
大数据文摘作品,转载要求见文末
编译 | 姚佳灵,蒋晔,杨捷
网页上的数据和信息正在呈指数级增长。如今我们都使用谷歌作为知识的首要来源——无论是寻找对某地的评论还是了解新的术语。所有这些信息都已经可以从网上轻而易举地获得。
网络中可用数据的增多为数据科学家开辟了可能性的新天地。我非常相信网页爬取是任何一个数据科学家的必备技能。
在如今的世界里,我们所需的数据都在互联网上,使用它们唯一受限的是我们对数据的获取能力。有了本文的帮助,您定会克服这个困难。
网上大多数的可用数据并不容易获取。它们以非结构化的形式(HTML格式)表示,并且不能下载。因此,这便需要知识和专业技能来使用它们。
我在本文中准备带您走一遍用R来实现网页爬取的过程。让您学会如何使用互联网上任何类型的可用数据。
用R来进行网页爬取的先决条件分为两个
:
要进行网页爬取,您必须具备R语言的操作知识。如果您正处于初识阶段或者想刷新基础知识,我强烈建议您按这个学习路径(https://www.analyticsvidhya.com/learning-paths-data-science-business-analytics-business-intelligence-big-data/learning-path-r-data-science/)学习R语言。在本文中,我们将使用R语言中由Hadley Wickham撰写的“rvest”包。您可以从下面的链接(https://cran.r-project.org/web/packages/rvest/rvest.pdf)获得rvest包的文档。请确保您安装了这个包。如果您现在还没有这个包,请按下面的代码来安装。
install.packages('rvest')
此外,如果有关于HTML和CSS的知识就更好了。我能找到的关于学习HTML和CSS的最好资源在这里(http://flukeout.github.io)。根据观察而言大多数数据科学家对于HTML和CSS不是那么精通。因此,我们会利用一个名为“Selector Gadget”的开源软件,对所有人来讲,用它来执行网页爬取是足够的。您可以从这里(http://selectorgadget.com)访问和下载Selector Gadge的扩展程序。请确保跟随该网站上的指示来安装这个扩展程序。我已经完成了这一步,现在正在使用谷歌chrome,并且可以通过chrome右上角的扩展栏上的这个图标使用它。
