综合以上两点,本推文所使用的输入和输出为利用过去30天的数据预测将来五天的收益。
测试对象:沪深300
数据选择和处理:
input的时间跨度为30天,每天的features为['close','open','high','low','amount','volume']共6个,因此每个input为30×6的二维向量。
部分代码:
train_input = []
train_output = []
test_input = []
test_output = []
for i in range(conf.seq_len-1, len(traindata)):
a = scale(scaledata[i+1-conf.seq_len:i+1])
train_input.append(a)
c = data['return'][i]
train_output.append(c)
for j in range(len(traindata), len(data)):
b = scale(scaledata[j+1-conf.seq_len:j+1])
test_input.append(b)
c = data['return'][j]
test_output.append(c)
train_x = np.array(train_input)
train_y = np.array(train_output)
test_x = np.array(test_input)
test_y = np.array(test_output)
import tensorflow as tf
def atan(x):
return tf.atan(x)
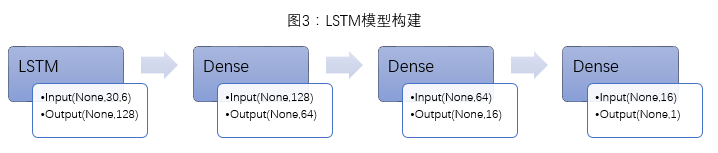
lstm_input = Input(shape=(30,6), name='lstm_input')
lstm_output = LSTM(128, activation=atan, dropout_W=0.2, dropout_U=0.1)(lstm_input)
Dense_output_1 = Dense(64, activation='linear')(lstm_output)
Dense_output_2 = Dense(16, activation='linear')(Dense_output_1)
predictions = Dense(1, activation=atan)(Dense_output_2)
model = Model(input=lstm_input, output=predictions)
model.compile(optimizer='adam', loss='mse', metrics=['mse'])
model.fit(train_x, train_y, batch_size=conf.batch, nb_epoch=10, verbose=2)
predictions = model.predict(test_x)
data1 = test_y
data2 = predictions
fig, ax = plt.subplots(figsize=(8, 6))
ax.plot(data2,data1, 'o', label="data")
ax.legend(loc='best')
for i in range(len(predictions)):
if predictions[i]>0:
predictions[i]=1
elif predictions[i]<=0:
predictions[i]=-1
cc = np.reshape(predictions,len(predictions), 1)
databacktest = pd.DataFrame()
databacktest['date'] = datatime
databacktest['direction']=np.round(cc)
