本文内容非商业用途可无需授权转载,请务必注明作者及本微信公众号、微博 @唐僧_huangliang,以便更好地与读者互动。
从
3
节点超融合
660
个虚拟桌面;到
4
节点
SDS
上万
VM
模拟测试验证。
本文要点
1
、如何将
VDI
存储
I/O
特征抽象化?
2
、
Full Clone
和
Link Clone
桌面在启动和登录中的不同表现、成因分析
3
、为什么说全闪存
VDI
系统,带宽可能成为瓶颈?
接上篇:《
4
节点近
160
万
IOPS
:
SDS/
超融合测试不能只看数字
》
《
12
万邮箱
ESRP
测试:
Exchange
超融合存储设计漫谈
》
继基础性能、
SQL Server I/O
模拟和邮件服务器
BenchMark
之后,本文将向大家介绍微软
S2D
(
Storage Spaces Direct
)在
VDI
桌面虚拟化应用中的测试表现。
首先我们将引用一份
Dell HCI
参考架构文档中的测试结果,然后再来介绍自己的测试内容。
Login VSI
测试:每节点
220
桌面的超融合
下图来自《
Dell EMC Storage SpacesDirect (S2D) Ready Nodes for Microsoft Remote Desktop Services (RDS) –Reference Architecture
》
链接:
http://en.community.dell.com/techcenter/extras/m/white_papers/20444551/download
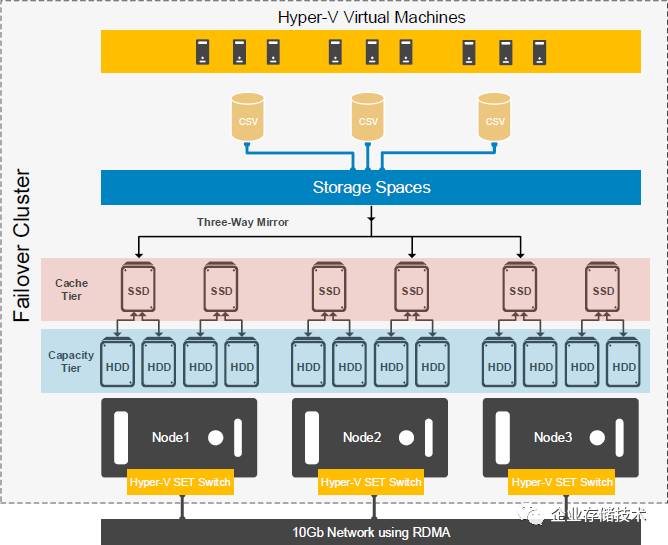
这是一套
3
节点
的
Windows Server2016 DataCenter
超融合集群,存储部分用
OS
自带的
S2D
组建
SSD+HDD
混合存储池
。每节点有
2
个
SSD
用于
Cache
分层、
4
个
HDD
作为容量分层,
3
副本镜像保护。节点间使用
10GbRDMA
万兆以太网互连。

HCI
参考架构中测试的硬件配置
这里的
S2D Ready Node
“
B5
”配置使用了
Dell PowerEdge R740xd
服务器,
CPU
为
Xeon SP 5120 Gold
。
Mellanox ConnectX-4 Lx
或
QLogic 41262
网卡支持
25GbE
,不过环境使用的交换机是
Dell S4048
万兆和
S3048
千兆,可能因为
新一代
25G
交换机
还没有正式上市销售。
由于我们自己测试的网络环境是“不差钱”的
100Gb/s RDMA
,有读者朋友关心与
10/25Gb
之间的性能差别。其实大家不难计算出
2
个
SATA SSD Cache
盘的最大带宽——我认为
大多数混合配置下
10Gb
应该够用了;而若是用
NVMe SSD
做
Cache
或者全闪存的
S2D
,有条件情况下推荐用
25G
或以上
的网络互连。
当然,大家要注意微软
S2D
在
RDMA
下的表现会好不少,这方面我在第一篇中列出过对比数字。
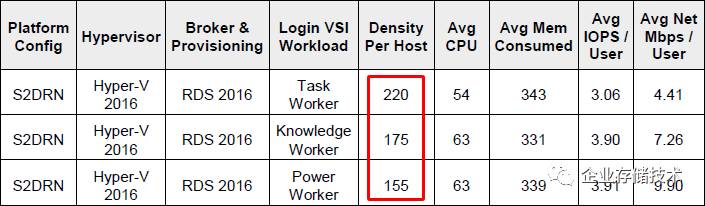
这里的每主机桌面密度,与服务器
CPU
和内存配置直接相关
Login VSI
测试验证了
3
种不同负载的虚拟桌面,平均每节点能够承载的
VM
数量分别为
Task Worker
——
220
个、
Knowledge Worker
——
175
个和
Power Worker
——
155
个,那么从
3
节点超融合集群的角度就应该乘以
3
。
按照这个结果,我觉得
Hyper-V 2016 + RDS
的效率还不错,物理机上的内存消耗都超过了
300GB
,达到稳态后的每用户平均
IOPS
在
3.xx
。
注:
VDI
不同的桌面分配方式,
完整克隆、链接克隆持久化桌面,以及即时克隆
/RDS
产生的存储压力和
IO
模型也不同
,这一点后面我们还会重点谈。
显然在超融合架构下
S2D
分布式存储软件还远未达到瓶颈,即使你换成全
SSD
,服务器上的
CPU
和内存仍然限制着承载的桌面数量。
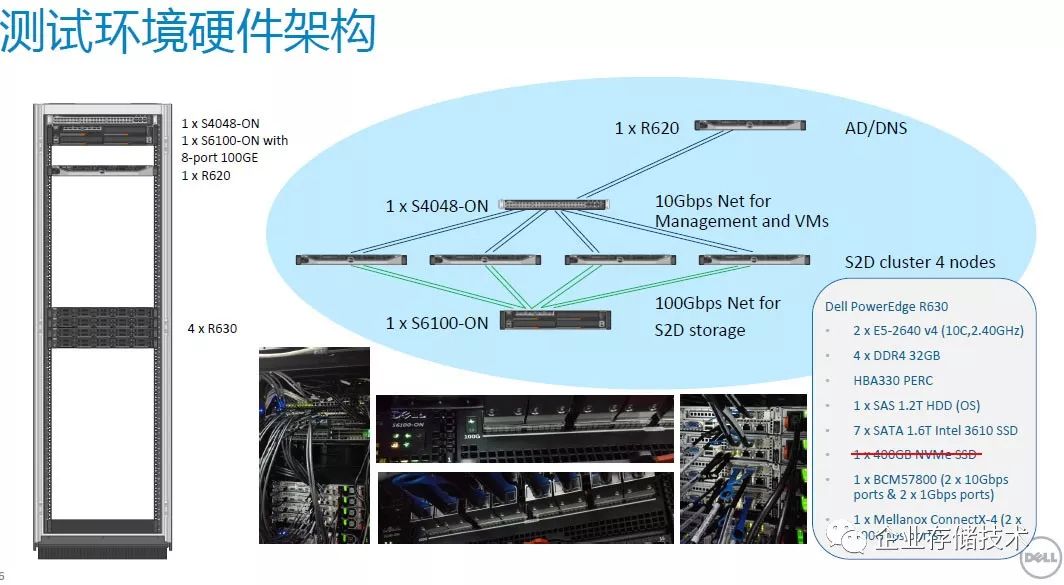
