前言

因为工作方向相关,之前我也尝试着在
Google
、
arXiv
、
wikipedia
等等地方搜一些风控识别的资料或者思路,但是事与愿违的是,绝大多数的与风控算法都毫无关系,基本上都是推销自己家的产品的,所以,我之前也尝试着写了一些方法的梳理,如
:
·
多算法识别撞库刷券等异常用户
·
异常值识别与处理
但是在我前几天再回过头去看自己写的这些东西的时候,作为一个老司机来说,我都不想去看一篇又一篇动则上千字的文章,理论交错,文笔粗陋,正巧现在公司内部也有一个风控的项目,所以,我准备做一个开源的项目
fast_risk_control
,核心在于:
·
简单操作,几乎不用多少调参,自动识别异常点
·
理论清晰,支持的方法多,兼容性好
·
集成数据预处理的过程,减轻前置工作量
“
纠结
”
了几个朋友的情况下,一期已经完工,主要是搭建了最简单的框架,我相信,这只是一个开始,欢迎大家试用,也欢迎每一个人来批评,更希望有想法的同学一起来做这个事情。
接下来,让我们来讲讲,一期我们做了什么?
核心我们一期做的异常点识别中,核心是利用的
14
年周志华教授提出的
isolation forest
算法进行识别,详细的理论部分请参见:
Isolation Forest
,重复说一个事情的意义也不大。这边需要解释几点:
·
具体是怎么得到当前的算法流程的呢?
·
为了用当前的算法进行识别而不用其他的识别算法?
·
当前的设计下存在哪些问题?
·
未来的方向会在哪边?
让我们来一一来回答这些问题。
为了用Isolation Forest而不用其他的识别算法?
在设计这套算法之前,我们其实是越到了一个实际的业务问题,
黑产撞库
。相信大家毫不陌生这个词,无论是阿里、京东、滴滴还是腾讯,被撞库是一件普通了不能再普通的事情,
“
黑产
”
的人从第三方渠道,获取到你历史上的手机号和一些你曾经用的密码,重复的登陆,暴力的尝试,如果你的密码设置的比较简单,比如:
“123456”
,
“qwerty”...
非常容易被破解,然后再根据你历史下单的情况,进行假冒
“
客服
”
退款,进行诈骗,百度一搜就有一堆这样的新闻:
·
频发假冒电商客服
·
当心
!
近期有人冒充假客服行骗 几分钟骗走市民八九万元
·
...
所以,我们需要阻止
“
黑产
”
人员进行这样的暴力破解,获取用户的资料,由此而引发了我们对这个问题的思考。我们在对这个问题分析的时候,巧妙的发现了如下的一些信息:

因为涉及公司机密,这边隐去了具体坐标和值,很容易发现以下问题:
·
正常扇面内数据分布密集,未知扇面内数据分布松散,异常扇面内数据分布稀疏
·
正常扇面内的数据量占全量数据的绝大多数
·
不存在明显的分割线,正常扇面和异常扇面存在过度地带
这个给了我们一些启发,我们做了如下的分析:
·
我们观察了异常扇面内的用户黑白比,如我们预计的黑白比为
20:3
,也就是说分布远离大量数据点的用户绝大多数存在问题
·
为止区域的用户黑白比为
1:2
,这说明在黑白用户之间不存在明显的界限,有交错地带
·
正常区域内也存在黑名单用户,比例在
504:1
,也就是说,我们划分有一定识别能力,但是还是不能做到全量识别
综合上述这些预先的处理,我们要用算法完成三件事情:
1.
切分全量用户,做到识别出
正常,未知,异常用户
2.
识别出异常用户和正常用户之间的
差异约束切割
3.
在异常用户
+
未知用户里面,找出利用差异约束切割出黑名单
为了用当前的算法进行识别而不用其他的识别算法?
切分数据的时候,我们这边采用的是切比雪夫条件。非理工科的同学可能比较疑惑什么事切比雪夫条件,这边如果数据是正态下,箱式图的
Q3+3/2
QI
上
top
点切割大家就应该很熟悉了,其实利用的就是数据出现的概率。
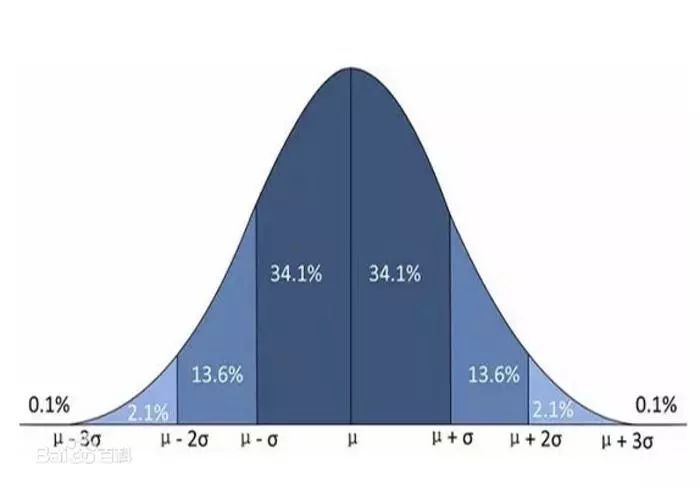
来源于百度百科
上面这张图很好的解释了,在数据服从正态分布的情况下,出现数据值比均值
+3
标准差要大的概率不足
0.1%,所以,我们可以认为这些数据是异常点了。那现在出现了一个问题,日常数据分布都不一定是正态的,所以引出来了类似的切比雪夫理论,它用的是马氏距离距离中心点的程度,详细的马氏距离理论见
马氏距离分布
。
切分完成数据之后,我们要做寻找差异约束切割逻辑。从最上面的扇面图,我们很容易发现,正常数据与异常数据之间的密度差异很明显,所以如何识别密度差异的算法就是我们需要的,这边我大概找了
6
、
7
种常见的切分方法,这边主要讲三种:
isolation forest
,
lof
,
distance similarity
。理论我之前也讲过,贴上地址,不废话了:
密度算法
。这边主要展示效果差异:









