(点击
上方蓝字
,快速关注我们)
译文:伯乐在线专栏作者 - pine_pie
英文:Mike de Waard
如有好文章投稿,请点击 → 这里了解详情
如需转载,发送「转载」二字查看说明
接上篇。
应用文本回归尝试预测最畅销书排行
在实例“根据身高预测体重”中,我们介绍了线性回归的概念。然而,有时候需要将回归分析应用到像文本这类的非数字数据中去。
在本例中,我们将通过尝试预测最畅销的 100 本 O’Reilly 公司出版的图书,说明如何应用文本回归。此外,我们还介绍在本例的特殊情况下应用文本回归无法解决问题。原因仅仅是这些数据中不含有可以被我们的测试数据利用的信号。即使如此,本例也并非一无是处,因为在实践中,数据可能会含有实际信号,该信号可以被这里要介绍的文本回归检测到。
本例使用到的数文件可以在这里下载(http://xyclade.github.io/MachineLearning/Example%20Data/TextRegression_Example_1.csv)。除了 Smile 库,本例也会使用 Scala-csv 库,因为 csv 中包含带逗号的字符串。我们从获取需要的数据开始:
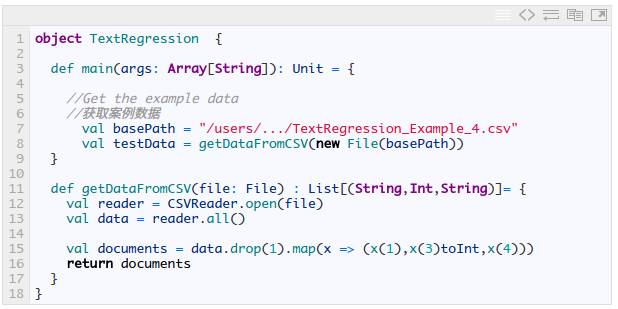
现在我们得到了 O’Reilly 出版社最畅销100部图书的书名、排序和详细说明。然而,当涉及某种回归分析时,我们需要数字数据。这就是问什么我们要建立一个文档词汇矩阵 (DTM)。注意这个 DTM 与我们在垃圾邮件分类实例中建立的词汇文档矩阵 (TDM) 是类似的。区别在于,DTM 存储的是文档记录,包含文档中的词汇,相反,TDM 存储的是词汇记录,包含这些词汇所在的一系列文档。
