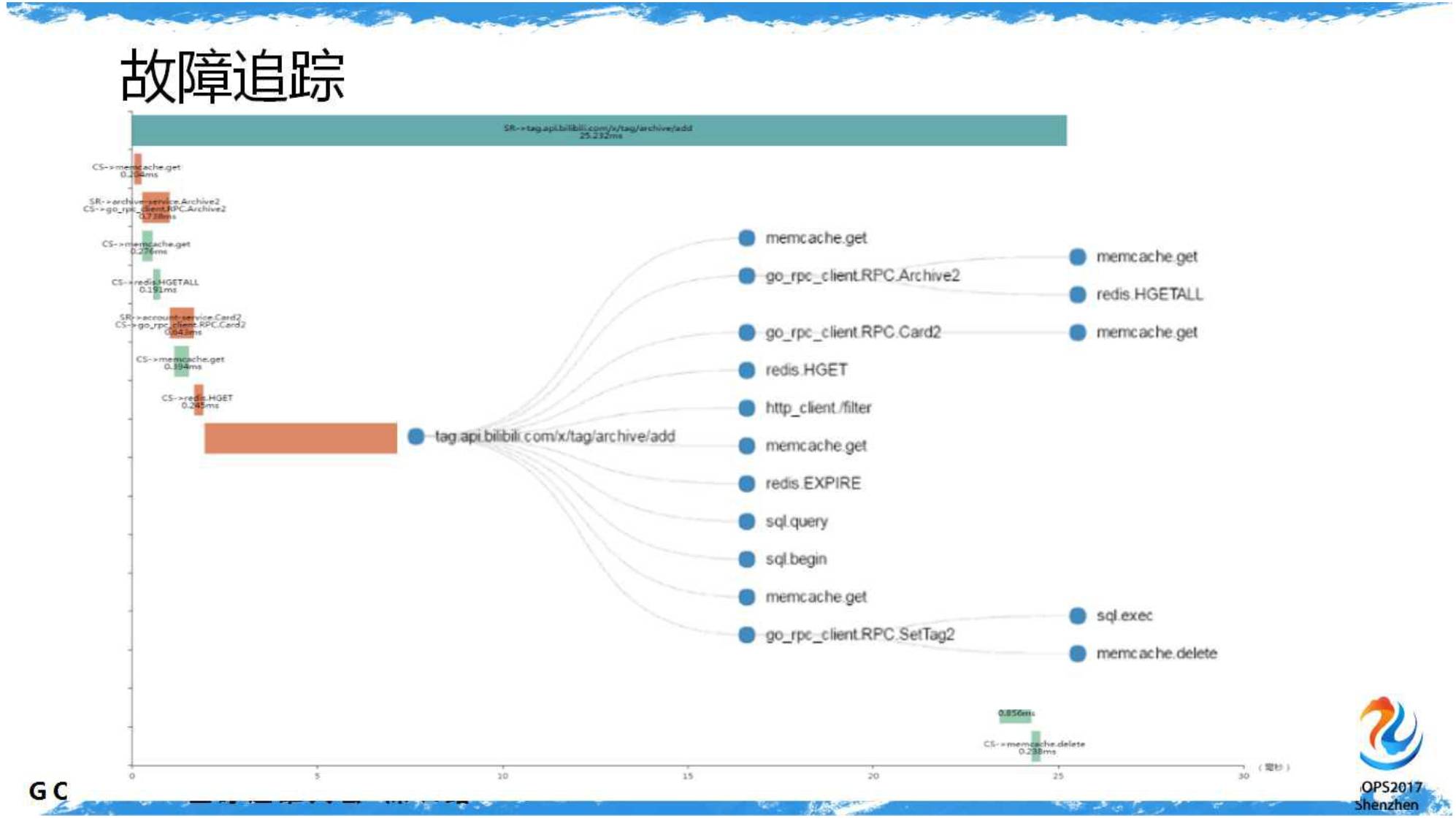
我们并没有因此满足,基础架构的同学参考谷歌的文献实现了内部的
Drapper
链接追踪系统。
请求从
CDN
入口开始就会携带
TrackID
,甚至不忘在
SQL
的查询语句里把
TrackID
带上。以至于追踪得很细致,哪里什么原因耗时最长一目了然。图示:
七、突破壁垒:Misaka
做完如上监控,发现仍然有用户反馈问题时我们束手无策。因为我们没有收到任何与此用户相关的错误信息……
可能网路过程出现了未知原因,比如“被加速”、“功能问题”、“异常退出”等等。
于是我们的舆情监测系统
Misaka
上线,和
CDN
错误日志思路相同;不同的是客户端是真客户端,突破了服务端的壁垒。
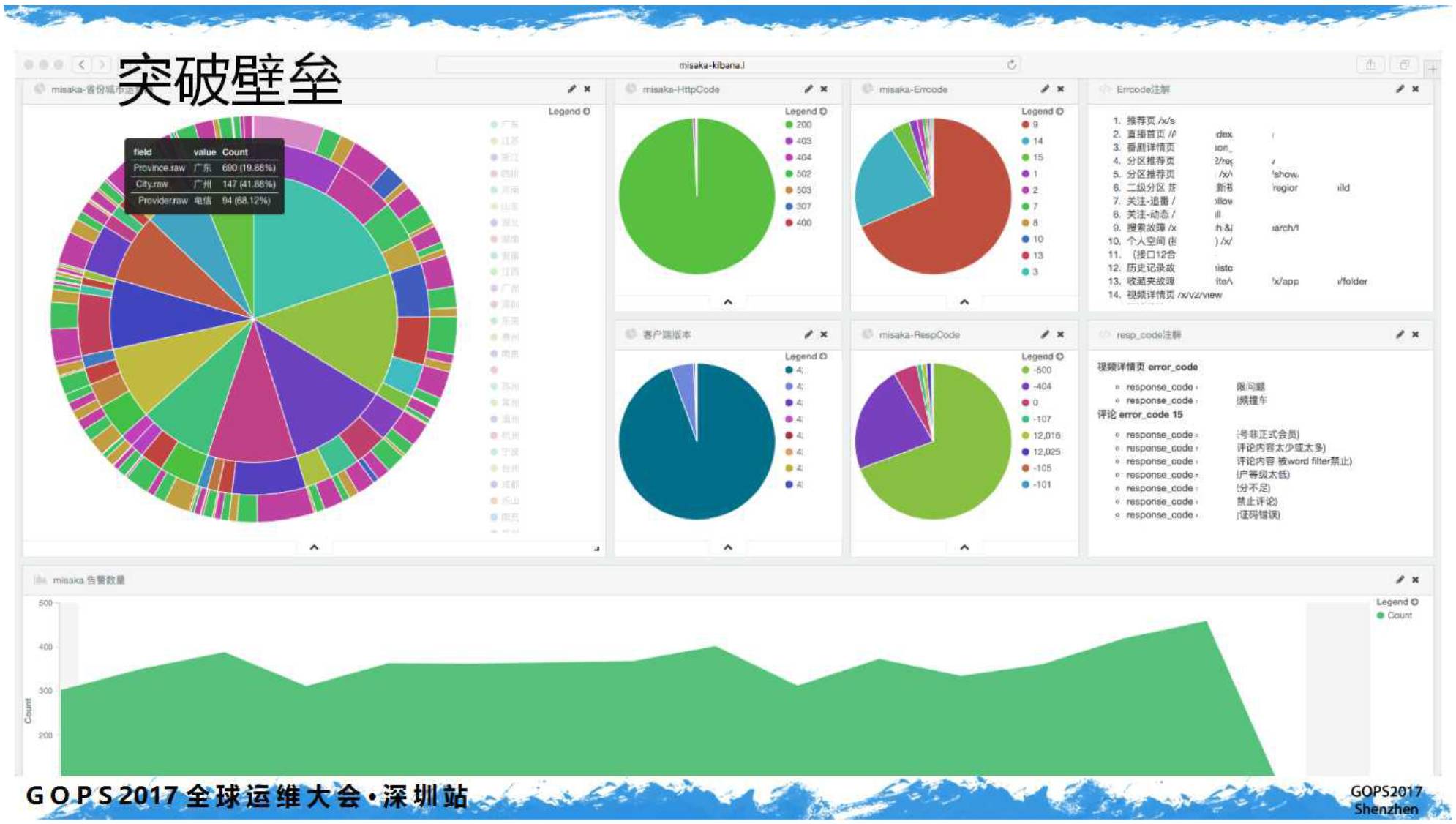
由于
Misaka
上线的受众群体更广,我们简单包装了一下界面(虽然我觉得
ELK
更漂亮)、添加了历史数据的比较。更利于分析,下图示例:
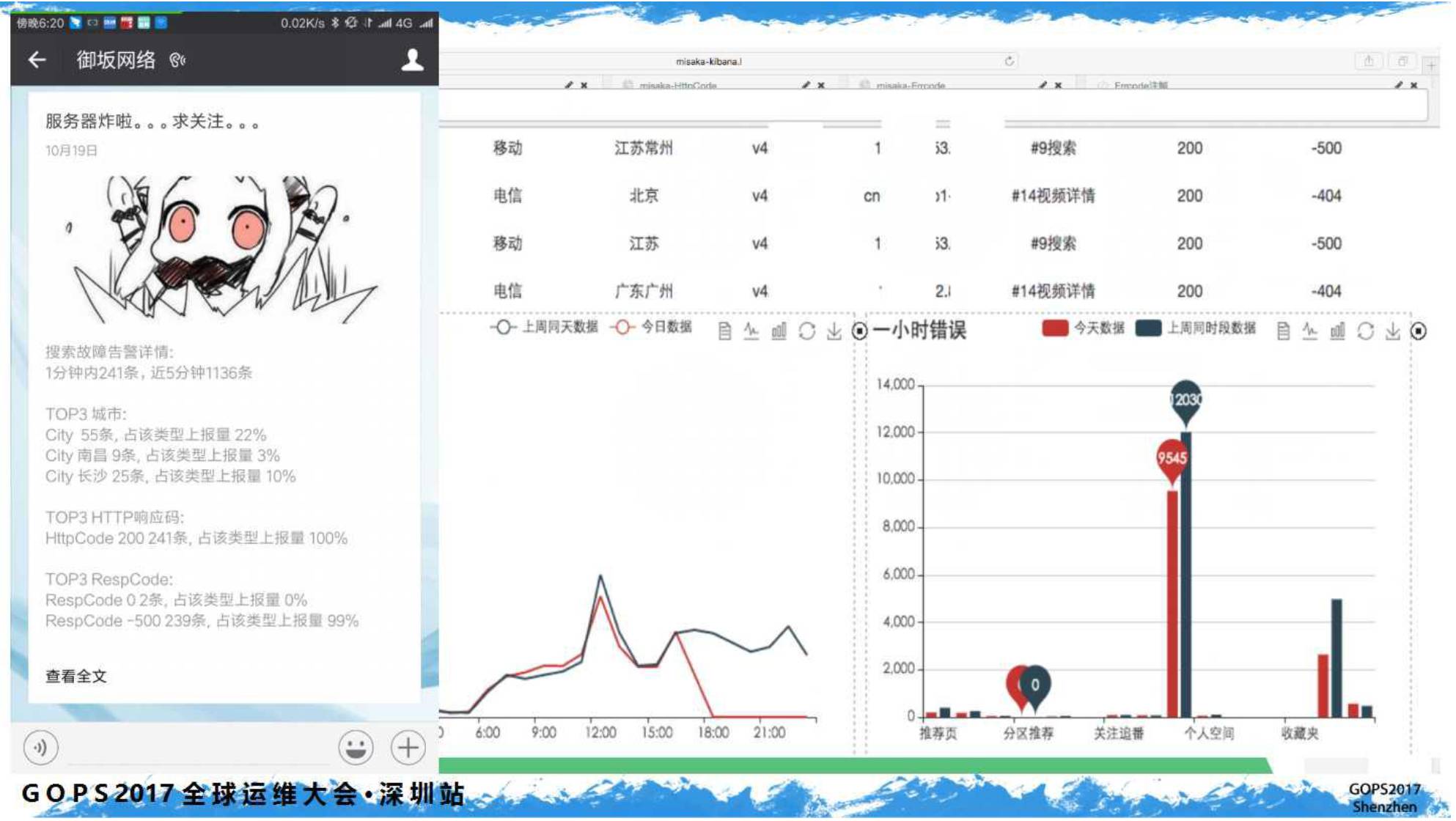
