300 + 明星创业公司,3000 + 行业人士齐聚全球人工智能与机器人峰会 GAIR 2017,一 同见证 AI 浪潮之巅!峰会抢票火热进行中。
今天特放出 5 个直减 1200 元的无条件优惠码(见文末,优惠幅度逐天减小),感谢各位读者对雷锋网的支持,用浏览器打开链接即可使用。
AI 科技评论按:原作者彭伟,原文载于知乎专栏。本文转载自「AI研习社」,搜索「okweiwu」即可关注。
本文要介绍的这一篇 paper 是 ICML2016 上一篇关于 CNN 在图(graph)上的应用。ICML 是机器学习方面的顶级会议,这篇文章 --<>-- 所研究的内容也具有非常好的理论和实用的价值。如果您对于图的数据结构并不是很熟悉建议您先参考本文末的相关基础知识的介绍。
CNN 已经在计算机视觉(CV)以及自然语言处理等领域取得了 state-of-art 的水平,其中的数据可以被称作是一种 Euclidean Data,CNN 正好能够高效的处理这种数据结构,探索出其中所存在的特征表示。
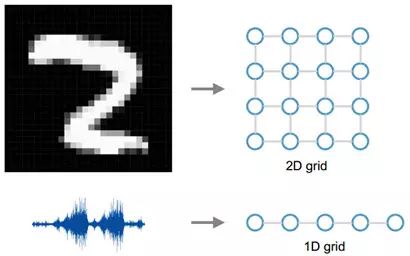
图 1 欧氏(欧几里德)数据(Euclidean Data)举例
所谓的欧氏(欧几里德)数据指的是类似于 grids, sequences… 这样的数据,例如图像就可以看作是 2D 的 grid 数据,语音信号就可以看作是 1D 的 grid 数据。但是现实的处理问题当中还存在大量的 Non-Euclidean Data,如社交多媒体网络(Social Network)数据,化学成分(Chemical Compound)结构数据,生物基因蛋白(Protein)数据以及知识图谱(Knowledge Graphs)数据等等,这类的数据属于图结构的数据(Graph-structured Data)。CNN 等神经网络结构则并不能有效的处理这样的数据。因此,这篇 paper 要解决的问题就是如何使用 CNN 高效的处理图结构的数据。
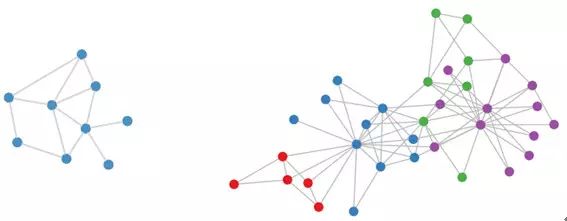
图 2 Graph 数据举例
本文所提出算法思想很简单,将一个图结构的数据转化为 CNN 能够高效处理的结构。处理的过程主要分为两个步骤:
1. 从图结构当中选出具有代表性的 nodes 序列;
2. 对于选出的每一个 node 求出一个卷积的邻域(neighborhood field)。接下来我们详细的介绍算法相关的细节。
本 paper 将图像(image)看作是一种特殊的图(graph),即一种的 grid graph,每一个像素就是 graph 当中的一个 node。那么我猜想文章的 motivation 主要来自于想将 CNN 在图像上的应用 generalize 到一般的 graph 上面。
那么我们首先来看一下 CNN 在 Image 当中的应用。如图 3 所示,左图表示的是一张图像在一个神经网络层当中的卷机操作过程。最底部的那一层是输入的特征图(或原图),通过一个卷积(这里表示的是一个 3*3 的卷积核,也就是文章当中的 receptive filed=9)操作,输出一张卷积后的特征图。如图 3 的卷积操作,底层的 9 个像素被加权映射到上层的一个像素;再看图 3 中的右图,表示从 graph 的角度来看左图底层的输入数据。其中任意一个带卷积的区域都可以看作是一个中心点的 node 以及它的领域的 nodes 集合,最终加权映射为一个值。因此,底部的输入特征图可以看作是:在一个方形的 grid 图当中确定一些列的 nodes 来表示这个图像并且构建一个正则化的邻域图(而这个邻域图就是卷积核的区域,也就是感知野)。
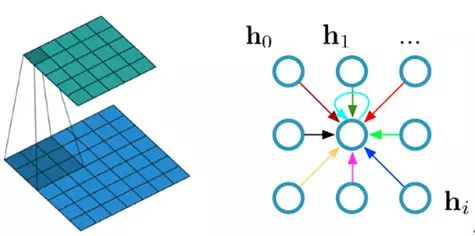
图 3 图像的卷积操作
按照这样的方式来解释,那么如 paper 中 Figure1 所示,一张 4*4 大小的图像,实际上可以表示为一个具有 4 个 nodes(图中的 1,2,3,4)的图(graph),其中每一个 node 还包括一个和卷积核一样大小的邻域(neighborhood filed)。那么,由此得到对于这种图像(image)的卷积实际上就是对于这 4 个 node 组成的图(graph)的领域的卷积。那么,对于一个一般性的 graph 数据,同样的只需要选出其中的 nodes,并且求解得到其相关的固定大小(和卷积核一样大小)领域便可以使用 CNN 卷积得到图的特征表示。
