
原文来源
:arXiv
作者:Mahmoud Afifi
「雷克世界」编译:嗯~阿童木呀
 11k Hands数据集涵盖了来自190个18 - 75岁之间的实验对象的11076幅手部图像(1600 x 1200像素)。按照要求,每个实验对象都要张开或是握紧左右手的手指,然后,在统一的白色背景,且手距离相机位置大致相同的情况下,分别从每只手的背侧和手掌侧进行拍摄。有一个与每个图像相关的元数据的记录,其中包括:(1)实验对象ID、(2)性别、(3)年龄、(4)肤色、以及(5)有关所捕捉到的手的一组信息,即右手或左手、手的部位(手背或手掌)以及逻辑指标,即指示手部图像是否包含配饰、指甲油或不符合规则处。所提出的数据集具有大量附加更为详尽的元数据的手部图像。该数据集是免费的,可用于合理的学术研究直接使用。
11k Hands数据集涵盖了来自190个18 - 75岁之间的实验对象的11076幅手部图像(1600 x 1200像素)。按照要求,每个实验对象都要张开或是握紧左右手的手指,然后,在统一的白色背景,且手距离相机位置大致相同的情况下,分别从每只手的背侧和手掌侧进行拍摄。有一个与每个图像相关的元数据的记录,其中包括:(1)实验对象ID、(2)性别、(3)年龄、(4)肤色、以及(5)有关所捕捉到的手的一组信息,即右手或左手、手的部位(手背或手掌)以及逻辑指标,即指示手部图像是否包含配饰、指甲油或不符合规则处。所提出的数据集具有大量附加更为详尽的元数据的手部图像。该数据集是免费的,可用于合理的学术研究直接使用。
有关论文
你可以点击链接阅读论文预印本:
https://arxiv.org/pdf/1711.04322.pdf
有关引用
如果你想要使用本网页所提供的数据集、源代码或经过训练的模型,请引用以下文章:
Mahmoud Afifi:《使用手部图像的大数据集进行性别识别和生物特征识别》。arXiv preprint arXiv:1711.04322 (2017)
统计
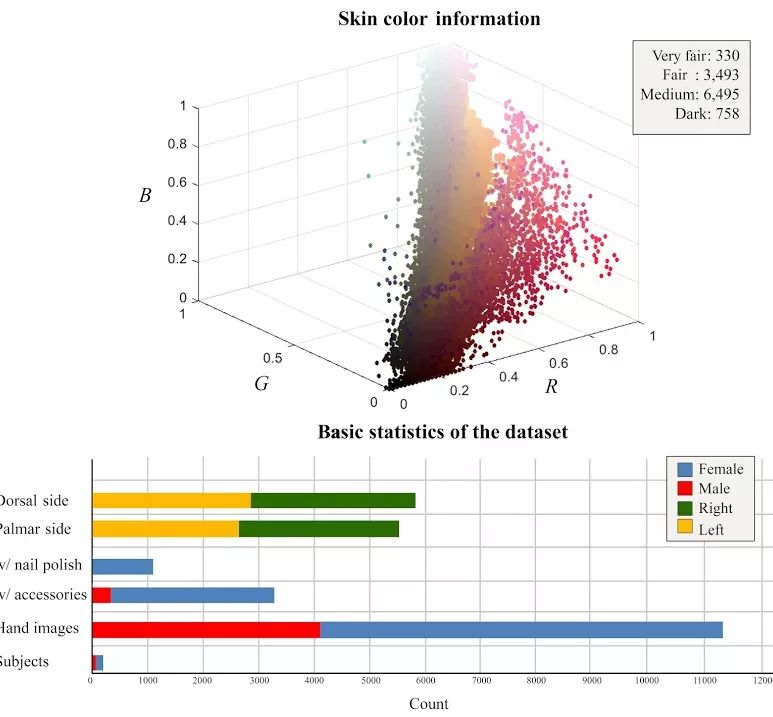
下面的图显示了所提出的数据集的基本统计数据。
第一张图包含以下内容:
顶部:显示数据集中肤色的分布。每种肤色类别的图像数量写在图的右上角。使用Conaire等人提出的皮肤检测算法执行皮肤检测过程。
底部:统计(1)实验对象人数、(2)手部图像(手背和手掌)、(3)带有配饰的手部图像、(4)涂有指甲油的手部图像。
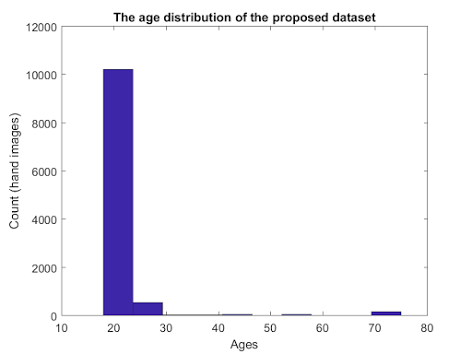
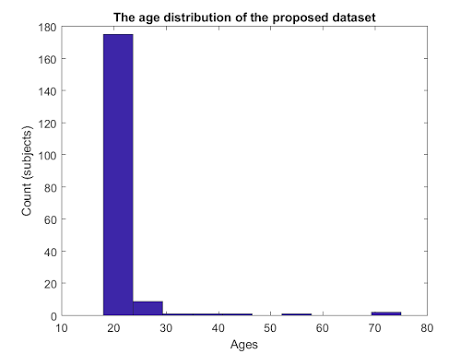
第二张图显示了实验对象的年龄分布以及所提出的数据集中的图像。
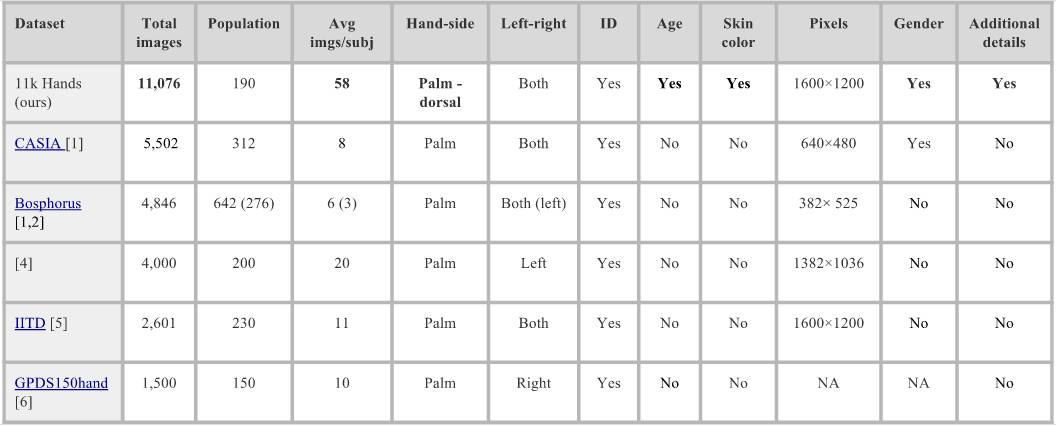
与其他数据集的比较
基础模型
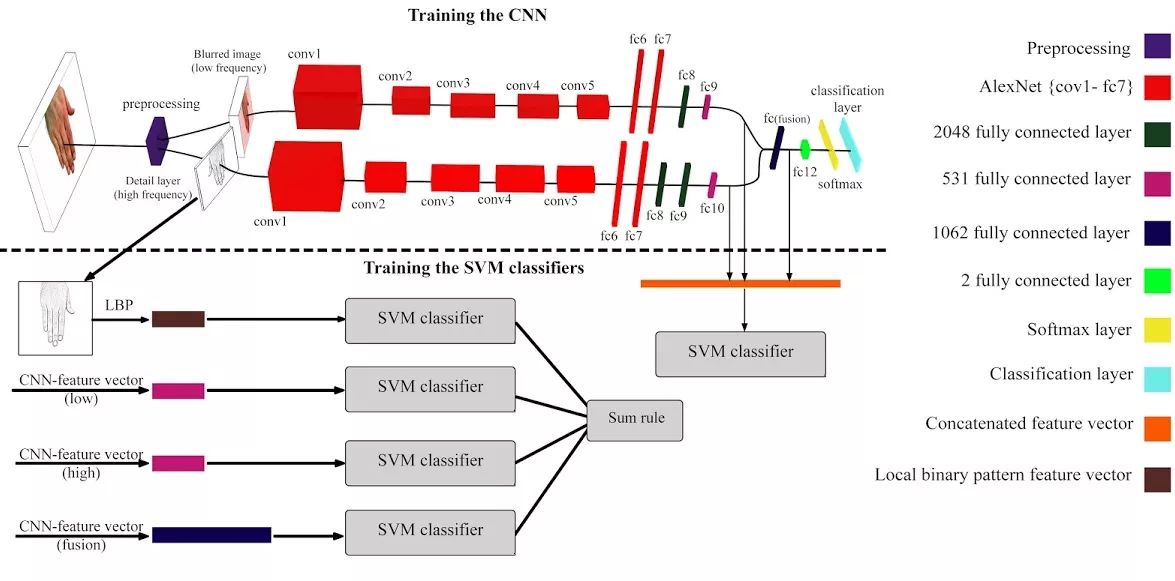
我们提出了使用上述数据集进行性别分类的双流CNN。然后,我们使用这个训练过的双流CNN作为性别分类和生物特征识别的特征提取器。而后者可以使用两种不同的方法进行处理。在第一种方法中,我们从提取训练过的CNN中的深度特征中构造特征向量,以训练支持向量机(SVM)分类器。在第二种方法中,三个SVM分类器是由从已训练CNN的不同层提取的深度特征馈送的,并且其中一个SVM分类器是使用局部二进制模式(LBP)特征来训练的,以便提高通过对所有SVM分类器的分类得分总计所得到的正确识别率。
你可以下面链接中下载经过训练的模型和分类器。
手部图像:
https://drive.google.com/open?id=0BwO0RMrZJCiocGlvdnJxb0lTaHM
元数据:
https://drive.google.com/open?id=0BwO0RMrZJCioMWJFVDZxczFaWEE
性别分类源码:
https://drive.google.com/open?id=1HTNfs4-VCLGkufDnZ_8L_l13qVZ8cypq
生物识别源代码:
https://drive.google.com/open?id=1Fmk1KCbIzSfQVGsISwFUwhp2HykGE43R
使用Conaire等人提出的皮肤检测技术来获得皮肤掩码图像:
https://drive.google.com/open?id=0B6CktEG1p54Wa2VzdktNY2Q0YlU
性别分类
由于我们对女性手部图像数量存在一个偏差(参见上面的统计数据),我们使用每个性别的1000张背部手部图像进行训练,并且使用每个性别的500张背部手部图像进行测试。这些图像是随机挑选的,从而使得训练和测试集是来自不相交的实验对象,这意味着如果这个实验对象的手部图像出现在训练数据中,则将实验对象从测试数据中排除,反之亦然。同样,对于手掌侧手部图像也是一样的。对于每一方,我们重复实验10次以避免过度拟合问题,并将平均精确度作为评估度量。
为了进行比较,我们使用10组训练和测试对来对不同的图像分类方法进行训练。这些方法是:(1)视觉词包(BoW)、(2)Fisher向量、(3)Alexnet(CNN)、(4)VGG-16(CNN)、(5)VGG-19(CNN)和(6)Googlenet(CNN)。对于第一个图像分类框架(BoW和FV),我们使用了三个不同的特征描述符:(1)SIFT、(2)C-SIFT和(3)rgSIFT。为了进行进一步比较,我们建议使用相同的评估标准。下表为实验中使用的10组训练和测试对,请参见下表:

每个集包含以下文件:
g_imgs_training_d.txt:用于训练的图像文件名(背侧)
g_imgs_training_p.txt:训练的图像文件名(手掌侧)
g_imgs_testing_d.txt:用于测试的图像文件名(背侧)
g_imgs_testing_p.txt:用于测试的图像文件名(手掌侧)
g_training_d.txt:g_imgs_training_d.txt中每个相应图片文件名的真实性别
g_training_p.txt:g_imgs_training_p.txt中每个对应图片文件名的真实性别
g_testing_d.txt:g_imgs_testing_d.txt中每个对应图像文件名的真实性别
g_testing_p.txt:g_imgs_testing_p.txt中每个对应图像文件名的真实性别
你可以使用这个Matlab代码(
https://drive.google.com/open?id=0BwO0RMrZJCioelRhLTFmVFgwUTQ