有了它,只需要轻轻的点击,您便可以选择网站的任何部分并获得相关标签。请注意:这是一个实际学习HTML和CSS并手动操作的方法。但是,要掌握网页爬取,我强烈建议您学习HTML和CSS以更好地理解和体味在搜索引擎背后发生的故事。
现在,让我们开始爬取IMDb网站中2016年上映的100部最受欢迎的电影。您可以点击这里http://www.imdb.com/search/title?count=100&release_date=2016,2016&title_type=feature访问网站。
#加载rvest包
library('rvest')
#定义需要爬取网站的url
url
#从网站中读取HTML代码
webpage
现在,我们将从这个网站上爬取以下数据。
Rank:电影排名(1-100),包括2016年上映的100个最受欢迎的电影。
Title:电影标题。
Description:电影描述。
Runtime:电影时长。
Genre:电影类型。
Rating:电影的IMDb评分(用户打分)。
Metascore:电影在IMDb网站上的metascore评分(评论家打分)。
Votes:电影赞成票数。
Gross_Earning_in_Mil:电影总收入,以百万为单位。
Director:电影的主要导演。注意,如果有多个导演,我只选取第一个。
Actor:电影的主要演员。注意,如果有多个演员,我只选取第一个。
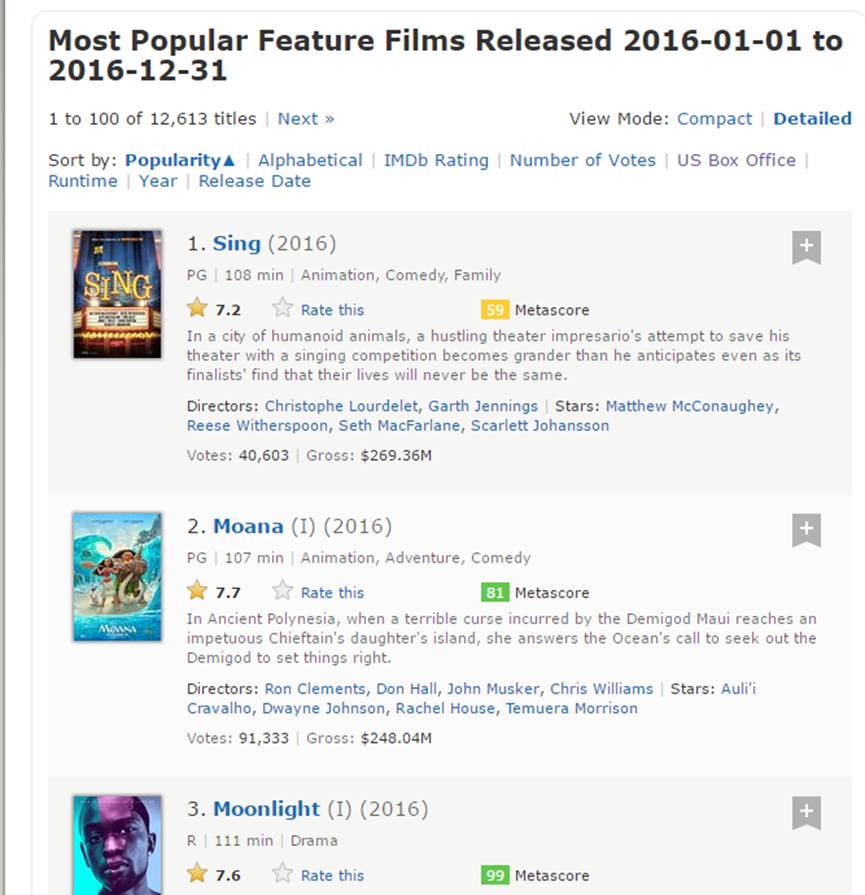
这是一个包含如何排列所有这些字段的截图。
步骤1:
现在,我们先来爬取Rank字段。为此,我们将使用Selector Gadget来获取包含排名的特定CSS选择器。您可以在浏览器中点击这个扩展程序,并用光标选择排名字段。
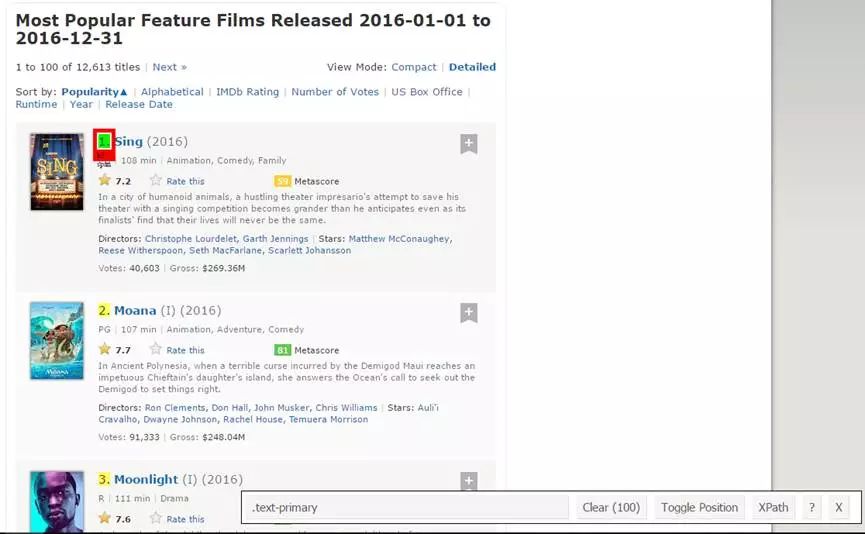
请确保所有的排名都被选中。您可以选择更多的排名部分,以防您无法获取所有这些排名,也可以通过单击所选部分以取消选择,用以确保只突出了您想要爬取的内容。
步骤2:
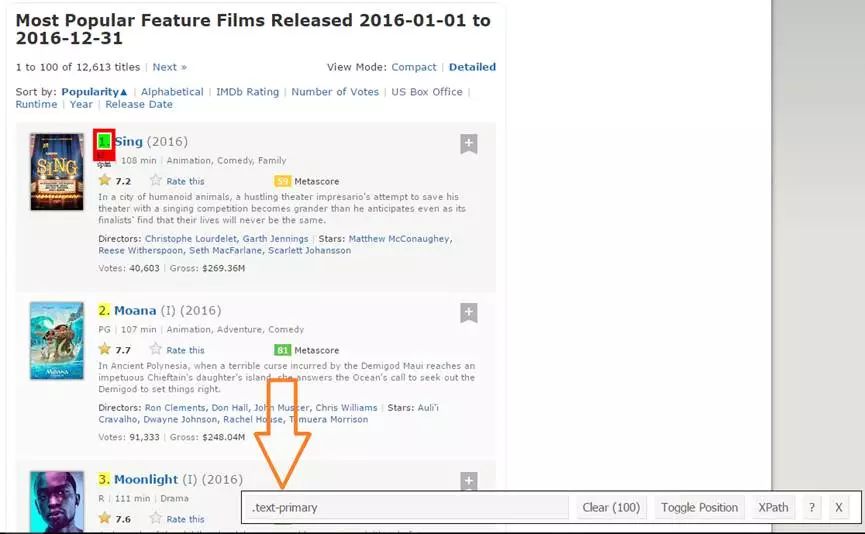
当您确定已正确选择后,您需要复制相应的CSS选择器,这可以在底部中心查看。
步骤3:
当您知道CSS选择器已包含了排名顺序之后,您可以使用这个简单的R语言代码来获取所有的排名:
#使用CSS选择器来爬取排名部分
rank_data_html
#将排名数据转化为文本
rank_data
#让我们来看看排名
head(rank_data)
[1] "1." "2." "3." "4." "5." "6."
步骤4:
当您有了数据后,请确保它看起来是您所需的格式。我在对数据进行预处理,将其转换为数字格式。
#数据预处理:将排名转换为数字格式
rank_data
#我们再来看看排名
head(rank_data)
[1] 1 2 3 4 5 6
步骤5
:
现在您可以清除选择器部分并选择所有标题。您可以直观地检查所有标题是否被选中。使用您的光标进行任何所需的添加和删除。我在这里做了同样的事情。
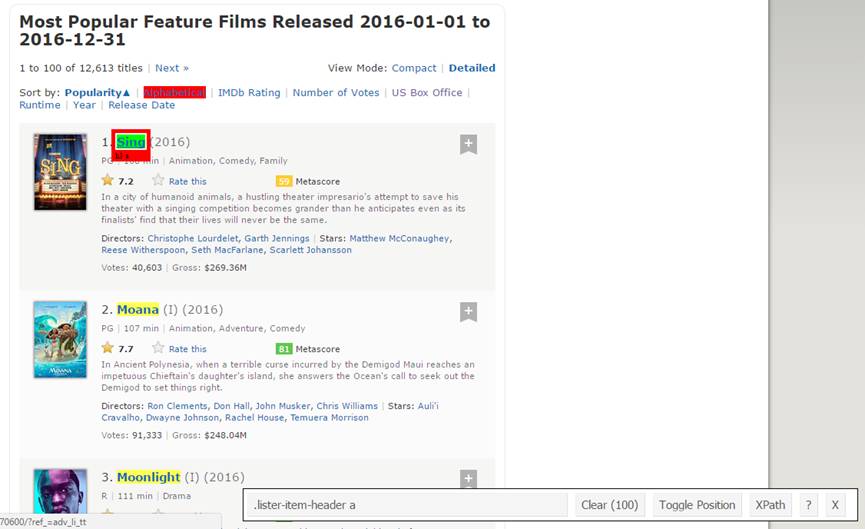
步骤6:
再一次,我有了相应标题的CSS选择器-- .lister-item-header a。我将使用该选择器和以下代码爬取所有标题。
#使用CSS选择器来爬取标题部分
title_data_html
#将标题数据转化为文本
title_data
#让我们来看看标题
head(title_data)
[1] "Sing" "Moana" "Moonlight" "Hacksaw Ridge"
[5] "Passengers" "Trolls"
步骤7:
在下面的代码中,我对Description、Runtime、Genre、Rating、Metascore、Votes、Gross_Earning_in_Mil、Director和Actor数据做了同样的操作。
#使用CSS选择器来爬取描述部分
description_data_html
#将描述数据转化为文本
description_data
#让我们来看看描述数据
head(description_data)
[1] "\nIn a city of humanoid animals, a hustling theater impresario's attempt to save his theater with a singing competition becomes grander than he anticipates even as its finalists' find that their lives will never be the same."
