
Python部落(python.freelycode.com)组织翻译,禁止转载,欢迎转发。
作为一个致力于开发出强大可调试系统的软件开发员,我一直对函数式响应型编程之类的框架感兴趣,例如Elm架构。不幸的是天天被工作烦着没有太多时间来仔细了解它,直到复活节假期才腾出手来好好摸索一番!。
初步打算是通过Elm文档里的示例一样完成一个简单的计数器,整个架构建立在函数响应基础上,通过Python来实现。不幸的是,Elm和FRP好像没啥关系,所以就只好用两个不相关的例子来完成整个过程了。想看最终效果的,可以在这个网址看:
https://gitlab.com/Screwtapello/frptui
不过总的来说还是学到不少东西的,今天就来总结下!首先来看下大概背景。
什么是函数式编程?
函数式编程对不同的人有不同的理解,不过在这里我们只讨论其纯粹的数学功能或者就只是功能实现而已。例如,对于一个确定的输入就会有一个确定的输出之类的。下面的代码就是一个纯粹的功能实现:

当你输入参数5时,总会返回一个值12,不用关心函数内部如何实现。

然而,下面的例子就不是一个纯粹的函数式编程了。

即使你每次输入相同的值也不会返回同样的结果。第二次执行时.readline()将会读取文件下一行而不是原来的那一行。

纯粹的函数式代码是非常容易运行的,因为你只需要关心输入输出即可,具体的实现过程可以不用管它。而且非常容易进行单元测试,不用在意API调用和测试设置。不过在一个项目中完全使用函数式编程是不可能的,实际中总需要从外部输入信息并返回一个结果。而且,如果你的有太多的函数式代码,那么你的代码在理解,测试,修复的过程中就会有更大的错误几率。
“响应式”体现在哪里?
函数式响应型编程与纯函数式编程不一样的地方在于,它不是输入一个值就返回一个值,它是接收一个数据流返回一个新的数据流。也可以说这个函数一直都在随着输入流的改变而更新输出流。例如在上面add_seven()这个函数中输入5,9,32,17这个数据流,FRP就会输出12,16,39,24这样的结果。
应用FRP的一个很自然的例子就是服务监控,例如给定一个应用的日志,能够不断的读取日志的信息并返回一些统计结果,如“平均请求延迟"或”每个客户的总计请求“。当然,你还可以增加更多的输入流,比如5分钟移动下平均请求延迟或是一个小时移动下,此外也可以加入一个警报信息当五分钟之内的平均请求比一个小时之内的高20%时。
FRP不仅用在监控上,也可以用在任何事件随时间变化的情景中,比如在数据库中插入更新一个事件,或者用鼠标键盘触发一个事件等。
在Python中使用FRP
如果你写过很多python代码,那么一个数据流产生另一个数据流的函数很像python中的生成器。
先完成个生成器函数
你可能用python写过下面的函数生成器:

然而python的生成器和FRP是不一样的,它是被设计成链接在一块的长链,一旦产生一个值必须移动到下一个值,不能产生下一个生成器需要的相同的数。举个例子,有一个加法函数:

你可以用这个函数将两个相同的数进行相加:

但是如果有一个生成器将两个迭代数相加的函数:

你就不能将两个相同的数进行相加:

以上结果不应该是14(5的两倍不应该是14)
由于python生成器工作方式的缘故,当add_generator()函数调用zip()时会得到xs的前两个数,而不是对第一个数进行复制。所以,要想在python中使用FRP我们必须采取不同的策略,必须使这些数据流可重复利用,就像数字5一样能用到不同的流函数里,而且永远用不完。
数据流接口
在FRP中有两种基本的类型来传递信息变化:
1、Push方式:被动等待输入信号,然后将输入一直传递下去,直到得到所有的输出
2、Pull方式:根据结果一层层向上流搜寻引起变化的值,直到找到所有影响输出的输入值
在python中对输出值的引用并没有标准的方式,因此使用push模式是不太方便的;此外python中可以引用输入值(就是调用函数的形参),因此pull模式是最好的选择。
假设这里有一个表示数据流的对象,在pull模式中我们需要一个能查找当前值的方法;

作为一个非常基本的例子,我们可以拿一个包含数字序列的流:

这按照你希望的方式工作了:

这个数据流和add()一样简单:
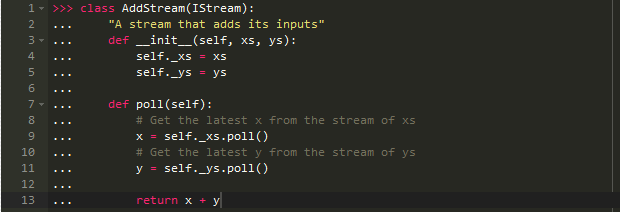
如果我们把5和7分别给这个数据流函数就会得到12,就像进行加法操作一样:

现在我们可以以FRP的样式重构前面的生成器了:

怎么计算结果是不对的?这不就是我们前面遇到的问题吗?
数据流接口2
如果将一个数据流看作随时间变化的值,那么在相同的时间对poll()的调用返回相同的值是可以说得通的。确切的来说调用poll()时会有纳秒级别的差别,不过我们都将这看成是一样的了。也就是说我们需要向IStream引进时间的概念,以便它在检测输出流时能保持相同的时间,然后能提前看接下来会发生什么。

继续添加一个名为phase的新参数。 当调用s.poll()时,如果phase的值与之前的调用相同,则该方法必须返回与先前调用相同的值。 如果phase参数自上一次调用以来发生变化,则重新计算输出。大致就是系统决定它处于蓝色阶段时会查询所有它关心的输入并确保计算都是在同一状态下进行的,然后可以转变成绿色状态,此时所有的输出都应该和之前不一样。因为每一个数据流都需要判断它所处于的状态,所以将这个函数打包成易于调用的形式:
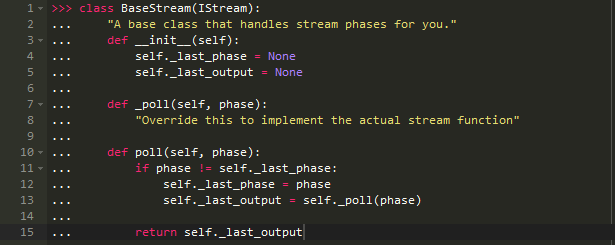
现在再计算我们需要的输出时可以不用覆盖.poll()了,因为它只能调用同一状态的值。注意._poll()仍是一个参数,它需要来自其它流的数据,当在查询这些数据时,会将结果传递回当前的状态。接下来,重新写下NumberStream:
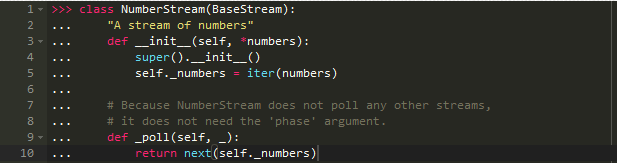
确保NumberStream代表的状态:

同时, AddStream与之前几乎相同
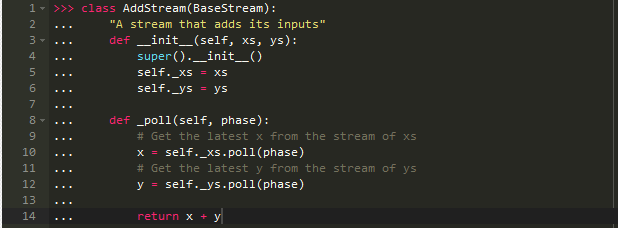
但是这一次我们加入了状态显示,所以可以计算相同的值:

状态流函数
到目前为止,我们可以像纯函数那样实现数据流函数的加法了,而且可以非常容易理解数据流函数的加法本质。然而数据流隐藏了当前数据的位置,这意味着我们可以写出像纯函数那样更多的流函数。虽然不能够像全局变量那样获取任意位置的变量,但是对于流函数只要对于给定的输入就有确定的输出即可,而且还可以保留其易于理解,测试的函数式编程的特性。
假设我们有一个间歇性输入流,也就是有时有有用的值有时没有,但是,我们总是希望有一个值(可以拿来和其它数据流进行比较),那么我们就需要填补这些间隙来让输出总能产生有意义的值。就像下面这样:
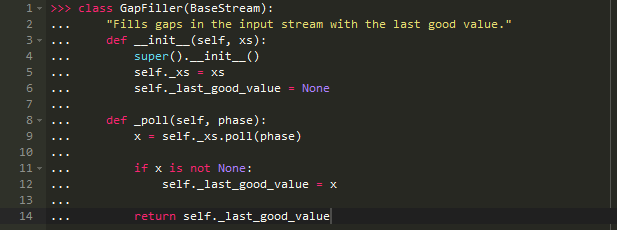
GapFiller以._last_good_value属性的形式维护了额外的状态,使其行为完全由输入流确定,因此可以像纯函数一样对它做测试:
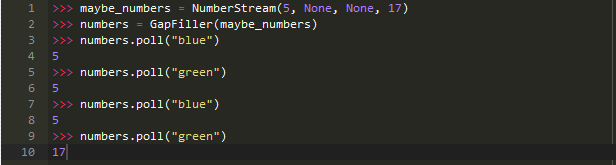
使它更完美
现在我们已经有了基本的FBR功能来工作了,但是它是不好用的,创建一个新的BaseStream子类来覆盖._poll(),接着在输入流上调用.poll(),这整个都是流函数的逻辑过程。
流函数装饰器