)来提取每个实验中所使用的图像。代码生成10个目录,每个目录包含每个性别的训练和测试集。然后你可以使用imageDatastore函数(
https://cn.mathworks.com/help/matlab/ref/imagedatastore.html?requestedDomain=www.mathworks.com
)来加载它们(请参阅CNN_training.m源代码)。
训练的CNN模型、SVM分类器及结果
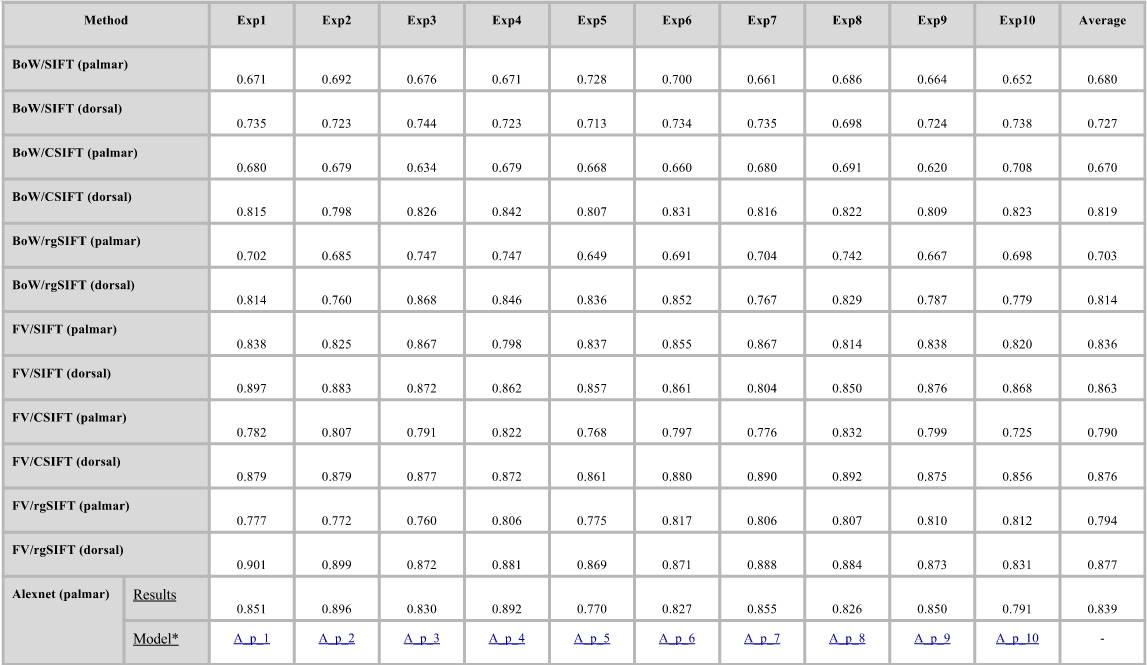
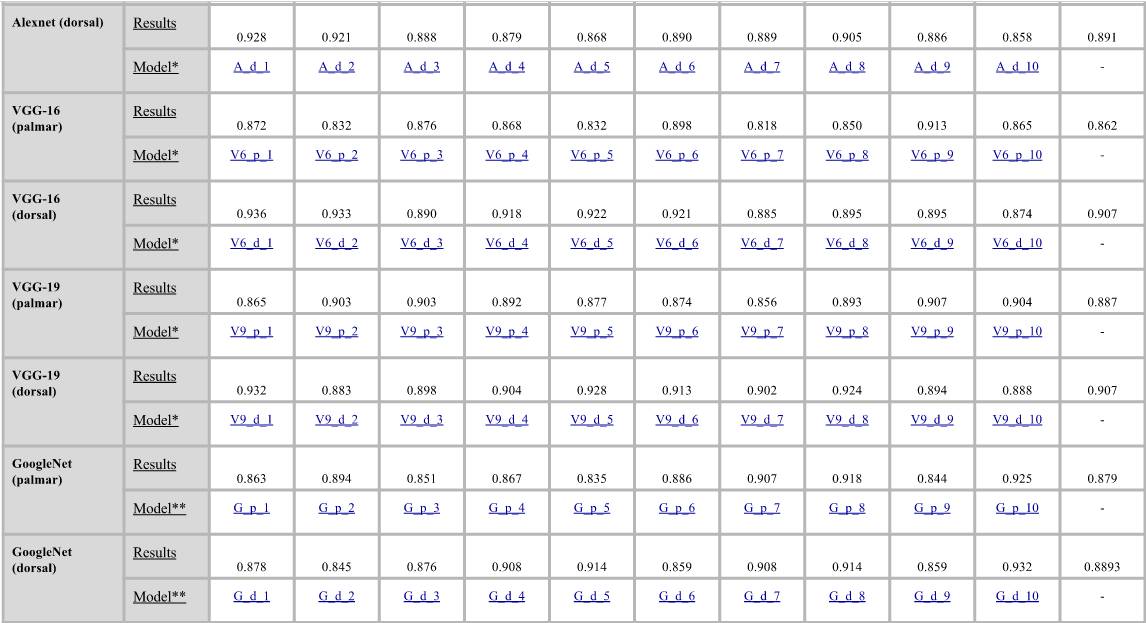
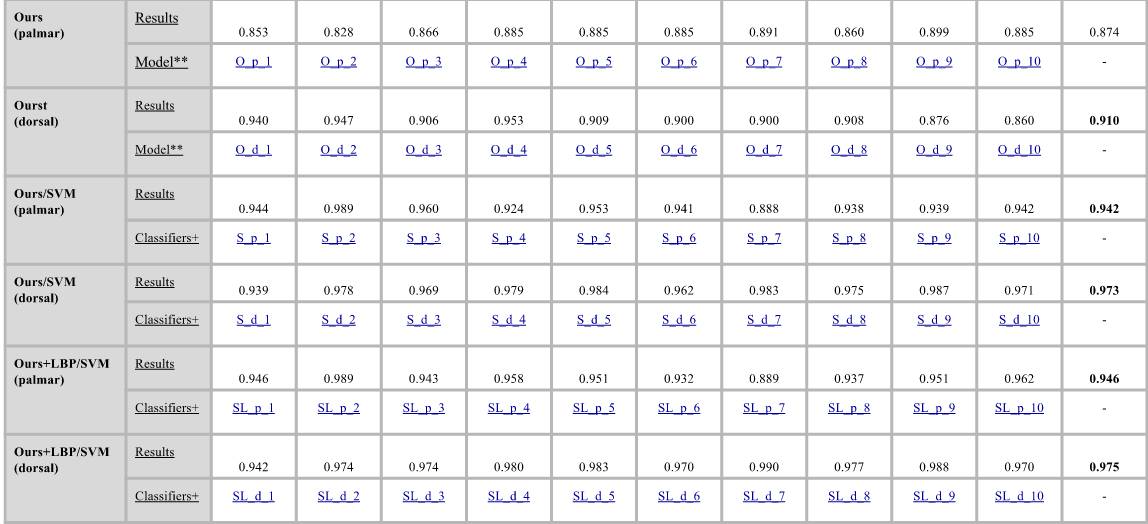
如果你未安装用于网络支持包的Matlab神经网络工具箱模型,则该函数将提供指向附加资源管理器中所需支持包的链接。
正如论文中所描述的那样,使用我们的CNN模型作为特征提取器来训练SVM分类器。SVM分类器是使用级联特征向量进行训练的,其中来自第一个流中的fc9、第二个流中的fc10,而融合完全连接层的特征将被级联到一个向量中。
生物识别
对于生物识别,我们使用不同的训练和测试集。我们使用80、100和120个实验对象的(手掌或背侧)图像中的10张手部图像进行训练,4张手部图像用于测试。我们将重复实验10次,且每次随机挑选实验对象和图像。我们采用平均识别精度作为评估指标。为了进行进一步比较,我们建议使用相同的评估标准。下面为我们实验中使用的10组训练和测试对,请参见下表:

每个集包含以下文件:
id_imgs_training_d_S.txt:用于训练的图像文件名(背侧)
