
作者:才云科技Caicloud,郑泽宇,顾思宇
要将深度学习应用到实际问题中,一个非常大的问题在于训练深度学习模型需要的计算量太大。比如Inception-v3模型在单机上训练到78%的正确率需要将近半年的时间 ,这样的训练速度是完全无法应用到实际生产中的。为了加速训练过程,本章将介绍如何通过TensorFlow利用GPU或/和分布式计算进行模型训练。本文节选自《TensorFlow:实战Google深度学习框架》第十章。
本文将介绍如何在TensorFlow中使用单个GPU进行计算加速,也将介绍生成TensorFlow会话(tf.Session)时的一些常用参数。通过这些参数可以使调试更加方便而且程序的可扩展性更好。然而,在很多情况下,单个GPU的加速效率无法满足训练大型深度学习模型的计算量需求,这时将需要利用更多的计算资源。为了同时利用多个GPU或者多台机器,10.2节中将介绍训练深度学习模型的并行方式。然后,10.3节将介绍如何在一台机器的多个GPU上并行化地训练深度学习模型。在这一节中也将给出具体的TensorFlow样例程序来使用多GPU训练模型,并比较并行化效率提升的比率。最后在10.4节中将介绍分布式TensorFlow,以及如何通过分布式TensorFlow训练深度学习模型。在这一节中将给出具体的TensorFlow样例程序来实现不同的分布式深度学习训练模式。虽然TensorFlow可以支持分布式深度学习模型训练,但是它并不提供集群创建、管理等功能。为了更方便地使用分布式TensorFlow,10.4节中将介绍才云科技基于Kubernetes容器云平台搭建的分布式TensorFlow系统。
TensorFlow程序可以通过tf.device函数来指定运行每一个操作的设备,这个设备可以是本地的CPU或者GPU,也可以是某一台远程的服务器。但在本节中只关心本地的设备。TensorFlow会给每一个可用的设备一个名称,tf.device函数可以通过设备的名称来指定执行运算的设备。比如CPU在TensorFlow中的名称为/cpu:0。在默认情况下,即使机器有多个CPU,TensorFlow也不会区分它们,所有的CPU都使用/cpu:0作为名称。而一台机器上不同GPU的名称是不同的,第n个GPU在TensorFlow中的名称为/gpu:n。比如第一个GPU的名称为/gpu:0,第二个GPU名称为/gpu:1,以此类推。
TensorFlow提供了一个快捷的方式来查看运行每一个运算的设备。在生成会话时,可以通过设置log_device_placement参数来打印运行每一个运算的设备。下面的程序展示了如何使用log_device_placement这个参数。
'a'
在以上代码中,TensorFlow程序生成会话时加入了参数log_device_placement=True,所以程序会将运行每一个操作的设备输出到屏幕。于是除了可以看到最后的计算结果之外,还可以看到类似“add: /job:localhost/replica:0/task:0/cpu:0”这样的输出。这些输出显示了执行每一个运算的设备。比如加法操作add是通过CPU来运行的,因为它的设备名称中包含了/cpu:0。