八、报警整合
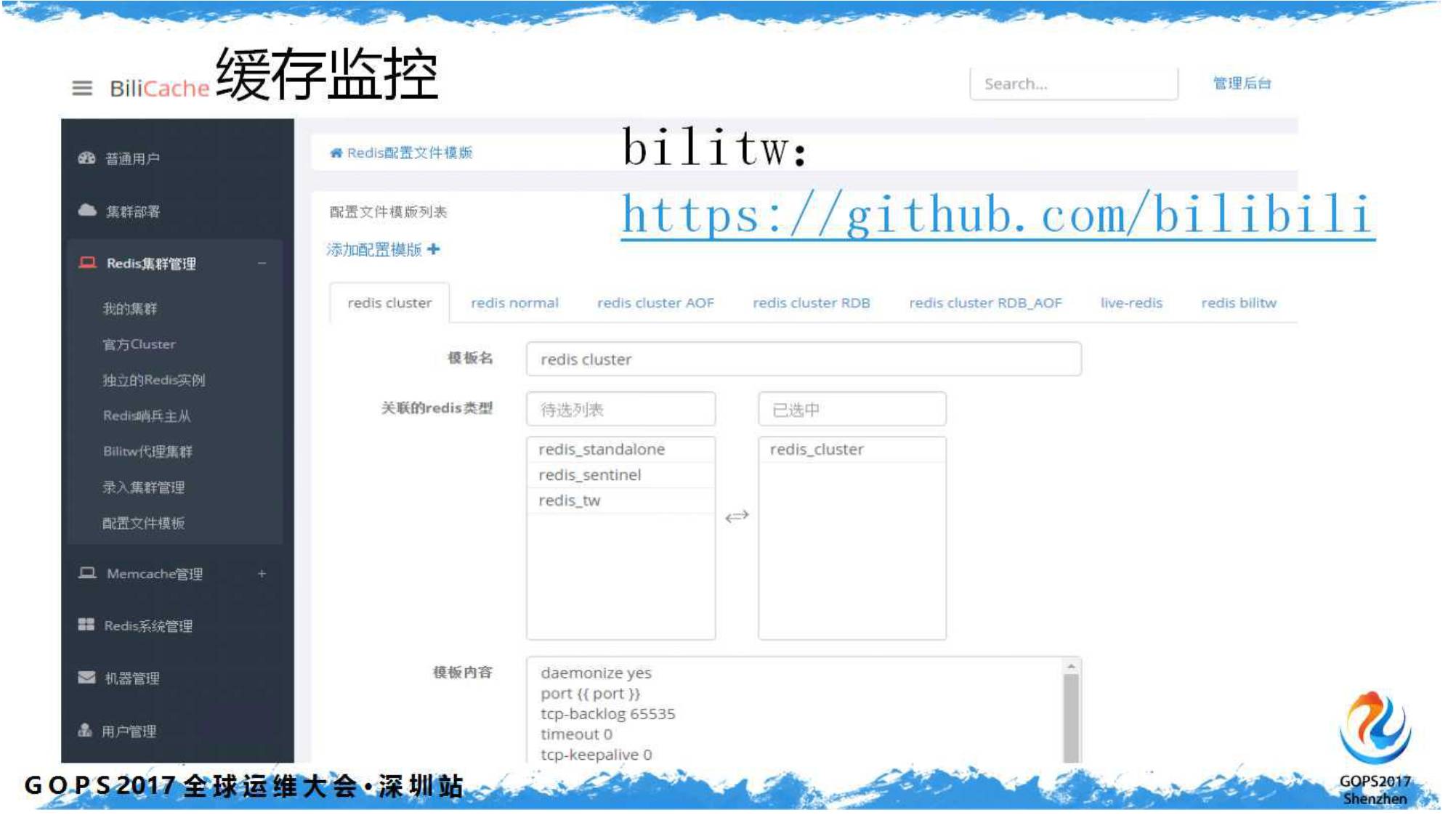
随着人员的加入和系统的逐步完善,定制化的监控和系统也越来越多。比如,支持多种集群模式的
Redis
集群监控:
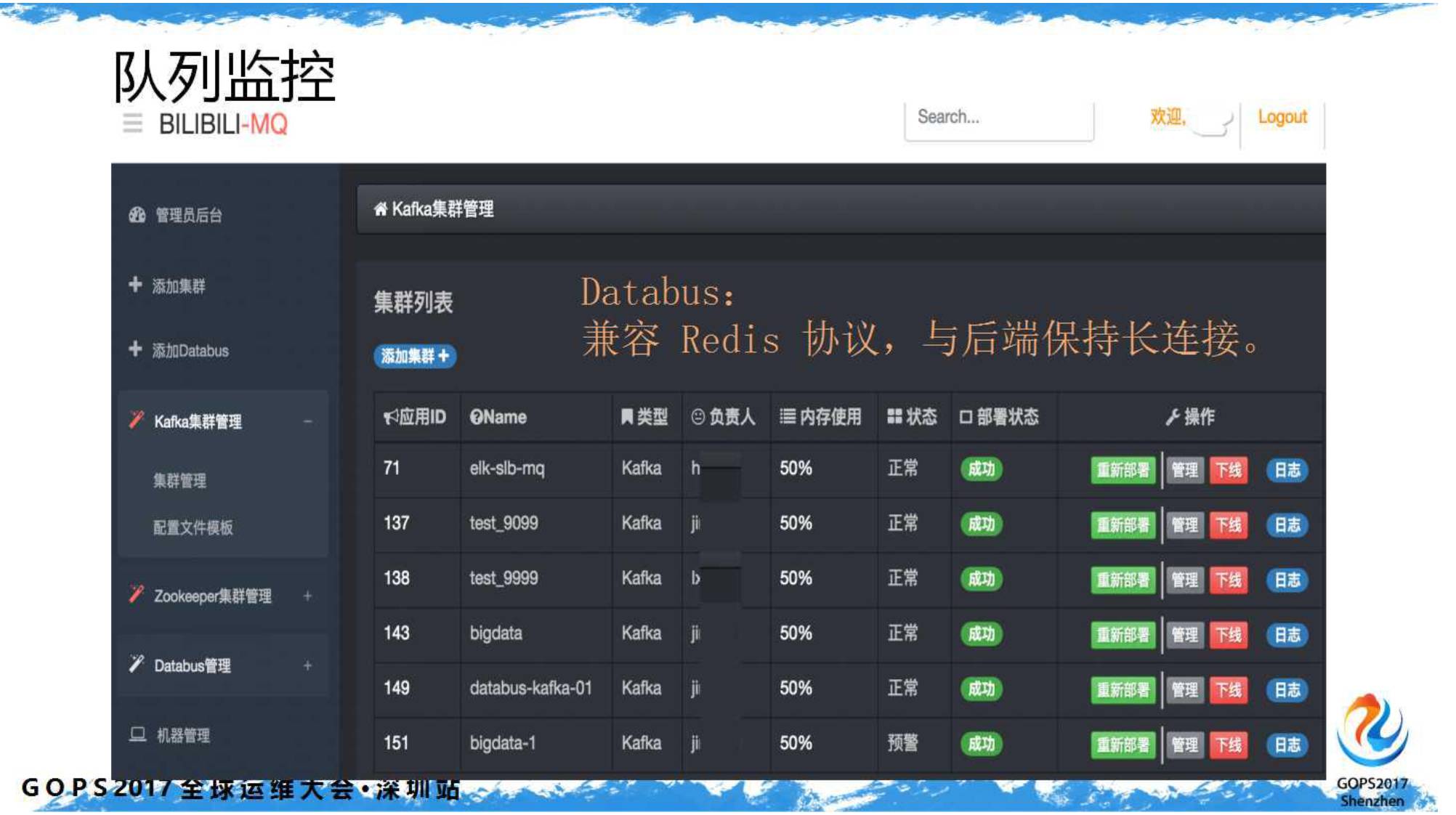
还有队列的监控,以及把