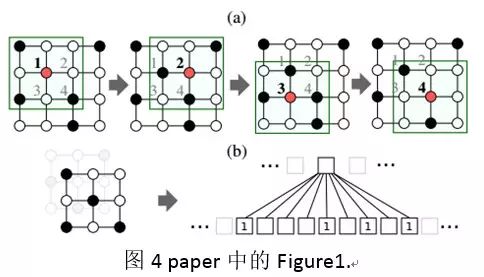
图 4 paper 中的 Figure1
需要注意的是,图 4(b)当中表示的是(a)当中的一个 node 的邻域,这个感知野按照空间位置从左到右,从上到下的顺序映射为一个和卷积核一样大小的 vector,然后再进行卷积。但是在一般的图集当中,不存在图像当中空间位置信息。这也是处理图数据过程当中要解决的一个问题。
基于以上的描述 paper 当中主要做了三个事情:1. 选出合适的 nodes;2. 为每一个 node 建立一个邻域;3. 建立 graph 表示到 vector 表示的单一映射,保证具有相似的结构特征的 node 可以被映射到 vector 当中相近的位置。算法具体分为 4 个步骤:
1. 图当中顶点的选择 Node Sequence Selection
首先对于输入的一个 Graph,需要确定一个宽度 w(定义于 Algorithm 1),它表示也就是要选择的 nodes 的个数。其实也就是感知野的个数(其实这里也就是表明,每次卷积一个 node 的感知野,卷积的 stride= kernel size 的)。那么具体如何进行 nodes 的选择勒?
实际上,paper 当中说根据 graph 当中的 node 的排序 label 进行选择,但是本文并没有对如何排序有更多的介绍。主要采取的方法是:centrality,也就是中心化的方法,个人的理解为越处于中心位置的点越重要。这里的中心位置不是空间上的概念,应该是度量一个点的关系中的重要性的概念,简单的举例说明。如图 5 当中的两个图实际上表示的是同一个图,对其中红色标明的两个不同的 nodes 我们来比较他们的中心位置关系。比较的过程当中,我们计算该 node 和其余所有 nodes 的距离关系。我们假设相邻的两个 node 之间的距离都是 1。
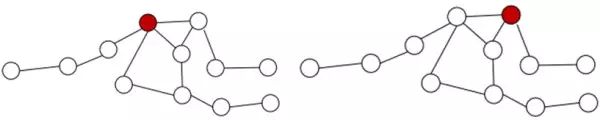
图 5 图当中的两个 nodes
那么对于图 5 当中的左图的红色 node,和它直接相连的 node 有 4 个,因此距离 + 4;再稍微远一点的也就是和它相邻点相邻的有 3 个,距离 + 6; 依次再相邻的有 3 个 + 9;最后还剩下一个最远的 + 4;因此我们知道该 node 的总的距离为 23。同理我们得到右边的 node 的距离为 3+8+6+8=25。那么很明显 node 的选择的时候左边的 node 会被先选出来。
当然,这只是一种 node 的排序和选择的方法,其存在的问题也是非常明显的。Paper 并没有在这次的工作当中做详细的说明。
2. 找到 Node 的领域 Neighborhood Assembly
接下来对选出来的每一个 node 确定一个感知野 receptive filed 以便进行卷积操作。但是,在这之前,首先找到每一个 node 的邻域区域(neighborhood filed),然后再从当中确定感知野当中的 nodes。假设感知野的大小为 k,那么对于每一个 Node 很明显都会存在两种情况:邻域 nodes 不够 k 个,或者是邻域点多了。这个将在下面的章节进行讲解。
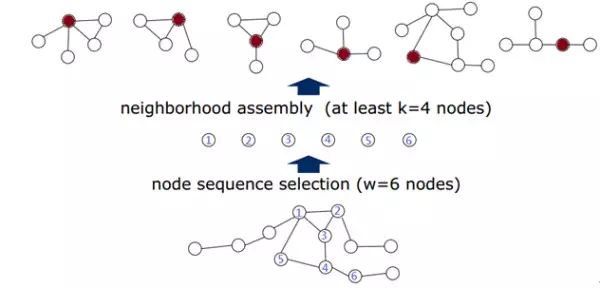
图 6 Neighborhood Assemble 结果
如图选出的是 6 个 nodes,对于每一个 node,首先找到其直接相邻的 nodes(被称作是 1-neighborhood),如果还不够再增加间接相邻的 nodes。那么对于 1-neighborhood 就已经足够的情况,先全部放在候选的区域当中,在下一步当中通过规范化来做最终的选择。
3. 图规范化过程 Graph Normalization
假设上一步 Neighborhood Assemble 过程当中一个 node 得到一个领域 nodes 总共有 N 个。那么 N 的个数可能和 k 不相等的。因此,normalize 的过程就是要对他们打上排序标签进行选择,并且按照该顺序映射到向量当中。

图 7 求解 node 的 receptive filed
如果这个 node 的邻域 nodes 的个数不足的话,直接全部选上,不够补上哑节点(dummy nodes),但还是需要排序;如果数目 N 超过则需要按着排序截断后面的节点。如图 7 所示表示从选 node 到求解出 receptive filed 的整个过程。Normalize 进行排序之后就能够映射到一个 vector 当中了。因此,这一步最重要的是对 nodes 进行排序。
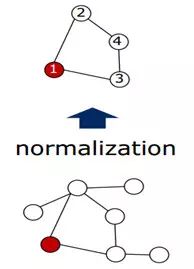
图 8 Normalize 过程
如图 8 所示,表示对任意一个 node 求解它的 receptive filed 的过程。这里的卷积核的大小为 4,因此最终要选出来 4 个 node,包括这个 node 本身。因此,需要给这些 nodes 打上标签(labeling)。当然存在很多的方式,那么怎样的打标签方式才是最好的呢?如图 7 所示,其实从这 7 个 nodes 当中选出 4 个 nodes 会形成一个含有 4 个 nodes 的 graph 的集合。作者认为:在某种标签下,随机从集合当中选择两个图,计算他们在 vector 空间的图的距离和在 graph 空间图的距离的差异的期望,如果这个期望越小那么就表明这个标签越好!具体的表示如下:
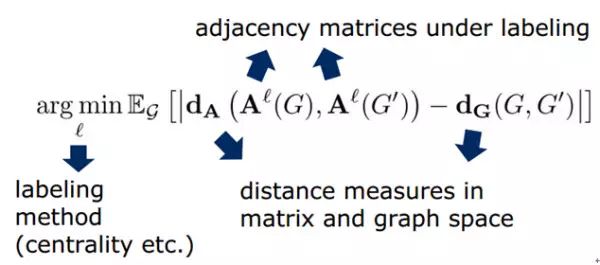
得到最好的标签之后,就能够按着顺序将 node 映射到一个有序的 vector 当中,也就得到了这个 node 的 receptive field,如图 6 最右边所示。
4. 卷积网络结构 Convolutional Architecture
文章使用的是一个 2 层的卷积神经网络,将输入转化为一个向量 vector 之后便可以用来进行卷积操作了。具体的操作如图 9 所示。

图 9 卷积操作过程
首先最底层的灰色块为网络的输入,每一个块表示的是一个 node 的感知野(receptive field)区域,也是前面求解得到的 4 个 nodes。其中 an 表示的是每一个 node 的数据中的一个维度(node 如果是彩色图像那就是 3 维;如果是文字,可能是一个词向量…… 这里表明数据的维度为 n)。粉色的表示卷积核,核的大小为 4,但是宽度要和数据维度一样。因此,和每一个 node 卷季后得到一个值。卷积的步长(stride)为 4,表明每一次卷积 1 个 node,stride=4 下一次刚好跨到下一个 node。(备注:paper 中 Figure1 当中,(a)当中的 stride=1,但是转化为(b)当中的结构后 stride=9)。卷积核的个数为 M,表明卷积后得到的特征图的通道数为 M,因此最终得到的结果为 V1……VM,也就是图的特征表示。有了它便可以进行分类或者是回归的任务了。
基础问题:
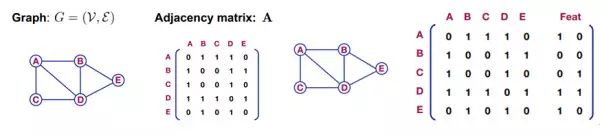
图的基本概念:主要有顶点和边构成,存在一个邻接矩阵 A,如果对其中的 nodes 进行特征表示(Feat)的话如下右图。
CCF-GAIR 2017,100 + 优质展位,1000 + 传统供应链玩家,全球顶级技术方案商悉数亮相,帮企业实现 AI 技术方案快速对接,掘金万亿 AI 产业!高端资源、优质展位、名额有限,再不申请就没了!电话或微信联系方式:15013779392
https://gair.leiphone.com/gair/coupon/s/593bfb24b34b9
https://gair.leiphone.com/gair/coupon/s/593bfb24b32a6
https://gair.leiphone.com/gair/coupon/s/593bfb24b3091
https://gair.leiphone.com/gair/coupon/s/593bfb24b2e76
https://gair.leiphone.com/gair/coupon/s/593bfb24b2bf4
优惠券仅限「参会门票」每张只能使用一次。赠送的优惠劵额度每天递减 50 元,有效期为 1 天。长按复制链接,在浏览器打开立即使用。大会介绍点文末阅读原文
AI科技评论招业界记者啦!
在这里,你可以密切关注海外会议的大牛演讲;可以采访国内巨头实验室的技术专家;对人工智能的动态了如指掌;更能深入剖析AI前沿的技术与未来!
如果你:
*对人工智能有一定的兴趣或了解
* 求知欲强,具备强大的学习能力
* 有AI业界报道或者媒体经验优先
简历投递:
[email protected]