我们自己用如下代码生成 DTM:
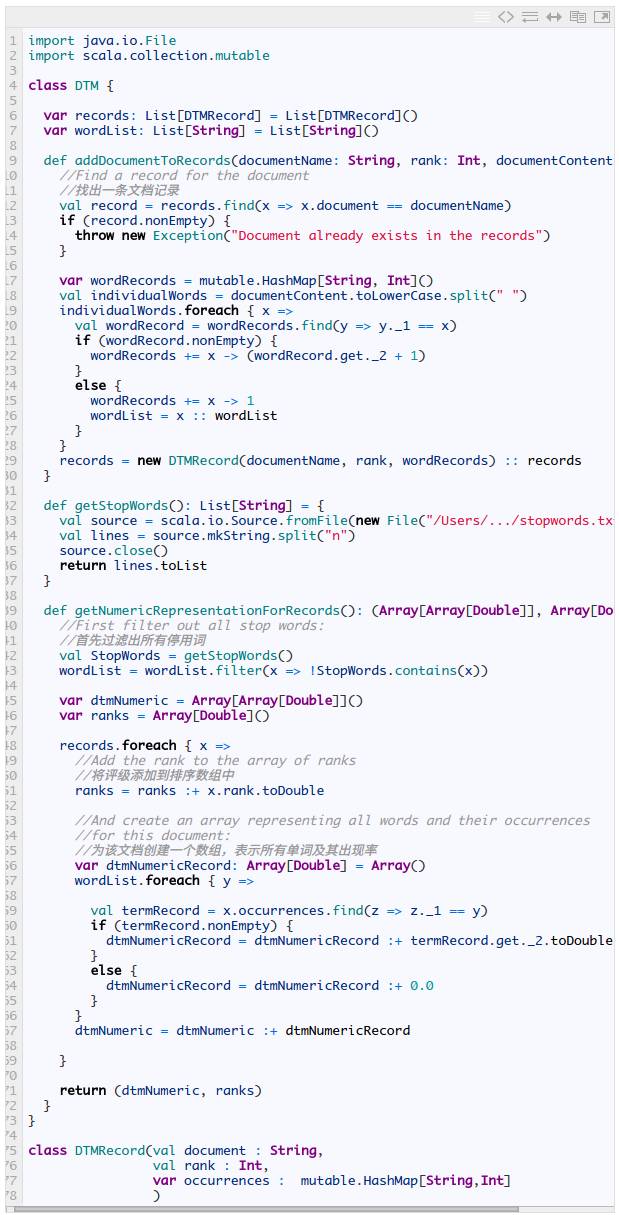
观察这段代码,注意到这里面有一个方法 def getNumericRepresentationForRecords(): (Array[Array[Double]], Array[Double])。这一方法返回一个元组,该元组以一个矩阵作为第一个参数,该矩阵中每一行代表一个文档,每一列代表来自 DTM 文档的完备词汇集中的词汇。注意第一个列表中的浮点数表示词汇出现的次数。
第二个参数是一个数组,包含第一个列表中所有记录的排序值。
现在我们可以按如下方式扩展主程序,这样就可以得到所有文档的数值表示:
val
documentTermMatrix
=
new
DTM
()
testData
.
foreach
(
x
=>
documentTermMatrix
.
addDocumentToRecords
(
x
.
_1
,
x
.
_2
,
x
.
_3
))
有了这个从文本到数值的转换,现在我们可以利用回归分析工具箱了。我们在“基于身高预测体重”的实例中应用了普通最小二乘法 (OLS),不过这次我们要应用“最小绝对收缩与选择算子”(Lasso) 回归。这是因为我们可以给这种回归方法提供某个 λ 值,它代表一个惩罚值。该惩罚值可以帮助 LASSO 算法选择相关的特征(单词)而丢弃其他一些特征(单词)。
LASSO 执行的这一特征选择功能非常有用,因为在本例中,文档说明包含了大量的单词。LASSO 会设法找出那些单词的一个合适的子集作为特征,而要是应用 OLS,则所有单词都会被使用,那么运行时间将会变得极其漫长。此外,OLS 算法实现会检测非满秩。这是维数灾难的一种情形。