每个模型做两次回测,第一次回测(后文简称回测1)为直接以LSTM预测值在沪深300上做单:若LSTM预测值为1,买入并持有5day(若之前已持仓,则更新持有天数),若LSTM预测值为-1,若为空仓期,则继续空仓,若已持有股票,则不更新持有天数;
第二次回测(后文简称回测2)为以LSTM为择时指标,与StockRanker结合在3000只股票做单:若LSTM预测值为1,则允许StockRanker根据其排序分数买入股票,若LSTM预测值为-1,若为空仓期,则继续空仓,若已持有股票,则禁止StockRanker买入股票,根据现有股票的买入时间,5天内清仓;
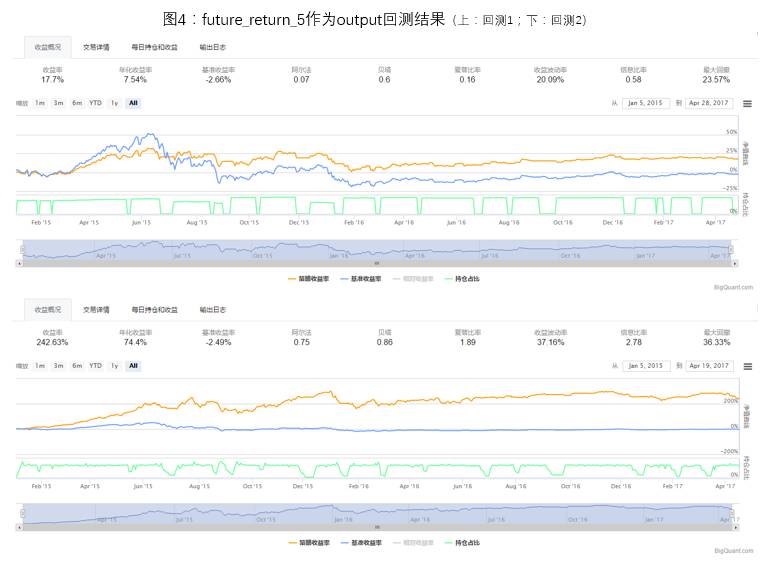
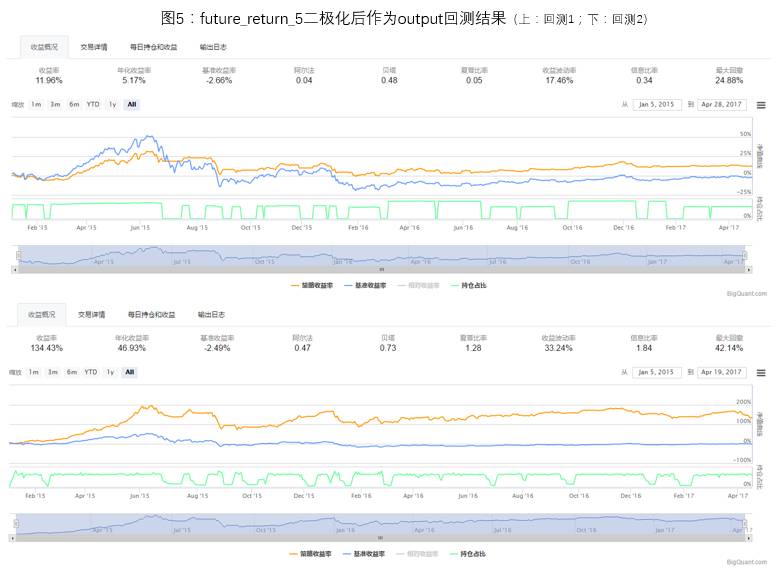
1)future_return_5是否二极化处理比较
对于future_return_5的处理分为两种情况,一种为直接将future_return_5作为output进行模型训练,二是将future_return_5二极化(future_return_5>0,取1;future_return_5<=0,取-1),然后将二极化后的数据作为output进行模型训练。
两种处理方法的回测情况如图4,图5。由于模型每次初始化权重不一样,每次预测和回测结果会有一些差别,但经过多次回测统计,直接将future_return_5作为output进行模型训练是一个更好的选择。在本推文接下来的讨论中,将会直接将future_return_5作为output进行模型训练。
2)在权重上施加正则项探究
神经网络的过拟合:在训练神经网络过程中,“过拟合”是一项尽量要避免的事。神经网络“死记”训练数据。过拟合意味着模型在训练数据的表现会很好,但对于训练以外的预测则效果很差。原因通常为模型“死记”训练数据及其噪声,从而导致模型过于复杂。本推文使用的沪深300的数据量不是太多,因此防止模型过拟合就尤为重要。
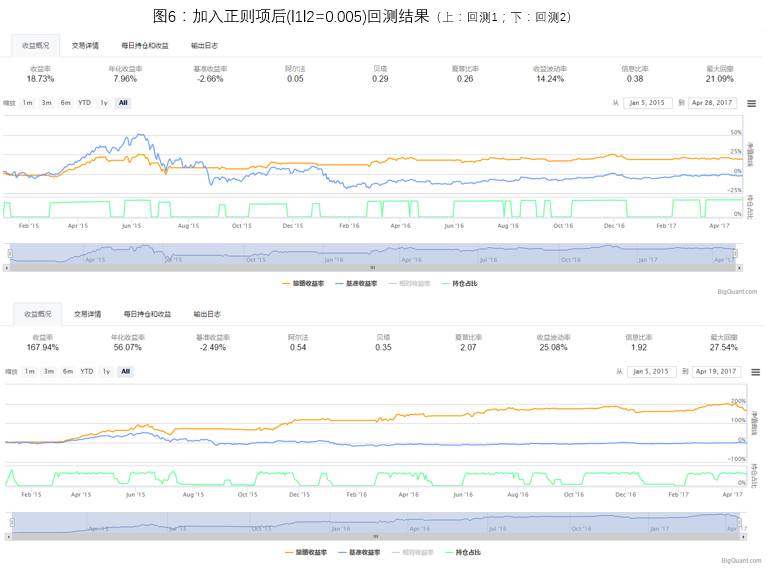
训练LSTM模型时,在参数层面上有两个十分重要的参数可以控制模型的过拟合:Dropout参数和在权重上施加正则项。Dropout是指在每次输入时随机丢弃一些features,从而提高模型的鲁棒性。它的出发点是通过不停去改变网络的结构,使神经网络记住的不是训练数据本身,而是能学出一些规律性的东西。正则项则是通过在计算损失函数时增加一项L2范数,使一些权重的值趋近于0,避免模型对每个feature强行适应与拟合,从而提高鲁棒性,也有因子选择的效果;在1)的模型训练中,我们加入了Dropout参数来避免过拟合。接下来我们尝试额外在权重上施加正则项来测试模型的表现。
回测结果如图6,加入正则项之后回测1和回测2的最大回撤均有下降,说明加入正则项后确实减轻了模型的过拟合。比较加入正则项前后回测1的持仓情况,可以看到加入正则化后空仓期更长,做单次数减少(19/17),可以理解为:加入正则项之后,模型会变得更加保守。
正则项的问题:经过试验,对于一个LSTM模型来说,正则项的参数十分重要,调参也需要长时间尝试,不合适的参数选择会造成模型的预测值偏正分布(大部分预测值大于0)或偏负分布,从而导致预测结果不准确,而较好的正则参数会使模型泛化性非常好(图6所用参数训练出来的模型的预测值属于轻度偏正分布)。本文之后的讨论仍会基于未加权重正则项的LSTM模型。
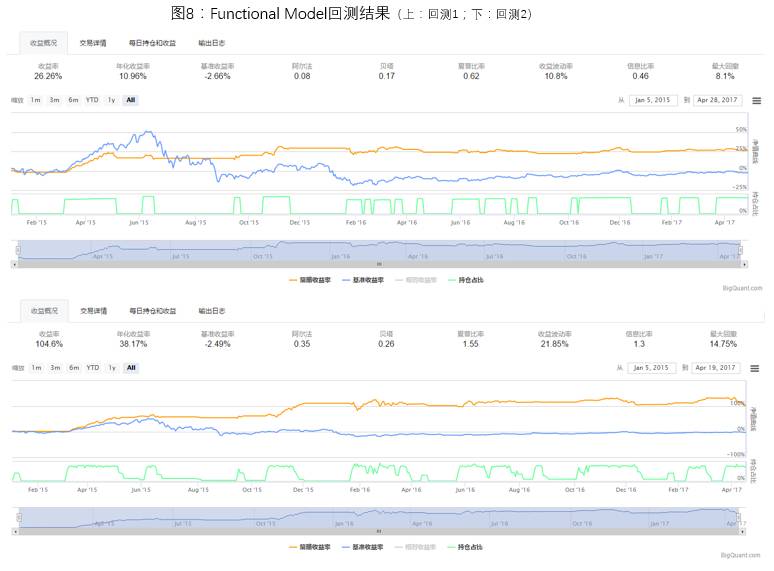
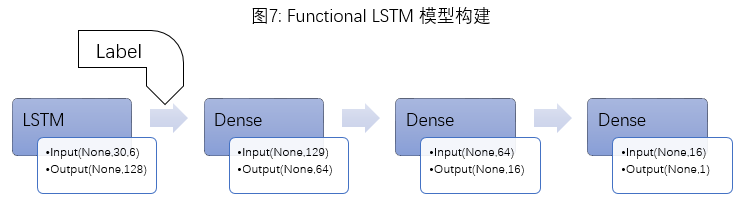
3)双输入模型探究
除了传统的Sequential Model(一输入,一输出)外,本推文还尝试构建了Functional Model(支持多输入,多输出)。前面提到的features处理方法丢失了一项重要的信息:价格的高低。相同的input处在3000点和6000点时的future_return_5可能有很大不同。因此,本文尝试构建了"二输入一输出"的Functional Model:标准化后的features作为input输入LSTM,LSTM层的输出结果和一个指标-label(label=np.round(close/500))作为input输入后面的Dense层,最终输出仍为future_return_5(图7)。
部分代码:
class conf:
start_date = '2010-01-01'
end_date='2017-05-01'
split_date = '2015-01-01'
instruments = D.instruments(start_date, end_date)
label_expr = ['return * 100', 'where(label > {0}, {0}, where(label < -{0}, -{0}, label)) + {0}'.format(20)]
hold_days = 5
features = ['close_5/close_0',
'close_10/close_0',
'close_20/close_0',
'avg_amount_0/avg_amount_5',
'avg_amount_5/avg_amount_20',
'rank_avg_amount_0/rank_avg_amount_5',
'rank_avg_amount_5/rank_avg_amount_10',
'rank_return_0',
'rank_return_5',
'rank_return_10',
'rank_return_0/rank_return_5',
'rank_return_5/rank_return_10',
'pe_ttm_0',
]
m1 = M.fast_auto_labeler.v5(
instruments=conf.instruments, start_date=conf.start_date, end_date=conf.end_date,
label_expr=conf.label_expr, hold_days=conf.hold_days,
benchmark='000300.SHA', sell_at='open', buy_at='open'
)
m2 = M.general_feature_extractor.v5(
instruments=conf.instruments, start_date=conf.start_date, end_date=conf.end_date,
features=conf.features)
m3 = M.transform.v2(
data=m2.data, transforms=T.get_stock_ranker_default_transforms(),
drop_null=True, astype='int32', except_columns=['date', 'instrument'],
clip_lower=0, clip_upper=200000000)
m4 = M.join.v2(data1=m1.data, data2=m3.data, on=['date', 'instrument'], sort=True)
m5_training = M.filter.v2(data=m4.data, expr='date < "%s"' % conf.split_date)
m5_evaluation = M.filter.v2(data=m4.data, expr='"%s" <= date' % conf.split_date)
m6 = M.stock_ranker_train.v2(training_ds=m5_training.data, features=conf.features)
m7 = M.stock_ranker_predict.v2(model_id=m6.model_id, data=m5_evaluation.data)