Kafka
队列包装成支持
Redis
协议的
Databus
中间件的监控。下图示例:
随即
Docker
的监控也来了,下图示例:
那么问题又来了,这么多监控,眼不花吗?会不会查问题的时候得开
N
个窗口,拼经验看谁定位问题更快……
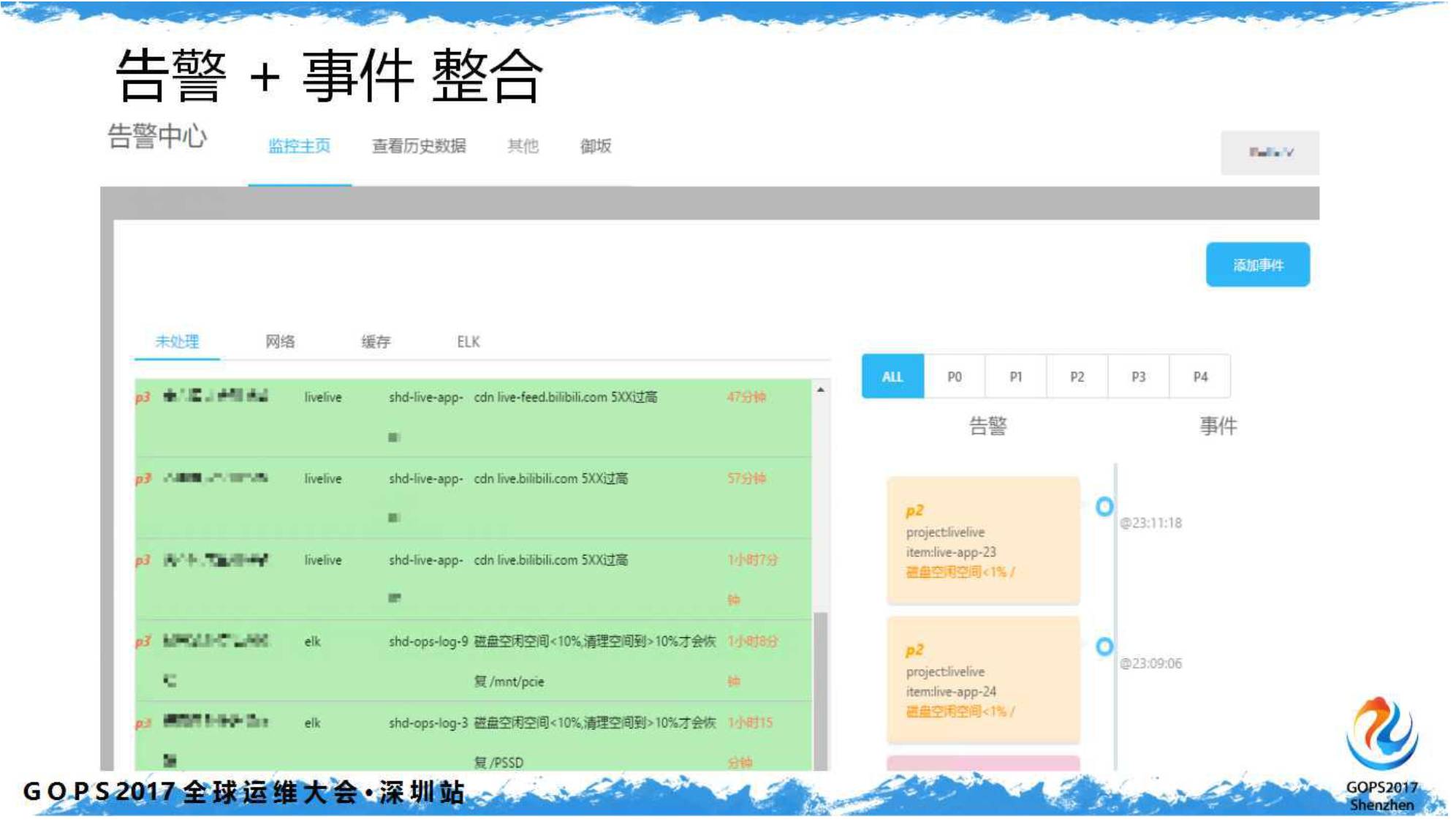