无论如何,我们需要找出一个最佳的 λ 值,因此,我们应该用交叉验证法尝试几个 λ 值,操作过程如下:
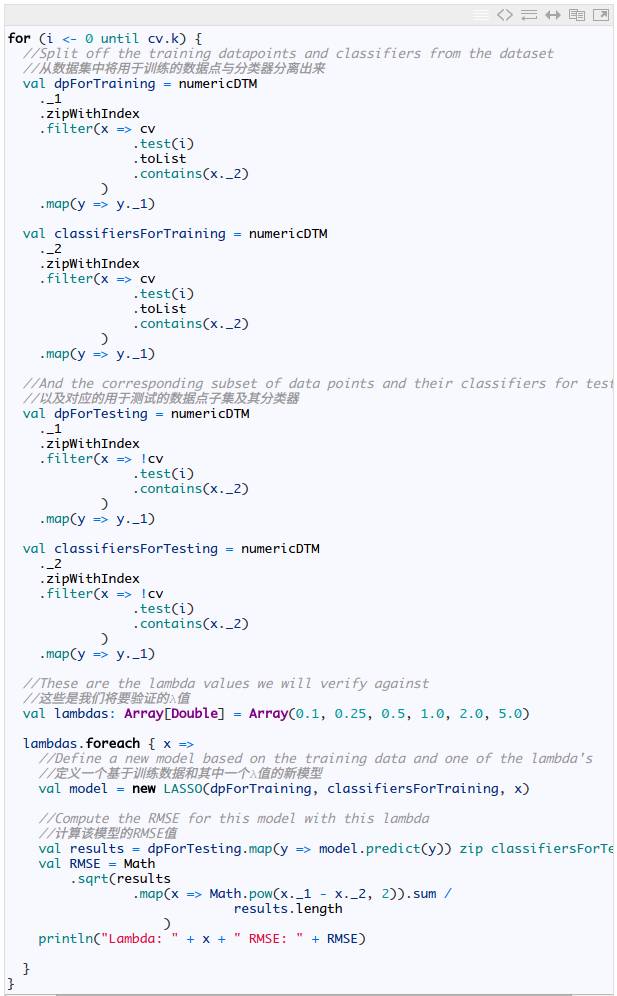
多次运行这段代码会给出一个在 36 和 51 之间变化的 RMSE 值。这表示我们排序的预测值会偏离至少 36 位。鉴于我们要尝试预测最高的 100 位,结果表明这个模型的效果非常差。在本例中,λ 值变化对模型的影响并不明显。然而,在实践中应用这种算法时,要小心地选取 λ 值: λ 值选得越大,算法选取的特征数就越少。 所以,交叉验证法对分析不同 λ 值对算法的影响很重要。
引述 John Tukey 的一句话来总结这个实例:
“数据中未必隐含答案。某些数据和对答案的迫切渴求的结合,无法保证人们从一堆给定数据中提取出一个合理的答案。”
应用无监督学习合并特征(PCA)
主成分分析 (PCA) 的基本思路是减少一个问题的维数。这是一个很好的方法,它可以避免维灾难,也可以帮助合并数据,避开无关数据的干扰,使其中的趋势更明显。
在本例中,我们打算应用 PCA 把 2002-2012 年这段时间内 24 只股票的股价合并为一只股票的股价。这个随时间变化的值就代表一个基于这 24 只股票数据的股票市场指数。把这24种股票价格合并为一种,明显地减少了处理过程中的数据量,并减少了数据维数,对于之后应用其他机器学习算法作预测,如回归分析来说,有很大的好处。为了看出特征数从 24 减少为 1 之后的效果,我们会将结果与同一时期的道琼斯指数 (DJI) 作比较。
随着工程的开始,下一步要做的是加载数据。为此,我们提供了两个文件:Data file 1 和 Data file 2.