本次测试环境,还是上海戴尔客户解决方案中心(
CSC
)的微软
S2D
(
Storage Spaces Direct
)集群,部署在
4
台
Dell PowerEdge R630
服务器上,每个节点
7
块
1.6TB SATA SSD
,网络互连为
100Gb/sRoCE
。
如果想跑更多虚拟桌面的
Login VSI
测试,几乎只能增加服务器。比如我看到一份
2000
桌面的测试报告中就使用了
16
个服务器节点,以此类推
…
本次我们自己的测试(如上图
4
节点
S2D
集群)也面临同样问题,能否把
VDI
测试中的存储
I/O
负载单独剥离出来呢?直到我看到一份来自
NetApp
的文档。
VDI
启动风暴、登录阶段存储
I/O
“抽象化”
这一段的内容引用自《
NetApp All Flash FASSolution for Persistent Desktops with VMware Horizon View
》(
tr-4540
),可能也是因为跑虚拟机的服务器数量不够多,在该测试报告的结尾处列出了
Login VSI
测试过程中从
Hypervisor
层面收集、统计出的存储
I/O
负载模型
。
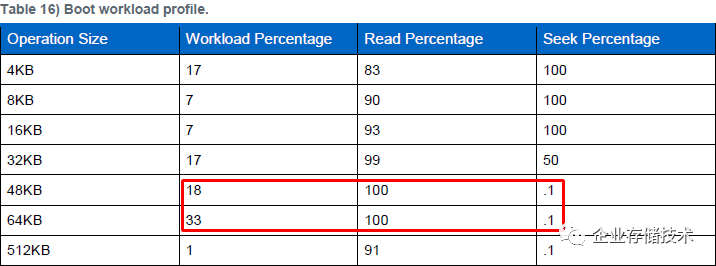
该模型仅针对
Full Clone
(完整克隆)
VDI
部署,下文中相同。如果是
Link Clone
(链接克隆)
I/O
特征将有所不同。
我们知道,启动风暴(
Boot Strom
)和虚拟桌面集中登录是
VDI
应用中最考验存储性能,也是最容易影响用户体验的地方,所以被公认为
Login VSI
测试中的重点。
如上图,在
虚拟桌面
OS
启动过程中存储读操作的比例相当大
,其中最主要的一部分是较大数据块(
64KB
、
48KB
)顺序读,然后是
32KB
读和
4K
随机
I/O
等。
NetApp
获取这个负载模型的目的是
验证更多存储系统
,既然
N
厂授人以渔,我们也拿该方法评估下微软
S2D