id_imgs_training_p_S.txt:用于训练的图像文件名(手掌侧)
id_imgs_testing_d_S.txt:用于测试的图像文件名(背侧)
id_imgs_testing_p_S.txt:用于测试的图像文件名(手掌侧)
id_training_d_S.txt:id_imgs_training_d_S.txt中每个对应图片文件名的ID
id_training_p_S.txt:id_imgs_training_p_S.txt中每个对应图片文件名的ID
id_testing_d_S.txt:id_imgs_testing_d_S.txt中每个对应图片文件名的真实ID
id_testing_d_S.txt:id_imgs_testing_p_S.txt中每个对应图片文件名的真实ID
注意:
S代表实验对象数量:80、100和120。更多细节可阅读论文了解。
你可以使用这个Matlab代码,提取每个实验中所使用的图像。代码生成10个目录,每个目录包含每组实验对象的训练和测试集。每个文件名都包含实验对象的ID。例如,0000000_Hand_0000055.jpg表示实验对象编号为0000000的图像,其余文件名称为原始图像名称。你可以使用这个Matlab代码来加载所有的图像文件名,并提取相应的ID。
训练的SVM分类器和结果
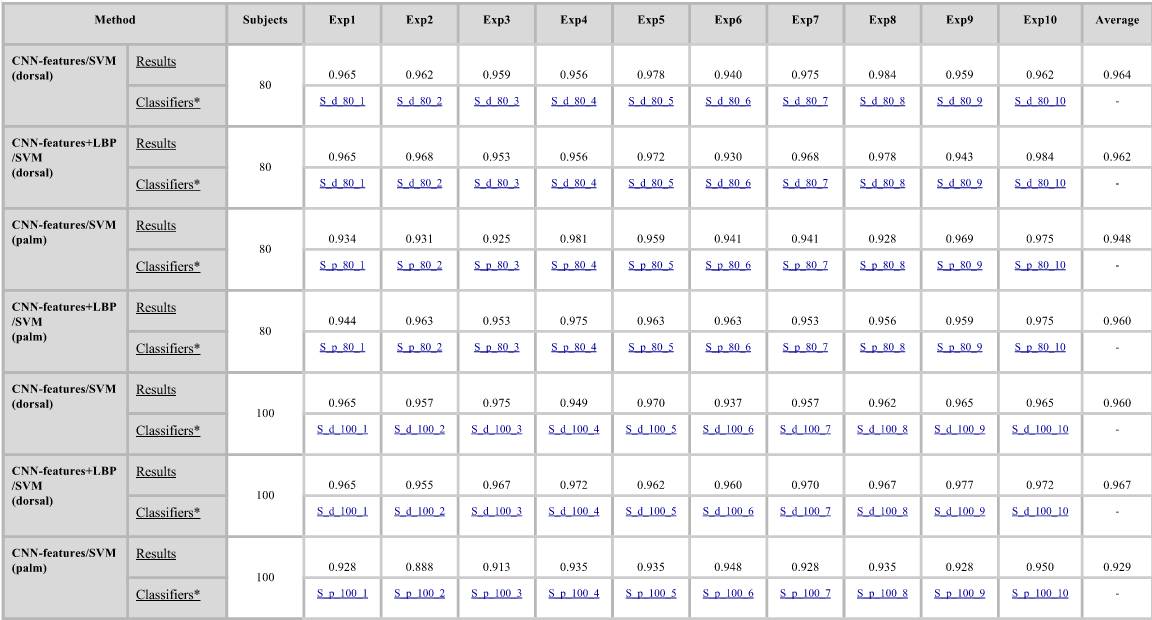
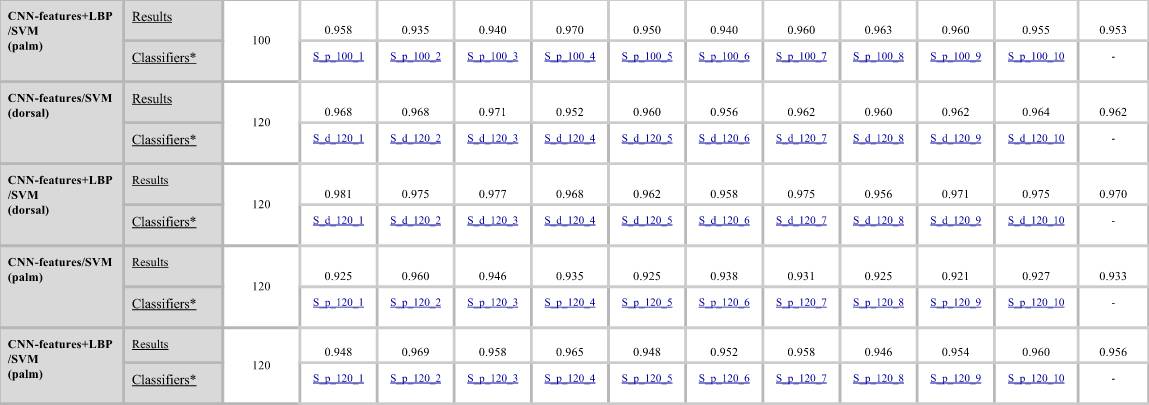
如本文所述,使用我们的CNN模型作为特征提取器来训练SVM分类器。每个.mat文件都包含一个Classifier对象,其中:





