 我 相 信 这 么 优秀 的 你
我 相 信 这 么 优秀 的 你
已 经 置 顶 了 我
作者:大蕉。平安普惠的数据应用架构师。负责平安普惠的知识图谱和智能分析平台的应用架构和算法开发。微信公众号:一名叫大蕉的程序员
0x00 前言
好像一下子,进入了AI时代,很多小伙伴其实都很迷茫,自己现在该如何去做好准备,去迎接即将到来的All in AI。
所以就有了今天这篇文章啦。今天呢,跟大家分享分享目前机器学习的历程吧,我到现在都没觉得我入门了机器学习,所以也没有什么所谓的经验啊,成功实践啊,没有,都是体验。
0x01 甩三句总结
首先甩三句始终相信的话。
不要为了机器学习而机器学习。
机器学习只有洞悉来自业务的需要,配合业务落地,才能发挥作用,单纯的机器学习没什么用。
python大法好,用2.7。
业界的前沿机器学习基本都是只支持python和C++,行业标准,就用python。
大数据下还是Spark更实用。
在现有大数据的环境下,落地最实用,场景最多的,还是Spark。
0x02 开眼界
脚抬起了3cm。目标:开眼界。
该怎么去下手?
首先从比较宏观的角度,全面了解机器学习的全貌。看看机器学习能做些什么,能解决什么问题,是什么样的套路。
机器学习就是根据已有特征,训练模型,然后根据模型来预测未知的数据。
很多小伙伴一开始就会扎进去什么支持向量机、Logistic回归、LASSO啊、决策树啊这类算法里面,一下去就去非常深入去理解他们的原理,个人认为这种切入方式是有一点问题的,如果仅仅是为了学习一下这些算法,那还行。长远来说,还是要现有大局观。
《图解机器学习》
《集体智慧编程》
《机器学习》周志华
《统计学习方法》李航
这四本书我都买了,循序渐进。
第一本呢,是通俗易懂的机器学习算法图解,作为趣味性入门来说非常好。
第二本是当前机器学习能做些什么事情,以及python怎么实现这些机器学习算法,代码狂人可以在这里面找到一些成就感,推荐先快速翻一遍,再回头,重新一章一章看,一行代码一行代码打,有时候不知道它啥意思也不要紧,打出来跑跑看。
第三本是比较系统地说机器学习的过程,以及每个算法比较严格的数学推导过程,非常严谨,数学要求较高,数学不太好的可以暂时不买,买了也看不懂。
第四本呢,是经典的的机器学习的学习宝典
嘛,也不用四本都买,看不完。小伙伴要是急呢,其实把第一本看了也就行了,眼界也算是开了,只是手头一点米可以下锅都没有而已····
如果对于深度学习有兴趣的小伙伴,可以看看下面这个书,是现在最权威的深度学习的书籍,没有之一,官方已经出了中文版,英文可以的小伙伴还是买英文原版吧。非常详细地说明了机器学习与深度学习的关系,以及深度学习的学习路径。
《DEEP LEARNING》《深度学习》Ian,Goodfellow
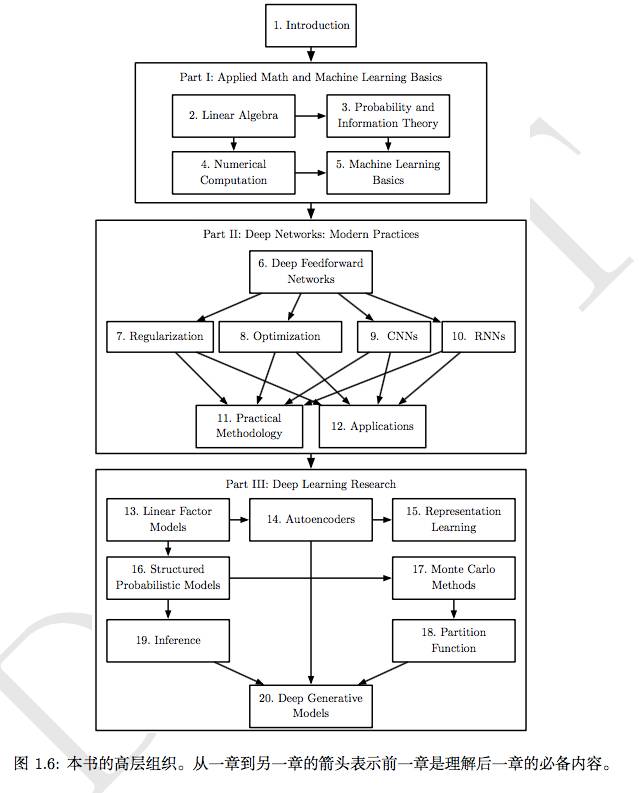
引用自深度学习课本(侵删)
0x03 算法原理
脚抬了5cm了。目标:了解算法。
这个阶段,可以把所有的算法原理都开始看了,主要的书是上面的《机器学习》。如果英语够好的话呢,在coursera上学学Andrew NG的机器学习公开课。如果英语不好的话呢,可以试试邹博老师的《机器学习实战》,中文解释来说还是非常不错的入门教程。
当然,师傅领进门,修行在个人。
教程和书再好都没有用,还是需要你花时间,慢慢慢慢地,去一点点理解透每个算法背后的原理,以及各种各样的优化方法是怎么发生的。
举例线性回归可以这样进阶地去学习:
第一步:纯线性回归。什么是最小二乘法,损失函数怎么求。
第二步:核函数。什么叫多项线性回归,什么叫高斯核线性回归。
第三步:正则化。什么叫正则化,正则化的目的是什么?L0、L1、L2正则各代表什么东西。LASSO,岭回归,ElasticNet都是什么。
第五步:优化方法。如何选择优化方法?随机梯度下降,牛顿法都是些什么?
第四步:广义线性模型。广义线性模型把什么东西涵盖起来了,是怎么抽象怎么推导的?
大概就这样,一点一点去深入,不用一次性把所有的模型都学完。但是个人建议,线性回归,Logistic回归,决策树这三个必须必须完完整整先看完。毕竟很好理解又很好用,太难的臣妾真的做不到啊!!!逃避可耻但有用吖。
0x04 框架应用
脚抬了6cm了。目标:利用成熟框架。
这个阶段呢,就没什么好的书介绍了,使用scikit-learn,libsvm,xgboost去解决前面集体智慧编程里面介绍的一些数据集以及算法吧~会发现超级简单,而且还特么比自己实现的快很多勒。
即使你数学基础很差,即使你编程能力不是很好,但是你依然可以借助框架的力量,去完成你想完成的事情,遇到事情多查一下scikit-learn的官方文档。来来来,大蕉跟你说,怎么利用框架来打造自己的机器学习铠甲。
没有数据集训练模型?大丈夫。scikie-learn为我们准备了sklearn.dataset的数据集套餐。
线性模型比如线性回归、逻辑回归、LASSO、岭回归、ElasticNet不会自己实现?大丈夫。scikie-learn为我们准备sklearn.linear_model进行线性模型训练的套餐
数据预处理太麻烦不会写程序?大丈夫。scikie-learn为我们准备sklearn.preprossing特征预处理套餐。
决策树实现起来太麻烦?太多细节要考虑?
大丈夫。scikie-learn为我们准备了sklearn.tree 进行决策树训练的套餐。
集成方法太难写了?总是写不出推导公式?大丈夫。scikie-learn为我们准备了sklearn.ensemble进行集成方法比如AdaBoost、XGBoost、随机森林、GBDT等进行训练的超级大套餐。
好了就差调参了。
如果你知道哪个模型怎么调参,再Google一下调参技巧,成为机器学习大师的日子就不远了,嗯。
0x05 深度学习初探
脚抬了6.5cm了。目标:开始接触神经网络。
把Tensorflow官网的demo看懂,打一遍。一层一层拨开,看看RNN(循环神经网络) ,CNN (卷积神经网络) ,GAN(对抗生成网络) 这些现在非常流行的神经网络结构的原理是怎么样的,深度学习目前来说离不开这三兄弟。如果还是看不懂呢,可以搜索一下莫凡Tensorflow,蛮入门的,但也仅仅是入门而已。大概了解了解也可以了。
我们使用的数据集是MNIST这个强大的数据集,这个数据集所有都是手写的数字,现在有60000的训练集以及10000的测试集,可以用于我们很多的算法的训练。(至少在学习阶段是这样的嘛~)
我们可以先用Softmax回归实现一个伪深度学习。
http://www.tensorfly.cn/tfdoc/tutorials/mnist_beginners.html
再用卷积神经网络,实现一个真●深度学习算法。
http://www.tensorfly.cn/tfdoc/tutorials/mnist_pros.html
这是一个经典的AlexNet卷积神经网络,就是当年在ImageNet上把深度学习一下子提高到新高度的一个网络结构。也可以用循环神经网络RNN,试试看怎么玩,至于怎么实现,留给小伙伴们去思考吧~
如果你已经完成了上面的步骤,好,你已经可以跟我一样出来是一个demo代码修改工程师,可以出来吹牛逼了,但是其实并没有什么卵用。
当前现在也出现了 fashion-mnist这个数据集,目标就是替代MNIST数据集,大伙也可以下载下来玩玩,API跟MINIST一样一样的。
https://github.com/zalandoresearch/fashion-mnist
0x06 Kaggle实战
脚抬了7cm了。目标:开始实操。
进入Kangle,注册账号,开始进行泰坦尼克号吧。上面会有很多Tutorials(教程)的Kernels(也就是别人写好的一些教程),直接点一个进去。