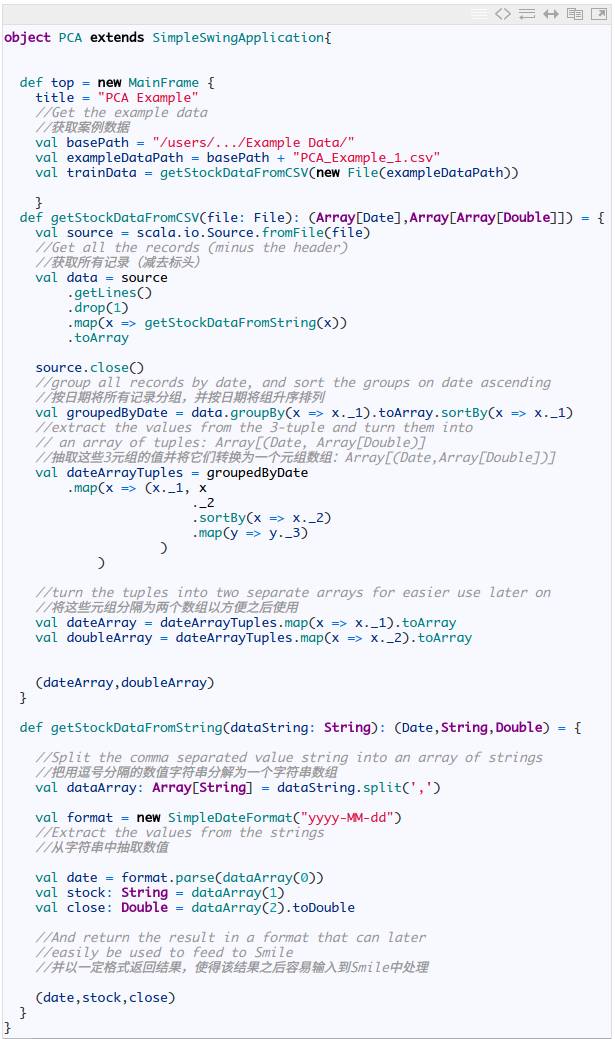
有了训练数据,并且我们已经知道要将24个特征合并为一个单独的特征,现在我们可以进行主成分分析,并按如下方式为数据点检索数据。
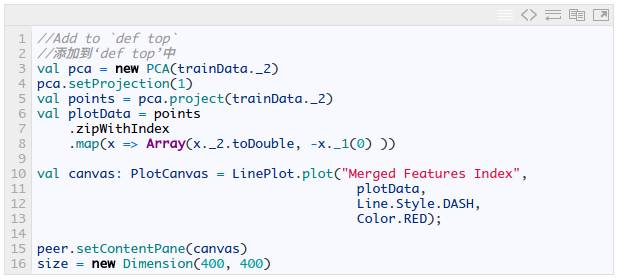
这段代码不仅执行了 PCA,还将结果绘成图像,y 轴表示特征值,x 轴表示每日。
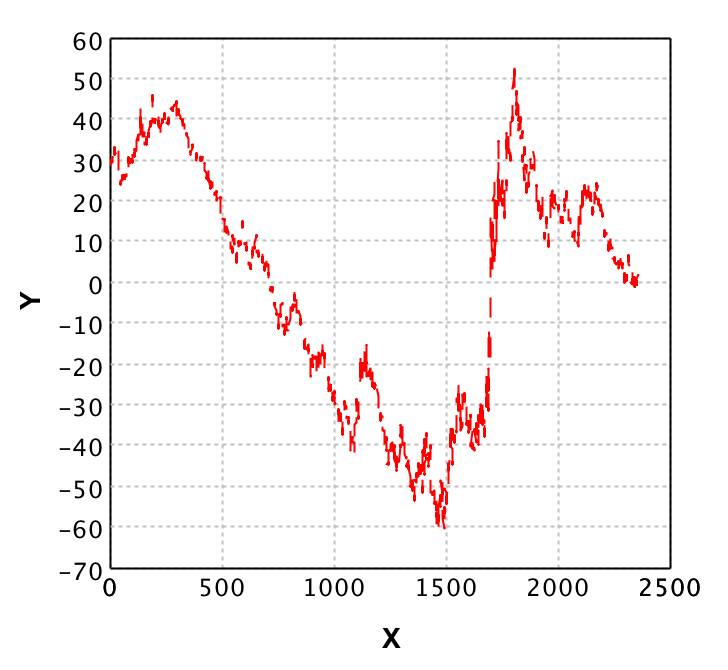
为了能看出 PCA 合并的效果,我们现在通过如下方式调整代码将道琼斯指数加入到图像中:
首先把下列代码添加到 def top 方法中:
//Verification against DJI
//用道琼斯指数验证
val
verificationDataPath
=
basePath
+
"PCA_Example_2.csv"
val
verificationData
=
getDJIFromFile
(
new
File
(
verificationDataPath
))
val
DJIIndex
=
getDJIFromFile
(
new
File
(
verificationDataPath
))
canvas
.
line
(
"Dow Jones Index"
,
DJIIndex
.
_2
,
Line
.
Style
.
DOT_DASH
,
Color
.
BLUE
)
然后我们需要引入下列两个方法:
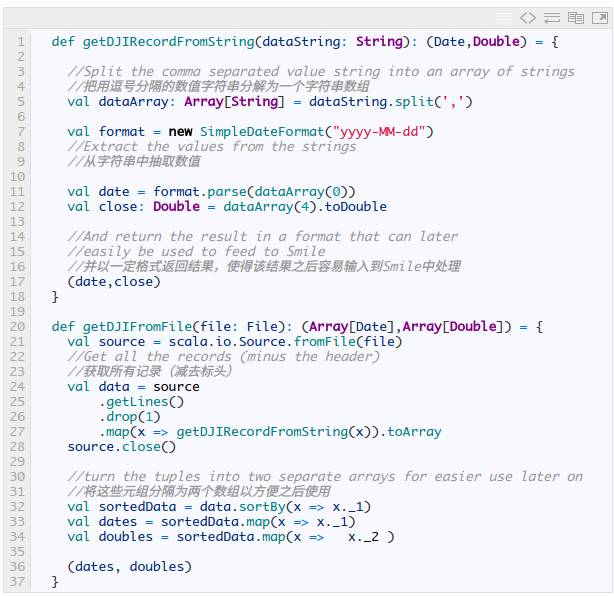
这段代码加载了 DJI 数据,并把它绘成图线添加到我们自己的股票指数图中。然而,当我们执行这段代码时,效果图有点无用.










