获取帮助
授人以鱼不如授人以渔。当我们不清楚某个命令或者函数的用法时,使用help命令获取帮助是不错的选择,具体用法为help('函数名')。

上面的例子中,我们使用help查询print函数的用法。Python返回print的语法以及每个参数的用法。由于Python和包的迭代较快,很多纸质和网络教材编写时依据的Python版本难以保证是最新版,有的函数已被弃用或者用法发生改动,因此我们推荐有一定英语阅读能力的读者使用help命令获取最新版的帮助信息。
缩进
在介绍Python常用包和数据类型之前,我们首先介绍Python代码的缩进。Python的一大特色就是严格的代码缩进要求,与别的语言中缩进只是为了方便代码阅读与修改不同,在Python中每行代码前的缩进都有语法和逻辑上的意义。这样的强制要求增加了代码的可读性,也使得代码总体较为美观。通常我们选择4个空格或1个Tab来进行缩进, Anaconda中的Spyder IDE也会在写代码过程中自动进行缩进。如果要进行多行代码的集体缩进,可以选中目标代码按Tab进行集体向右缩进,Shift+Tab进行集体向左缩进。
列表
列表(list)是Python中的有序集合类型,列表的元素可以包括任何种类的对象:数字、字符串、或者其他的列表、DataFrame等等。下面是常见的列表操作:

上述代码中,list1列表包含1个字符串'Huatai',list2列表包含1个整数601688。我们使用简单的加法,把两个列表拼接了起来,得到包含2个元素的列表list3。11-12行是列表的索引,Python序列的索引从0开始,因此list3[1] 返回的是列表中的第2个元素。在Python中,我们以#号开头为代码添加注释,如第1行所示,能够大大提高代码的可读性。
NumPy 和数组
NumPy是数据科学领域最常用的Python包之一,能够储存和处理大型数组,具备强大的科学计算功能。NumPy的核心是多维数组对象,即ndarray。这种面向数组的编程方式,使得对海量数据的处理更为方便,逻辑更加清晰。
1. 调入NumPy包

在使用NumPy包之前,需要通过import命令调入NumPy包。以后每次使用NumPy包中的函数,在函数名前加上np.即可。
2. 创建ndarray数组
np.array:输入序列型的对象,通过array函数,将其转换为NumPy数组。下面的例子中我们将列表类型的data通过array函数转换为数组类型的arr1。

np.arange:构建一个等差数列。下面的例子中,我们构建了一个从0开始,包含10个元素的
等差数列。

np.reshape:将数组重塑为另一个形状。下面的例子中,我们将1行10列的数组arr2通过reshape方法转换为2行5列的数组arr3。

另外,我们还可以通过np.zeros或者np.ones直接创建指定长度或形状的全0或1数组。
3.常用函数
np.sqrt:计算数组各元素的平方根。

np.mean:计算数组各元素的算术平均值。

np.std:计算数组各元素的标准差。

np.dot:实现两个矩阵的乘法。下面的例子中,arr3是一个2行5列的矩阵,arr4是5行2列的矩阵。矩阵相乘需要满足的条件是第一个矩阵的列数和第二个矩阵的行数相同。

np.multiply:实现两个数组各元素相乘,两个数据的形状必须相同。
 其中random.randn是NumPy包的函数,作用是生成服从标准正态分布的随机数。参数(2,5)表示生成2行5列的随机数组。
其中random.randn是NumPy包的函数,作用是生成服从标准正态分布的随机数。参数(2,5)表示生成2行5列的随机数组。
np.around:对数值进行四舍五入,取近似值。参数decimal表示保留小数位数,默认保留0位小数,即四舍五入取整数。

更多关于NumPy的详细操作可以参考:http://www.numpy.org/
pandas和DataFrame
pandas是Python Data Analysis Library的缩写,是基于NumPy编写的数据分析包。pandas最大的特色是提供了DataFrame这一数据结构,极大地简化了以往数据分析过程中的一些繁琐操作,受到数据科学领域工作者的欢迎。
1. 调入pandas包

在使用pandas包之前,需要通过import命令调入pandas包。以后每次使用pandas包中的函数,在函数名前加上pd.即可。
2. 数据的读入读出
在进行对数据的处理和分析之前,我们首先需要将数据读入内存;而在处理和分析结束后,我们往往也需要将结果写入文件之中。使用pandas可以很方便地帮助我们完成这项任务。
pd.read_csv('ex1.csv') :读入csv文件。其中pd指调用pandas包,单引号内为将要调用的文件名。
df.to_csv('ex1.csv') :读出csv文件。其中df为将要存储的DataFrame表格名,单引号内为想要存储的文件名。
pd.read_excel('foo.xlsx', 'Sheet1') :读入excel文件
df.to_excel('foo.xlsx', sheet_name='Sheet1') :读出excel文件。其中'Sheet1'是指读入或读出excel文件时使用的工作表名。其余参数用法和csv文件的读入读出类似。
3.Series
pandas的常用数据结构有Series和DataFrame。Series是一种类似于一维数组的对象,由一组数据以及一组与之相关的数据标签组成。构建Series对象的函数:pd.Series
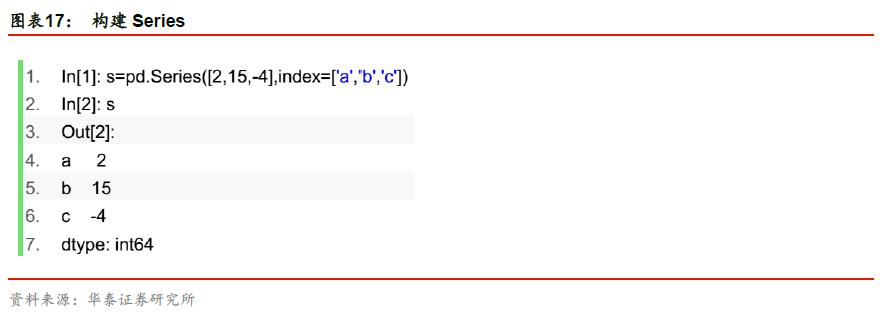 可以看出,pd.Series得到一组一一对应的标签与数据。可以对数据进行切片、数值运算等操作。Series的操作相对简单,在此我们不深入讨论。
可以看出,pd.Series得到一组一一对应的标签与数据。可以对数据进行切片、数值运算等操作。Series的操作相对简单,在此我们不深入讨论。
4.DataFrame
数据集(DataFrame)是一个表格型的数据结构,其直观的存储方式以及丰富的操作,使其成为分析海量数据时使用最多的数据结构。DataFrame通常包含一系列有序的列,每列可以是不同的值类型。DataFrame既有行索引,也有列索引。
pd.DataFrame:构建DataFrame。下面的例子展示了分别构建两个DataFrame即df和df2的过程。
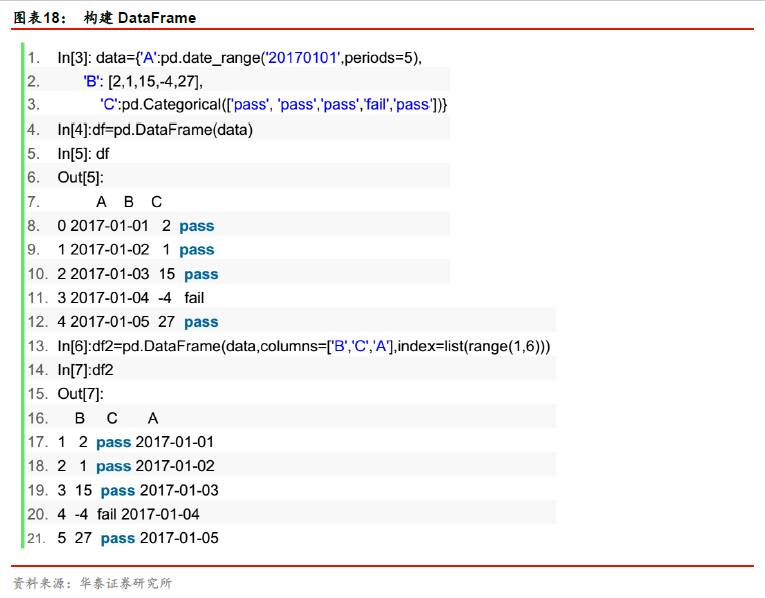 上述代码段的第1行定义了字典(Dictionary)类型的变量data。字典是Python的常用数据类型之一,以花括号{}表示,内部包含多个条目,每个条目包含一组对应的键(key,例如第2行的'B')和值(value,例如第2行的[2,1,15,-4,27])。更多关于字典的操作可以使用help('dict')命令进行查询。
上述代码段的第1行定义了字典(Dictionary)类型的变量data。字典是Python的常用数据类型之一,以花括号{}表示,内部包含多个条目,每个条目包含一组对应的键(key,例如第2行的'B')和值(value,例如第2行的[2,1,15,-4,27])。更多关于字典的操作可以使用help('dict')命令进行查询。
定义字典data之后,我们以data为基础,构建了df和df2两个DataFrame。df和df2的区别在于columns和index。columns是对其列索引的管理,可指定列的名称;index是对行索引的管理,可指定行的名称。index在赋值之后不可更改。我们可以在初始化DataFrame时,赋予其行索引值,如index=list(range(5)),默认为从0开始公差为1的等差数列,共5个数;如果需要设置为从1开始,如In[6],可使用index=list(range(1,6)),即取[1,6)中的5个正整数;当然也可以直接赋予其它值。
sort_index() 或 sort_values():对DataFrame按某一列进行排序。下面的例子中,我们对df按B的大小降序排列。

dropna:去除DataFrame中的缺失值。

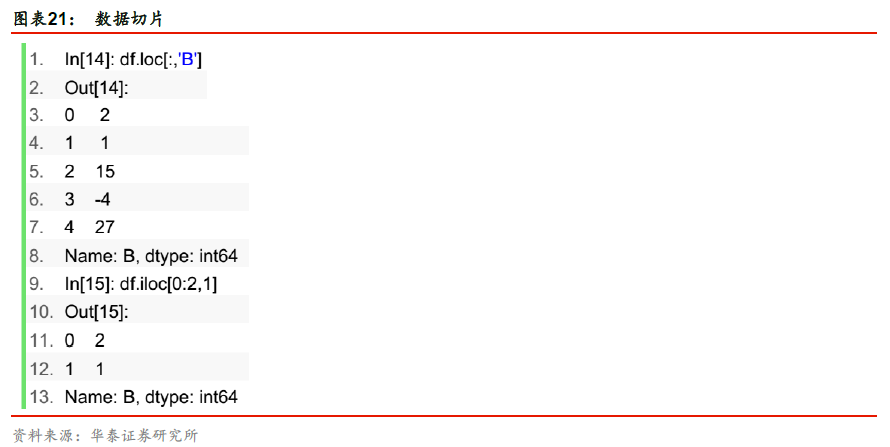
loc和iloc:对数据进行切片,选取部分内容。loc是根据dataframe的具体标签选取列,而iloc是根据标签所在的位置,从0开始计数。其中中括号内逗号前是指选取的行序列,逗号后是指选取的列序列。
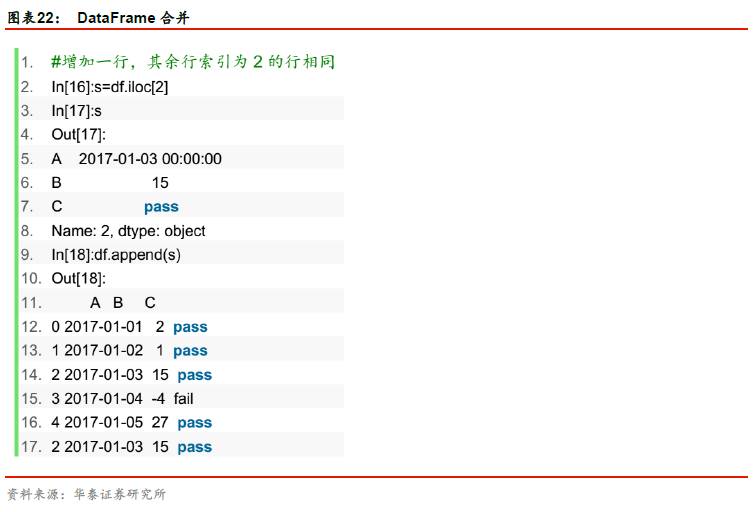
append:连接另一个DataFrame对象,产生一个新的DataFrame对象。
 更多详细的pandas使用指南可以参考:http://pandas.pydata.org/pandas-docs/stable/10min.html
更多详细的pandas使用指南可以参考:http://pandas.pydata.org/pandas-docs/stable/10min.html
scikit-learn
scikit-learn简称sklearn,是Python机器学习中使用最为广泛的包,用户界面友好,并且对常用的算法实现进行了高度优化。sklearn囊括了广义线性模型、支持向量机、朴素贝叶斯、线性和二次判别分析、决策树、随机森林、神经网络、PCA、k近邻等常见的机器学习算法,此外还提供了数据预处理、交叉验证集划分、网格搜索、分类正确率计算等众多工具。我们将在第三部分Python代码实战章节具体介绍sklearn的使用方法。sklearn的官方网站给出了更详细使用指南:http://scikit-learn.org/stable/
除了上述介绍的包以外,SciPy广泛应用于高级科学计算,Matplotlib是Python常用的可视化工具,可以方便地制作多种类型的图表。更多详细的使用指导可以参考官方网站:
https://docs.scipy.org/doc/scipy/reference/
http://matplotlib.org/users/index.html