if databacktest['direction'].values[databacktest.date==current_dt]==-1:
instruments = list(reversed(list(ranker_prediction.instrument[ranker_prediction.instrument.apply(lambda x: x in equities and not context.has_unfinished_sell_order(equities[x]))])))
for instrument in instruments:
if context.trading_calendar.session_distance(pd.Timestamp(context.date[instrument]), pd.Timestamp(current_dt))>=5:
context.order_target(context.symbol(instrument), 0)if not is_staging and cash_for_sell > 0:
instruments = list(reversed(list(ranker_prediction.instrument[ranker_prediction.instrument.apply(lambda x: x in equities and not context.has_unfinished_sell_order(equities[x]))])))
for instrument in instruments:
context.order_target(context.symbol(instrument), 0)
cash_for_sell -= positions[instrument]
if cash_for_sell <= 0:
break
if databacktest['direction'].values[databacktest.date==current_dt]==1:
buy_dt = data.current_dt.strftime('%Y-%m-%d')
context.date=buy_dt
buy_cash_weights = context.stock_weights
buy_instruments = list(ranker_prediction.instrument[:len(buy_cash_weights)])
max_cash_per_instrument = context.portfolio.portfolio_value * context.max_cash_per_instrument
for i, instrument in enumerate(buy_instruments):
cash = cash_for_buy * buy_cash_weights[i]
if cash > max_cash_per_instrument - positions.get(instrument, 0):
cash = max_cash_per_instrument - positions.get(instrument, 0)
if cash > 0:
context.order_value(context.symbol(instrument), cash)
buy_dates[instrument] = current_dt
context.date = buy_dates
回测结果如图8。由回测结果可以看出,加入指示标后的LSTM模型收益率相对下降,但是回撤更小。LSTM预测值小于0的时间段覆盖了沪深300上大多数大幅下跌的时间段,虽然也错误地将一些震荡或上涨趋势划归为下跌趋势。或许这是不可避免的,俗话说高风险高回报,风险低那么回报也不会非常高,高回报和低风险往往不可兼得。