[2] "\nIn Ancient Polynesia, when a terrible curse incurred by the Demigod Maui reaches an impetuous Chieftain's daughter's island, she answers the Ocean's call to seek out the Demigod to set things right."
[3] "\nA chronicle of the childhood, adolescence and burgeoning adulthood of a young, African-American, gay man growing up in a rough neighborhood of Miami."
[4] "\nWWII American Army Medic Desmond T. Doss, who served during the Battle of Okinawa, refuses to kill people, and becomes the first man in American history to receive the Medal of Honor without firing a shot."
[5] "\nA spacecraft traveling to a distant colony planet and transporting thousands of people has a malfunction in its sleep chambers. As a result, two passengers are awakened 90 years early."
[6] "\nAfter the Bergens invade Troll Village, Poppy, the happiest Troll ever born, and the curmudgeonly Branch set off on a journey to rescue her friends.
#Data-Preprocessing: removing '\n'
#数据预处理:去掉'\n'
description_data
#Let's have another look at the description data
#我们再来看看描述数据
head(description_data)
[1] "In a city of humanoid animals, a hustling theater impresario's attempt to save his theater with a singing competition becomes grander than he anticipates even as its finalists' find that their lives will never be the same."
[2] "In Ancient Polynesia, when a terrible curse incurred by the Demigod Maui reaches an impetuous Chieftain's daughter's island, she answers the Ocean's call to seek out the Demigod to set things right."
[3] "A chronicle of the childhood, adolescence and burgeoning adulthood of a young, African-American, gay man growing up in a rough neighborhood of Miami."
[4] "WWII American Army Medic Desmond T. Doss, who served during the Battle of Okinawa, refuses to kill people, and becomes the first man in American history to receive the Medal of Honor without firing a shot."
[5] "A spacecraft traveling to a distant colony planet and transporting thousands of people has a malfunction in its sleep chambers. As a result, two passengers are awakened 90 years early."
[6] "After the Bergens invade Troll Village, Poppy, the happiest Troll ever born, and the curmudgeonly Branch set off on a journey to rescue her friends."
#使用CSS选择器来爬取电影时长部分
runtime_data_html