Titanic: Machine Learning from Disaster
比如说这个:https://www.kaggle.com/jeffd23/scikit-learn-ml-from-start-to-finish
还有这个:https://www.kaggle.com/datacanary/xgboost-example-python
开始学习一下Kaggle是怎么玩的。数据怎么看?数据怎么可视化?用最简单的Logistic回归试试看。提交一下自己的成果上去。怎么提交上面的教程都有说。哇这样就完成第一次Kanggle实战了喂。
前期就好好学习参照别人写好的Kernel,自己手打一遍好好理解一下吧。
当然你可以用决策树,SVM,xgboost,甚至Tensorflow的CNN,RNN来试试看,看看怎么调参,怎么进行特征工程,好好玩把很多的算法都试一遍,争取得到一个比较高的高分吧。
即使得不到高分也没关系。毕竟万事开头难,然后中间难,然后后面巨难嘛~
0x07 落地架构
脚抬了7.5cm了。目标:开始关注落地的事情。
上面说了那么多其实都没开始任何落地的东西,你的模型要怎么训练,怎么开始结合业务来实际应用起来。
作为一个机器学习工程师,如果对于架构不了解,那你的很多想法都是无法落地的,都只能停留在你自己的分析体系中,没法实际应用到生产环境上。这对你来说,是一个很大的欠缺,你的想法跟实际落地还是有很大的鸿沟的。
但是我想说的是少年你对力量还是一无所知,别再自己造轮子了,现在用成熟的开源框架可以直接搭一个非常不错的系统了。
服务层可以用Redis,SparkStreaming,Django。
模型训练层可以使用scikit-learn,libsvm,xgboost等,保存模型用joblib。训练用Spark的话,可以把RDD直接持久化到HDFS上。训练Tensorflow的话,可以直接用框架提供的Saver进行保存喔。
至于特征库层,也就是基础数据存储层可以使用Oracle,Mysql,HBase,ElasticSearch,Redis等,根据数据量和相应速度任君选择。
如果各个组件有需要通讯的,除了api调用外,如果是不需要消费端响应的,可以使用Apache kafka喔。
这样就搭建完成一个完整的能提供在线服务的架构啦。
0x08 数学基础
脚抬了10cm了。目标:开始发现自己数学不够用了。
《概率论与数理统计》陈希孺
《线性代数应该这样学》
这个嘛,慢慢补吧,一时半会补不上来的T_T。
0x09 特征工程
脚抬了11cm了。目标:关于特征工程。
好的特征是成功的一半。业界有这么一句半玩笑但是有点道理的话。特征选择和特征清洗,决定了你模型的上限,你的算法和优化只是不断逼近这个上线而已。该系统学学特征工程的东西了。
特!征!工!程!非!常!重!要!
特征工程,顾名思义,就是批量生产特征的工程化,特征工程一般来说分为两部分,特征提取和特征选择。
好的特征是成功的一半嘛,这个步骤的结果直接决定了你最终模型训练的上限。
关于特征提取
那么特征提取的套路呢,就分五步走,分别解决两个问题,提什么,以及怎么提。
◇ 拍一拍 ◇ 看一看 ◇ 抽一抽 ◇ 洗一洗 ◇ 改一改 ◇
拍一拍
拍啥呢?
拍脑门啊。
管它啥玩意特征提取,先按照业务场景的实际需求先拍一些想去抓取的数据范围出来先。
看一看
那要看什么呢?
看的目的是对数据进行可用性评估。
评估数据获取的难度,数据的规模,数据的准确率,数据的覆盖率。
1.数据获取的难度?
比如你想知道整个城市垃圾场的数据,一桶一桶称?
啊,咋获取,你告诉我咋获取。
难度非常大,这些难度非常大的数据,如果我们觉得它们很重要,我们得换别的思路去代替。
2.数据的规模
数据的规模是十万,一百万还是几千亿?这个一定要摸清楚啊,跟后面处理的工具有很大关系。
3.数据的准确率
社交媒体上的年龄能信?
社交媒体上的性别能信?我看到真人我都无别甄别性别好吗?