集群。当然大家都不会用到那么多的虚拟机,本身这个测试的目的就是要避开服务器的
CPU
和内存瓶颈。
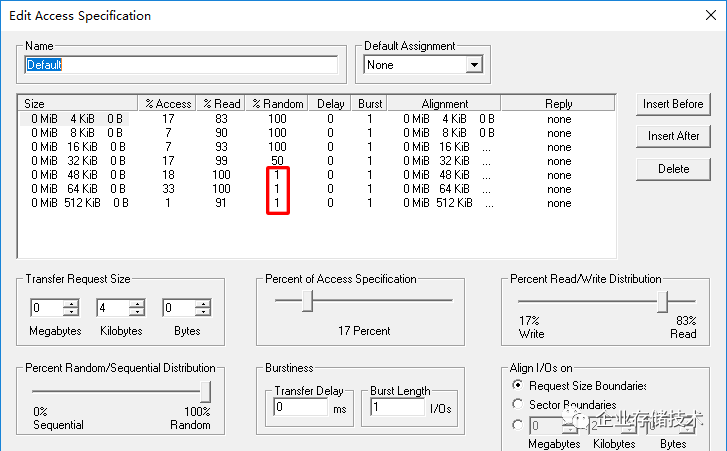
使用
Iometer
在这里有一点小限制,就是随机
/
顺序访问的比率精确不到
0.1%
,所以我们将对应几项的
Random I/O
比率提高到
1%
,实际测得的结果估计会比参考模型略低一点吧。
N
厂使用的测试工具为
VDBench
,由于我们这次是
Windows2016 Hyper-V
环境,为方便起见选择了
Iometer
。而经过简单比较,两种压力工具测出的性能基本一致。
当并发启动数千个桌面时存储压力确实很大,不过我看到有同行朋友说
Boot Storm
可以提前或者分批进行
(比如设定在晚上或者周末重启)也是一种办法。另外虚拟机通常不用每天都重启,下班或者不用时可以注销,所以许多时候
VDI
批量登录
(包括
Windows
或者还有
Office
等启动)的速度
对用户影响更为直接
,这大概就是“
Login VSI
”命名的由来吧:)
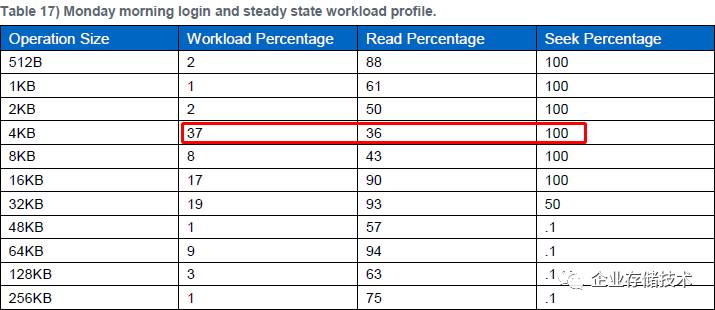
所谓周一上午(
Monday morning
)就是
第一次登录
,这里面比例最大的一项是
4KB
随机
I/O
,读只占
36%
了。当然
16KB
和
32KB
读
I/O
也还不少。
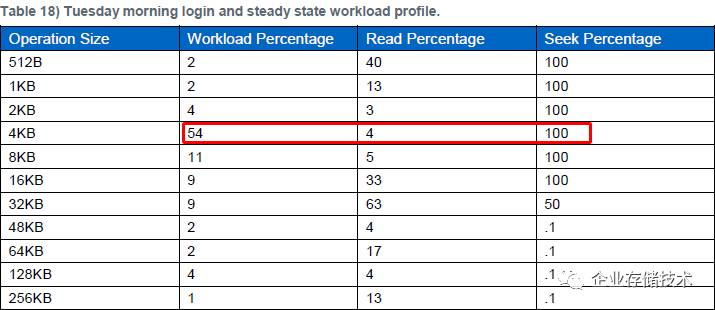
前面说过虚拟机通常不需要每天重启,所以在
周二(
Tuesday
)及接下来几天登录时,大部分需要读的数据已经在服务器内存里了
,这时
4KB
随机写
操作占据了所有存储
I/O
的一半。
下面我们来看看
N
厂的
1,500
桌面
Login VSI
基准测试结果。传统存储和
SDS
有各自的特点及适用场景,我们本意也是以此作为参考而非比较,所以为了避免不必要的争议,以下统一称之为“参考平台”并尽量淡化品牌型号。
Full Clone
和
Link Clone
在
VDI
启动和登录中的不同表现
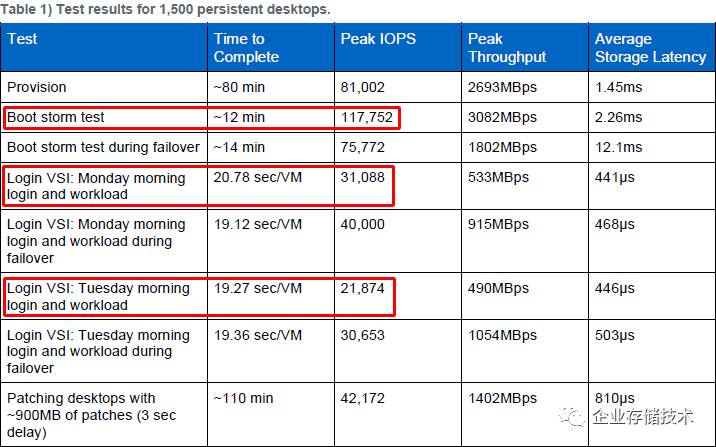
上面这个表信息量有点大,咱们挑重点的说。首先,启动风暴期间峰值
IOPS
超过
11
万,平均每个虚机高达
78.5
,
Full Clone
桌面的测试完成时间约
12
分钟。根据我看到的另一份
4,000
桌面
Login VSI
测试报告,
Link Clone
在峰值
10
万
IOPS
下不到
7
分钟就可以完成启动。
这个背后的原因应该是
黄金镜像(
Golden Image
)的数据更容易被内存缓冲,所以链接克隆在启动风暴中每桌面的
IO
压力小很多
。
然后再看周一(首次)和周二(后续)登录测试,按照峰值
IOPS
推算每个虚机平均
20.7
和
14.6 IOPS
(我们的评估也是以此为基准),每虚机的登录时间都在
20
秒左右。
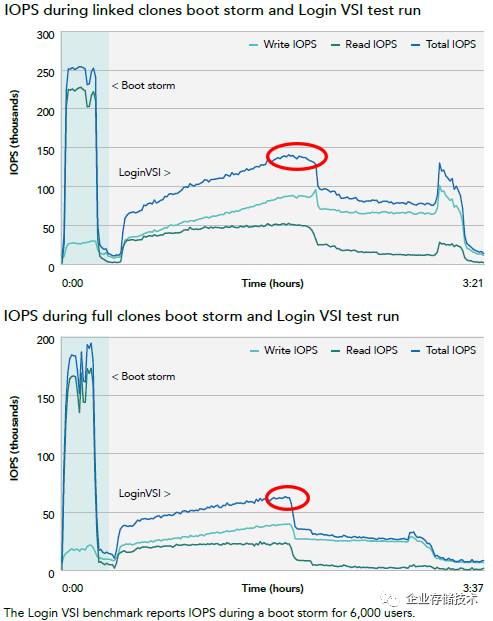
而根据我看到的另一份
Login VSI
报告,全闪存阵列在
6,000
用户测试中,
链接克隆桌面在登录阶段产生的峰值
IOPS
要比完整克隆高出一倍多。估计是磁盘碎片化导致连续数据的分布被打散,同样数据量的访问需要更多次
I/O
。所以我觉得两种磁盘分配方式应该区别对待,测试成绩不应混在一起做横向对比。
全闪存
VDI
系统容易被忽略的带宽瓶颈
下面是我们在微软
S2D
集群上的测试结果。
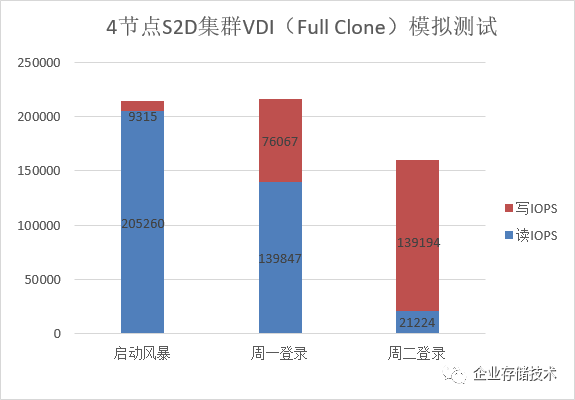
首先看
IOPS
,模拟启动风暴测试读写总和超过
21
万,大约是上文中参考系统(
Full Clone 1,500
桌面)峰值的
2
倍。可以预见的是,如果只考量这套
S2D
集群的存储性能,换成
Link Clone
的话能支持的桌面数量远不只
3,000
个。
模拟第一次登录测试也超过了
21
万
IOPS
,约为参考系统的
7
倍;后续登录测试达到
16
万
IOPS
,而这里列出的还不是我们看到的峰值。
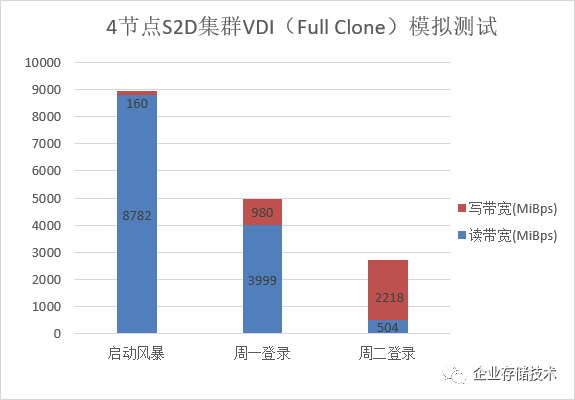
进一步分析带宽,我们发现启动风暴时达到了
9GB/s
左右,距离第一篇评测中的
S2D
集群顺序读最大带宽(见下图)已经相距不远。周二登录也是个典型代表,仅写入带宽部分就超过了
2.2GB/s
,我们的
S2D
是
3
副本配置。
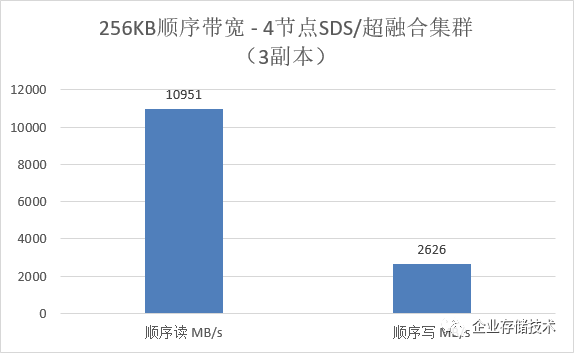
由此我们认为,对于全闪存系统来说,
VDI
应用的存储瓶颈有可能出现在
SSD
及其接口带宽上
。如果换
NVMe Flash
那效果自不必说了:)
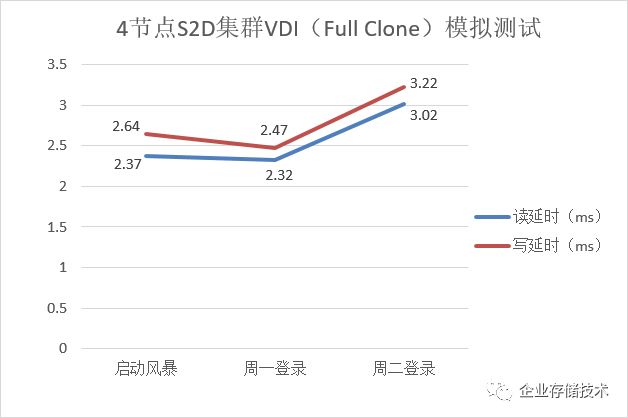
注:上表中数字为虚拟机内记录的满负载下延时
这个延时结果(毫秒)要是对比现有的
Login VSI
报告看似不太漂亮,不过别忘了
我们模拟的是峰值性能,也就是说实际
VDI
测试过程中平均延时会低不少
。
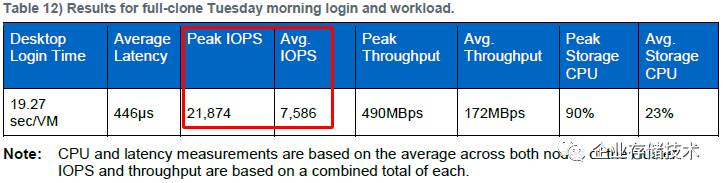
看看参考系统的平均
IOPS
和平均延时测试值,我们不难估计出峰值
IOPS
时对应的延时范围吧?
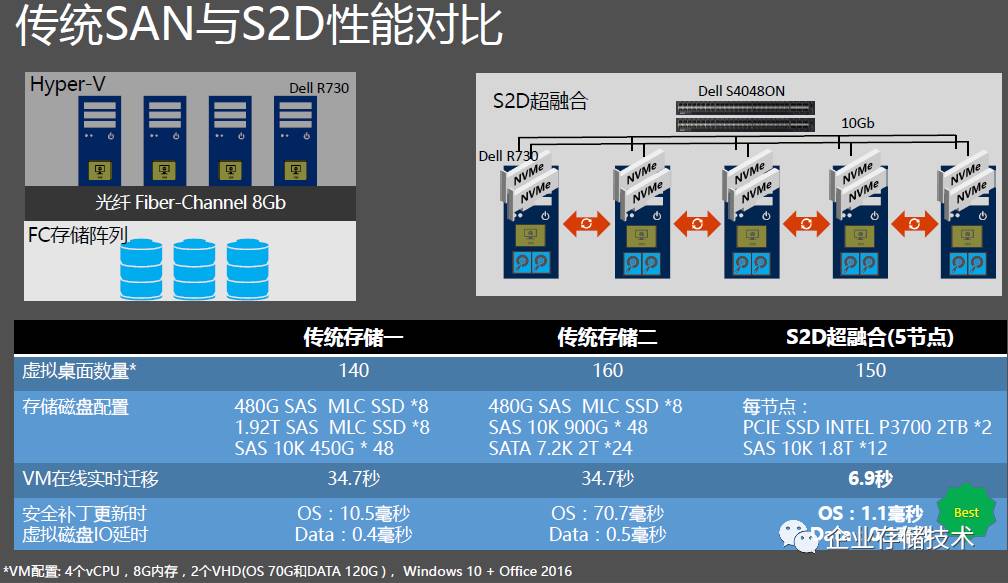
上图引用自
Microsoft Tech Summit 2017
大会上分享的一页
PPT
,对比
FC
存储和
S2D
在每月第二周
WnidowsUpdate
大规模补丁更新时产生的
IO
压力,从数据中看出
S2D
的
IO
性能是最好的。其中列出的测试数据是在实际生产环境中获得,供大家参考。

同时我们拿到更进一步的对比数据(都是
SSD+HDD
混合配置):在虚拟机在线实时迁移上,
S2D
超融合因为具备
RDMA
网卡,所以
VM
迁移性能是之前的
5
倍。更重要的是虚拟机启动风暴的
IOPS
性能和平均延时对比,
S2D
也是大比例领先。
150
个桌面,
S2D
超融合大约
10
分钟能全部启动完成;而传统存储大约需要
40
分钟才能全部启动完成
160
个桌面。
S2D
超融合的低延时和高
IOPS
给用户非常好的使用体验。
为什么看重“周二上午登录”?