在配置好GPU环境的TensorFlow中 ,如果操作没有明确地指定运行设备,那么TensorFlow会优先选择GPU。比如将以上代码在亚马逊(Amazon Web Services, AWS)的 g2.8xlarge实例上运行时,会得到以下运行结果。
name
从上面的输出可以看到在配置好GPU环境的TensorFlow中,TensorFlow会自动优先将运算放置在GPU上。不过,尽管g2.8xlarge实例有4个GPU,在默认情况下,TensorFlow只会将运算优先放到/gpu:0上。于是可以看见在上面的程序中,所有的运算都被放在了/gpu:0上。如果需要将某些运算放到不同的GPU或者CPU上,就需要通过tf.device来手工指定。下面的程序给出了一个通过tf.device手工指定运行设备的样例。
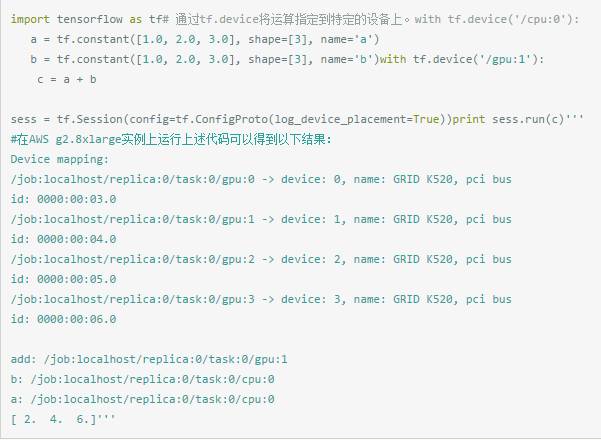
在以上代码中可以看到生成常量a和b的操作被加载到了CPU上,而加法操作被放到了第二个GPU“/gpu:1”上。在TensorFlow中,不是所有的操作都可以被放在GPU上,如果强行将无法放在GPU上的操作指定到GPU上,那么程序将会报错。以下代码给出了一个报错的样例。
_cpu = tf.Variable(0, name="a_
不同版本的TensorFlow对GPU的支持不一样,如果程序中全部使用强制指定设备的方式会降低程序的可移植性。在TensorFlow的kernel 中定义了哪些操作可以跑在GPU上。比如可以在variable_ops.cc程序中找到以下定义。
REGISTER_GPU_KERNELS(type)
在这段定义中可以看到GPU只在部分数据类型上支持tf.Variable操作。如果在TensorFlow代码库中搜索调用这段代码的宏TF_CALL_GPU_NUMBER_TYPES,可以发现在GPU上,tf.Variable操作只支持实数型(float16、float32和double)的参数。而在报错的样例代码中给定的参数是整数型的,所以不支持在GPU上运行。为避免这个问题,TensorFlow在生成会话时可以指定allow_soft_placement参数。当allow_soft_placement参数设置为True时,如果运算无法由GPU执行,那么TensorFlow会自动将它放到CPU上执行。以下代码给出了一个使用allow_soft_placement参数的样例。

虽然GPU可以加速TensorFlow的计算,但一般来说不会把所有的操作全部放在GPU上。一个比较好的实践是将计算密集型的运算放在GPU上,而把其他操作放到CPU上。GPU是机器中相对独立的资源,将计算放入或者转出GPU都需要额外的时间。而且GPU需要将计算时用到的数据从内存复制到GPU设备上,这也需要额外的时间。TensorFlow可以自动完成这些操作而不需要用户特别处理,但为了提高程序运行的速度,用户也需要尽量将相关的运算放在同一个设备上。
TensorFlow可以很容易地利用单个GPU加速深度学习模型的训练过程,但要利用更多的GPU或者机器,需要了解如何并行化地训练深度学习模型。常用的并行化深度学习模型训练方式有两种,同步模式和异步模式。本节中将介绍这两种模式的工作方式及其优劣。
为帮助读者理解这两种训练模式,本节首先简单回顾一下如何训练深度学习模型。图10-1展示了深度学习模型的训练流程图。深度学习模型的训练是一个迭代的过程。在每一轮迭代中,前向传播算法会根据当前参数的取值计算出在一小部分训练数据上的预测值,然后反向传播算法再根据损失函数计算参数的梯度并更新参数。在并行化地训练深度学习模型时,不同设备(GPU或CPU)可以在不同训练数据上运行这个迭代的过程,而不同并行模式的区别在于不同的参数更新方式。
图10-2展示了异步模式的训练流程图。从图10-2中可以看到,在每一轮迭代时,不同设备会读取参数最新的取值,但因为不同设备读取参数取值的时间不一样,所以得到的值也有可能不一样。根据当前参数的取值和随机获取的一小部分训练数据,不同设备各自运行反向传播的过程并独立地更新参数。可以简单地认为异步模式就是单机模式复制了多份,每一份使用不同的训练数据进行训练。在异步模式下,不同设备之间是完全独立的。
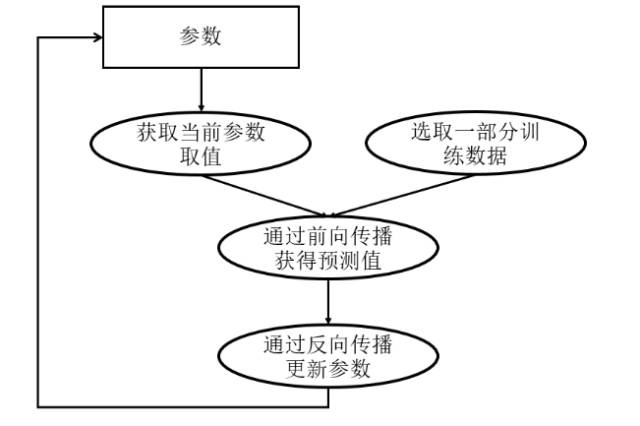
深度学习模型训练流程图
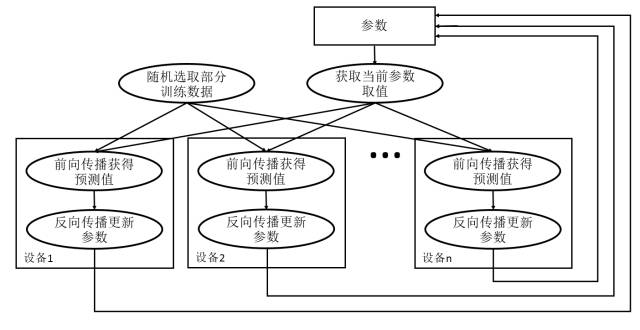
异步模式深度学习模型训练流程图
然而使用异步模式训练的深度学习模型有可能无法达到较优的训练结果。图10-3中给出了一个具体的样例来说明异步模式的问题。其中黑色曲线展示了模型的损失函数,黑色小球表示了在t0时刻参数所对应的损失函数的大小。假设两个设备d0和d1在时间t0同时读取了参数的取值,那么设备d0和d1计算出来的梯度都会将小黑球向左移动。假设在时间t1设备d0已经完成了反向传播的计算并更新了参数,修改后的参数处于图10-3中小灰球的位置。然而这时的设备d1并不知道参数已经被更新了,所以在时间t2时,设备d1会继续将小球向左移动,使得小球的位置达到图10-3中小白球的地方。从图10-3中可以看到,当参数被调整到小白球的位置时,将无法达到最优点。
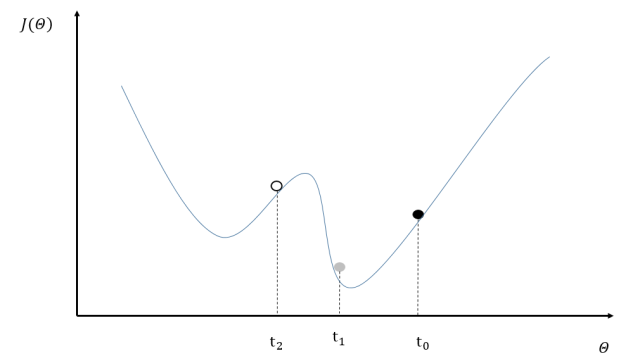
异步模式训练深度学习模型存在的问题示意图
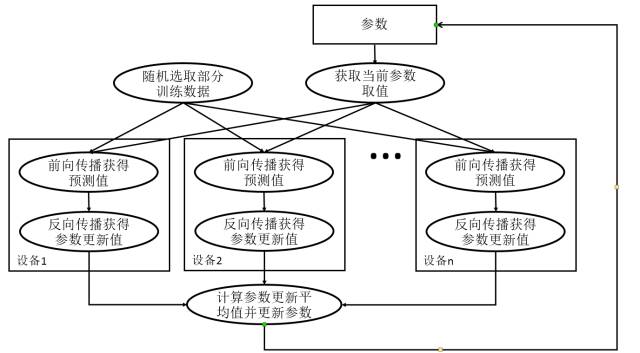
同步模式深度学习模型训练流程图
为了避免更新不同步的问题,可以使用同步模式。在同步模式下,所有的设备同时读取参数的取值,并且当反向传播算法完成之后同步更新参数的取值。单个设备不会单独对参数进行更新,而会等待所有设备都完成反向传播之后再统一更新参数 。图10-4展示了同步模式的训练过程。从图10-4中可以看到,在每一轮迭代时,不同设备首先统一读取当前参数的取值,并随机获取一小部分数据。然后在不同设备上运行反向传播过程得到在各自训练数据上参数的梯度。注意虽然所有设备使用的参数是一致的,但是因为训练数据不同,所以得到参数的梯度就可能不一样。当所有设备完成反向传播的计算之后,需要计算出不同设备上参数梯度的平均值,最后再根据平均值对参数进行更新。
扫描二维码,添加马哥个人微信,领取kindle大奖!

今日值班老师
马哥教育一号女神老师,懂IT更懂IT男。
专注解决Linux技术难题,是天生的技术专家。
如果你正好遇到了问题,为什么不找她求助一下?
Linux面授班,报名优惠400元,只有10个名额