#将时长数据转化为文本
runtime_data
#让我们来看看时长
head(runtime_data)
[1] "108 min" "107 min" "111 min" "139 min" "116 min" "92 min"
#数据预处理:去掉'mins',并转换为数字格式
runtime_data
runtime_data
#我们再来看看时长数据
head(rank_data)
[1] 1 2 3 4 5 6
#使用CSS选择器来爬取电影类型部分
genre_data_html
#将类型数据转化为文本
genre_data
#让我们来看看类型
head(genre_data)
[1] "\nAnimation, Comedy, Family "
[2] "\nAnimation, Adventure, Comedy "
[3] "\nDrama "
[4] "\nBiography, Drama, History "
[5] "\nAdventure, Drama, Romance "
[6] "\nAnimation, Adventure, Comedy "
#数据预处理:去掉'\n'
genre_data
#数据预处理:去掉多余的空格
genre_data
#只选取每一部电影的第一种类型
genre_data
#将每种类型从文本转换为因子
genre_data
#我们再来看看类型数据
head(genre_data)
[1] Animation Animation Drama Biography Adventure Animation
10 Levels: Action Adventure Animation Biography Comedy Crime Drama ... Thriller
#使用CSS选择器来爬取IMDB评分部分
rating_data_html
#将评分数据转化为文本
rating_data
#让我们来看看评分
head(rating_data)
[1] "7.2" "7.7" "7.6" "8.2" "7.0" "6.5"
#数据预处理:将评分转换为数字格式
rating_data
#我们再来看看评分数据
head(rating_data)
[1] 7.2 7.7 7.6 8.2 7.0 6.5
#使用CSS选择器来爬取赞成票部分
votes_data_html
#将赞成票数据转化为文本
votes_data
#让我们来看看赞成票数据
head(votes_data)
[1] "40,603" "91,333" "112,609" "177,229" "148,467" "32,497"
#数据预处理:去掉逗号
votes_data
#数据预处理:将赞成票数据转换为数字格式
votes_data
#我们再来看看赞成票数据
head(votes_data)
[1] 40603 91333 112609 177229 148467 32497
#使用CSS选择器来爬取导演部分
directors_data_html
#将导演数据转化为文本
directors_data
#让我们来看看导演数据
head(directors_data)
[1] "Christophe Lourdelet" "Ron Clements" "Barry Jenkins"
[4] "Mel Gibson" "Morten Tyldum" "Walt Dohrn"
#数据预处理:将导演数据转换为因子
directors_data
#使用CSS选择器来爬取演员部分
actors_data_html
#将演员数据转化为文本
actors_data
#让我们来看看演员数据
head(actors_data)
[1] "Matthew McConaughey" "Auli'i Cravalho" "Mahershala Ali"
[4] "Andrew Garfield" "Jennifer Lawrence" "Anna Kendrick"
#数据预处理:将演员数据转换为因子
actors_data
但是,我想让您紧跟我看看当我对Metascore评分数据做同样的事情时会发生什么。
#使用CSS选择器来爬取metascore评分部分
metascore_data_html
#将metascore数据转化为文本
metascore_data
#让我们来看看metascore
data head(metascore_data)
[1] "59 " "81 " "99 " "71 " "41 "
[6] "56 "
#数据预处理:去掉metascore中多余的空格
metascore_data
#让我们检查一下metascore数据的长度
length(metascore_data)
[1] 96
步骤8:
我们正在爬取100部电影的数据,而metascore评分数据的长度是96。原因是因为有4部电影没有相应的Metascore字段。
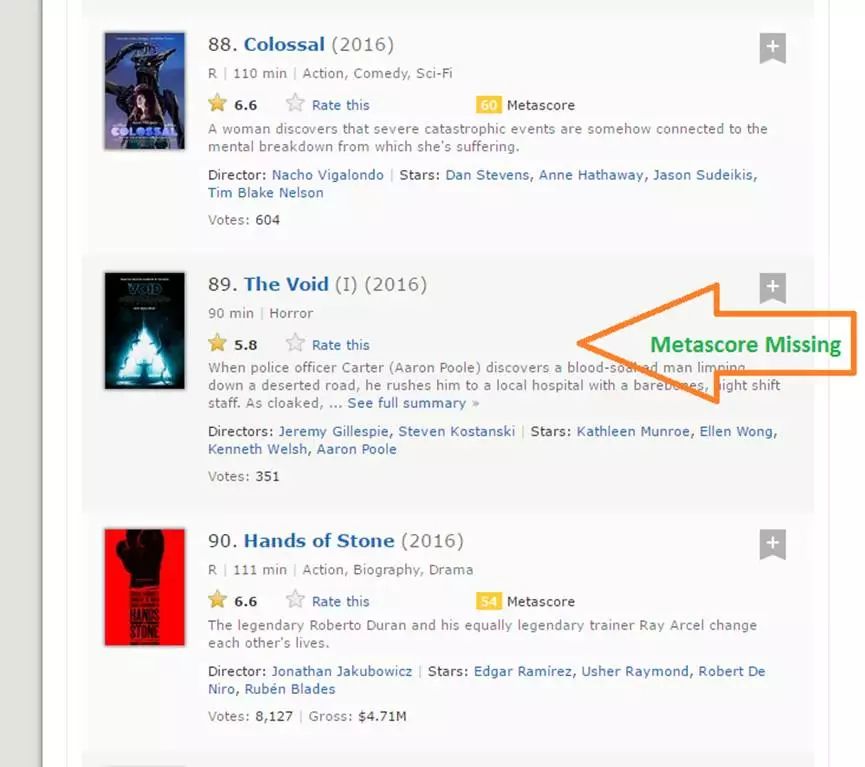
步骤9:
它是在爬取任何网站时都会发生的实际情况。不幸的是,如果我们简单地添加NA到最后4个条目,它将Metascrore数据中的NA映射到第96到100个电影,而实际上,数据丢失的是其他的一些电影。经过直观地检查,我发现缺失的是电影39、73、80和89的Metascore数据。我写了以下函数来解决这个问题。
for (i in c(39,73,80,89)){
a
b
metascore_data
metascore_data
}
#数据预处理:将metascore转换为数字格式
metascore_data
#Let's have another look at length of the metascore data
#我们再来看看metascore数据长度
length(metascore_data)
[1] 100
#让我们来看看summary statistics
summary(metascore_data)
Min. 1st Qu. Median Mean 3rd Qu. Max. NA's
23.00 47.00 60.00 60.22 74.00 99.00 4
步骤10:
同样的事情发生在Gross变量,这个数字代表这部电影的总收入。我使用相同的解决方案来解决这个问题:
#使用CSS选择器来爬取总收入部分
gross_data_html
#将总收入数据转化为文本
gross_data
#让我们来看看总收入
head(gross_data)
[1] "$269.36M" "$248.04M" "$27.50M" "$67.12M" "$99.47M" "$153.67M"
#数据预处理:去掉符号'$'和'M'
gross_data
gross_data
#我们再来看看总收入数据长度
length(gross_data)
[1] 86
#用NA填补缺失条目
for (i in c(17,39,49,52,57,64,66,73,76,77,80,87,88,89)){
a
b
gross_data
gross_data
}
#数据预处理:将总收入转换为数字格式
gross_data
#我们再来看看总收入数据长度
length(gross_data)
[1] 100
summary(gross_data)
Min. 1st Qu. Median Mean 3rd Qu. Max. NA's
0.08 15.52 54.69 96.91 119.50 530.70 14
步骤11:
现在我们已经成功地爬取了2016年上映的100部最受欢迎的电影的所有11个特征。让我们合并它们到一个数据框并检查它的结构。
#合并所有列表构造一个数据框
movies_df
Description = description_data, Runtime = runtime_data,
Genre = genre_data, Rating = rating_data,
Metascore = metascore_data, Votes = votes_data, Gross_Earning_in_Mil = gross_data,
Director = directors_data, Actor = actors_data)
#数据框的结构
str(movies_df)
'data.frame': 100 obs. of 11 variables:
$ Rank : num 1 2 3 4 5 6 7 8 9 10 ...
$ Title : Factor w/ 99 levels "10 Cloverfield Lane",..: 66 53 54 32 58 93 8 43 97 7 ...
$ Description : Factor w/ 100 levels "19-year-old Billy Lynn is brought home for a victory tour after a harrowing Iraq battle. Through flashbacks the film shows what"| __truncated__,..: 57 59 3 100 21 33 90 14 13 97 ...
$ Runtime : num 108 107 111 139 116 92 115 128 111 116 ...
$ Genre : Factor w/ 10 levels "Action","Adventure",..: 3 3 7 4 2 3 1 5 5 7 ...
$ Rating : num 7.2 7.7 7.6 8.2 7 6.5 6.1 8.4 6.3 8 ...
$ Metascore : num 59 81 99 71 41 56 36 93 39 81 ...
$ Votes : num 40603 91333 112609 177229 148467 ...
$ Gross_Earning_in_Mil: num 269.3 248 27.5 67.1 99.5 ...
$ Director : Factor w/ 98 levels "Andrew Stanton",..: 17 80 9 64 67 95 56 19 49 28 ...
$ Actor : Factor w/ 86 levels "Aaron Eckhart",..: 59 7 56 5 42 6 64 71 86 3 ...
您现在已经成功地在IMDb网站上爬取了2016年上映的最受欢迎的100部电影数据。










