正文

大数据文摘作品,转载要求见文末
作者 | 张皓添@稀牛学院数据科学实训营
Music是永不落伍的话题。
每个人一定都有自己心仪又不单一的音乐风格:rap、古典、流行,那么如何管理自己的歌单呢?难道真的要自己手动一个一个去给歌曲设置类别吗(耗时耗力,真的好累!)?
不如挽起袖子撸一波代码,让AI去替我们完成这些费力不讨好的任务。
人工智能似乎总是与众多或复杂或简单的算法及或深或浅相的数学知识相挂钩,但是好在勤劳的工程师们已经为我们铺好了通天大路,sklearn,tensorflow,caffe等一系列的机器学习框架已经相当的成熟并投入使用。我们也将使用这些开源的框架来完成一次AI流程。
目标:
实现歌曲风格的分类,输入一段歌词,给出所属的分类标签。
工具:
Python、Scrapy、Selenium、PhantomJS、Sklearn、WordCloud、Matplotlib 、jieba。
那么我们给出机器学习的流程图:

一套完整的机器学习模型构架加预测的都是基于这个流程图的。那么我们就根据步骤一步一步来处理我们的问题。
附上教程供各位参考,时常30分钟,无法及时看到视频的读者可以直接下拉看文字版步骤。
我们的目标是对歌曲进行风格的识别,那么最最重要的一问题就是 数据从何而来? 没有数据就没有模型的地基。考虑了几个主流的音乐播放器的平台(网易、QQ、Kugou),选择了歌单分类比较清晰的网易云音乐歌单。使用爬虫去对歌单信息进行摘取。

可以看到风格分类还是蛮多的,那么我们现在要做到的就是在每个分类目录,拿到属于该风格的歌单,再从歌单中获得歌单中所包含的所有歌曲。现在就到了爬虫展现神威的时刻了,我们通过 scrapy 这个框架来实现,那么我们要怎么做恩?
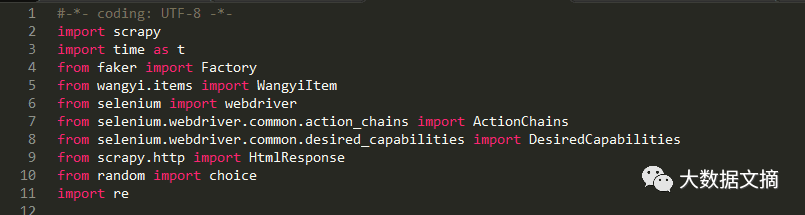
import library
② 对爬虫添加请求头,其中的User-Agent使用faker去模拟。设置起始url。
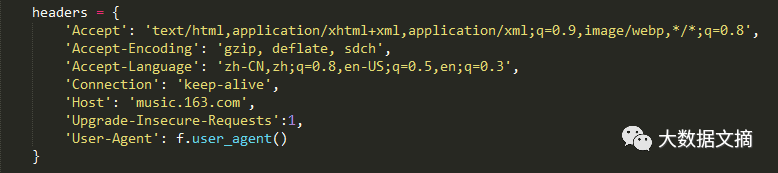 headers
headers

start_urls
③ 现在呢,我们需要的就是获得到底有哪些 分类标签
啊(Tag:流行、爵士...)通过xpath拿到标签的列表,这里我们为了节省爬取的时间只选择了3个标签。分别为 [ 古风,英伦,乡村 ]