4.数据的覆盖率
你所想要实现的业务需求的场景,数据能覆盖吗?会不会有些地方,根本就没有这个数据。或者数据只会存在在某些特定的用户,而其他用户根本就不会有这些数据的?
比如某个农村小白比如小蕉的资产信息,哪来哪来?
“EI,我跟你说,不存在的。”
🙅
“那你很棒棒喔。”
👏
抽一抽
啊,这个有技术含量了。
抽完放哪?抽哪些子集?
放哪?
喏,放那里。☝️
离线部分,可以抽完放HDFS上,或者RDBMS上。
在线部分,可能就要分级放在HBase、ElasticSearch,或者KV数据库等能快速索引的地方了。
抽哪些子集?
有时候数据上千亿,难道全部拿出来咩?也处理不了这么多啊。
只能按照数据分布来采集子集啦。
常用方法有随机采样啦,固定比例采样啦,接受-拒绝采样啦,重要性采样啦,Gibbs采样啦。
抽完还要看看数据分布,看看是不是要重采样啦,是不是要降采样啦,这样。
洗一洗
1.结合业务场景,进行数据列规则进行过滤
"钞票小于100元的我通通都不要。"
"这种拿小钱的粗活累活就让我来承担吧"
2.使用算法进行异常点检测
常用的套路有这些。
K均值聚类啊,层次聚类啊,谱聚类啊,DBSCAN啊,KNN啊。
以及四分位啊,极差啊,标准差,均差,看看数据分布大概是怎样的。
至于偏离太远的,得看看是特殊用户,还是垃圾数据,反正不太应该出现在我们接下里的过程里。
改一改
主要有三个套路要去弄。
标准化,离散化,缺省值。
1.什么叫标准化?
嗯,就是把所有的特征呢,都归到同一个值域里面。头长砍头,脚长砍脚。
🙈"咦,好血腥。。你再这样这个发不出去的小蕉。"
比如颜色像素,有256个值对不对,归到0-1就是全部处于256啦。这个叫归一化。
比如1、3、5、7、9。这种咋办呢?直接每个值都除以(最大值-最小值),这个叫最大最小值归一化。
也可以用Logistic函数,直接映射到0-1上,这个叫函数映射。
也可以直接排序,给他们强行改成新值,这个叫排序归一化。
2.什么叫离散化?
就是将连续的数值进行分箱啦。
(1元,5元]的一箱,(5元,10元]的一箱,这样
“都说了少于100元的我都不要了”
“妈蛋又不是给你的”
3.什么叫缺省值?
就是肯定有些值不知道什么鬼原因,反正就不见了嘛。咋办?
普遍的做法呢,要么就填个众数,要么就填个平均值,要么就用其他机器学习方法预测一个填进去。
别填过头,会粗事的。。
关于特征选择
1.相关性筛选
观察每个变量与其他变量的相关性,线性相关的特征不应该同时出现在模型中。
2.模型打分选择
使用逻辑回归,随机森林等算法,对特征重要性进行打分,再进行下一面的操作。
3.单一特征选择
使用单个特征进行模型训练,得出每个特征的准确率,再进行筛选
4.使用L1,L2正则项进行特征选择
模型,通过L1,L2正则项,得出特征的重要度。
5.特征组合
使用特征组合的方式生成新特征,再进行特征重要度选择。
6.深度学习特征选择
深度学习天生自带特征选择特效,可以直接把数据丢到深度学习算法中进行特征选择。
0x10 持续学习
趴倒在门槛上。目标:深入理解前沿的底层原理。
跟进一些过去的优秀论文,比如MapReduce原理的,比如李沫的Parameter原理的,比如GAN原理的,比如LPA原理的。非常非常多的论文,边实践边看呗。
推荐一点经典的论文。
《MapReduce: Simplified Data Processing on Large Clusters》
《Generative Adversarial Net》
《Parameter Server for Distributed Machine Learning》
0x11 结束语
路漫漫其修远兮,吾边吃酸奶边看书看论文打代码。
所以我就趴倒在门槛上,依然还没入门,还在上面某些阶段努力ing。
迈过门槛只需一步
现在就加入小象学院
《深度学习》
美国纽约城市大学博士
顶会审稿人
CVPR,ICCV,BMVC,WACV等重要会议
及TMM,TIP,CVIU,JVCI等期刊的审稿人
研究领域包括深度学习,计算机视觉,与图像处理等,尤其是自然场景文字检测与识别方向。
原价899
现拼团已达最低价399!
你今天的选择,决定了明天的路。
点击阅读原文立即拼团