我们的测试只进行到周二登录,其实周三到周五也是类似的情况。我理解数据中心的服务器不会随便关机,所以
VDI
持久桌面用户每周重启一次
Windows
系统的应该占较大比例
。在我们参考的文档中,
N
厂就是以“周二上午登录”的模拟测试结果,来评估不同存储系统能支持的
VDI
桌面数量。
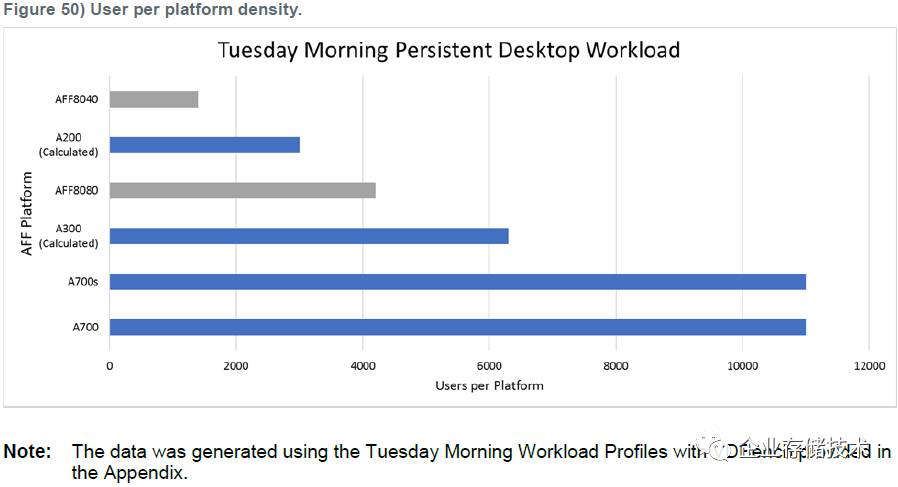
如上面图表,测试结果最高的一款全闪存阵列接近参考系统
IOPS
的
8
倍,所以在这里被判定能够支持到
11,000
个虚拟桌面。

VDI
周二登录模拟测试
上图是我们的
S2D
集群,在周二登录的模拟测试中,于
Windows Server 2016
物理机
OS
的监控截图,可能还不是最高峰值的时候。
如果按照这个
176,242 IOPS
来计算,已经
达到
1,500
桌面参考系统的
8
倍
,那么该
4
节点
S2D
配置是不是可以支撑
12,000
虚拟桌面
VDI
的存储负载呢?

VDI
周一(首次)登录模拟测试
由于启动风暴压力可以被规划、分摊在非工作时间,如果是重度
VDI
用户(每天重启一次的),按照上面这张图中的
225,582 IOPS
,其首次登录性能应该也能达到
10,000
以上虚拟桌面
的水平吧。
计算存储分离的
SDS
用于较大规模部署

记得我们在
第一篇评测
中提到过这种
非超融合的“
Hyper-V
集群和
SOFS on S2D
集群分离部署
,应用主机和存储节点通过
SMB3
协议网络连接,依然可以使用
RDMA
。”
虽然理论上
SOFS on S2D
会比集群内访问会多一层开销,但我们本次模拟测试中
Dell R630
服务器的
CPU
还远未成为瓶颈。而这只是
4
节点总共
28
个
SATA SSD
的表现(目前
S2D
最大支持
16
节点),软件定义存储的魅力大概就是如此吧:)
最后,再次感谢上海戴尔客户解决方案中心
Tony Wang
对本次测试的大力支持!
注
:本文只代表作者个人观点,与任何组织机构无关,如有错误和不足之处欢迎在留言中批评指正。
进一步交流
技术
,
可以
加我的
QQ/
微信:
490834312
。如果您想在这个公众号上分享自己的技术干货,也欢迎联系我:)
尊重知识,转载时请保留全文,并包括本行及如下二维码。感谢您的阅读和支持!《企业存储技术》微信公众号:
HL_Storage

长按二维码可直接识别关注
历史文章汇总
:
http://chuansong.me/account/huangliang_storage