痛定思痛,我们走访了几家互联网公司。然后默默的做了一次整合,将报警和事件以时间轴的方式展现了出来。
用过都说好,下图示例:
九、在路上:
Prometheus
经历约一年时间的洗礼,我们又回到了监控系统的选型。
为什么?因为越来越多的花样监控需求,已经无法很快得到满足、而且维护工作日渐繁琐。嗯,可能不同阶段需要不同的解决方案。
那为什么是
Prometheus
?因为可选的开源产品并不多,新潮前卫的现代化监控就
OpenFlaon
和
Prometheus
啦。
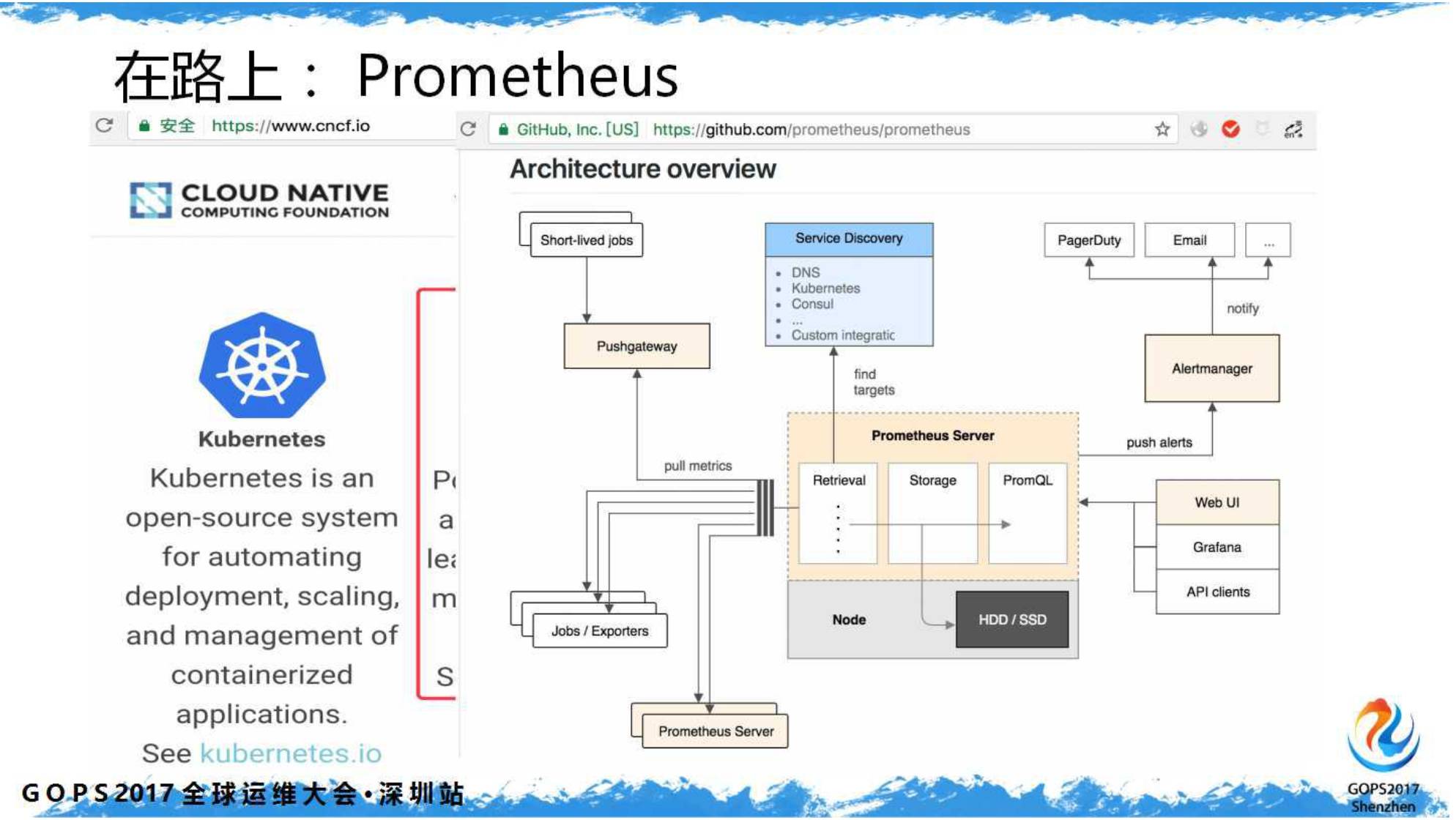
Prometheus
不止是监控工具,它是一套完整的监控解决方案。除了前端,其它都好。
很快