解析标签
网易其实对歌单进行了分页操作,也就是说我们在爬取每个分类的时候还要知道在这个分类中的歌单共有多少页,所以接下来要去解析 每一类对应有多少页的歌单 (为了缩小爬取量只用了每个风格5页歌单,每一页包含35个歌单)
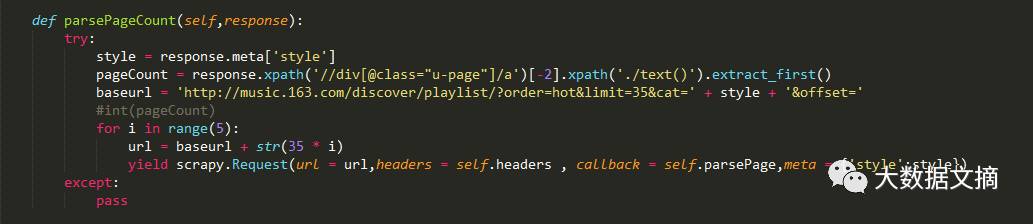
解析页数
我们就需要去遍历这一页的每一个歌单,并且拿到 歌单相应信息。我们需要的信息有 【歌单风格,歌单名字,歌单收藏量】分别为 【style,name,counts】

遍历一页中的每一个歌单
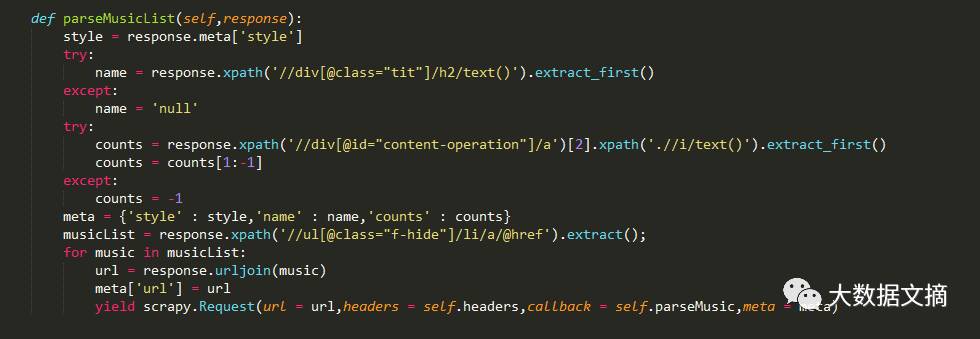
获得歌单信息及包含的歌曲列表,并携带这些信息继续去解析歌曲列表中包含的歌曲
我们现在需要找到每首歌曲中所包含的信息,我们所需要的有【歌曲名字,歌曲歌手,歌词】其中前两个都好办,只有最后一个歌词,是没有办法直接获取到的,因为歌词是动态加载出来的,为了解决这个问题,我们引入[ selenium + phantomJS ] 来模拟浏览器行为,之所以选择phantom是因为他是无界面的浏览器无需渲染,速度更快一些。
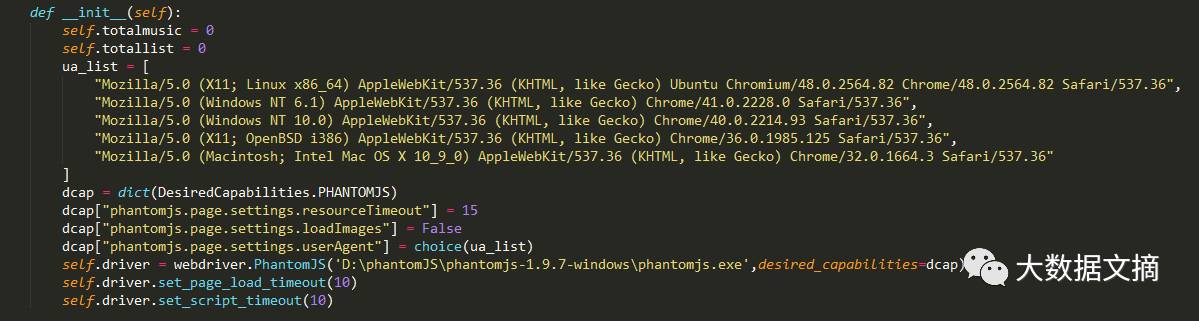
首先在初始化的部分,将PhantomJS的设置初始化。添加headers和timeout。
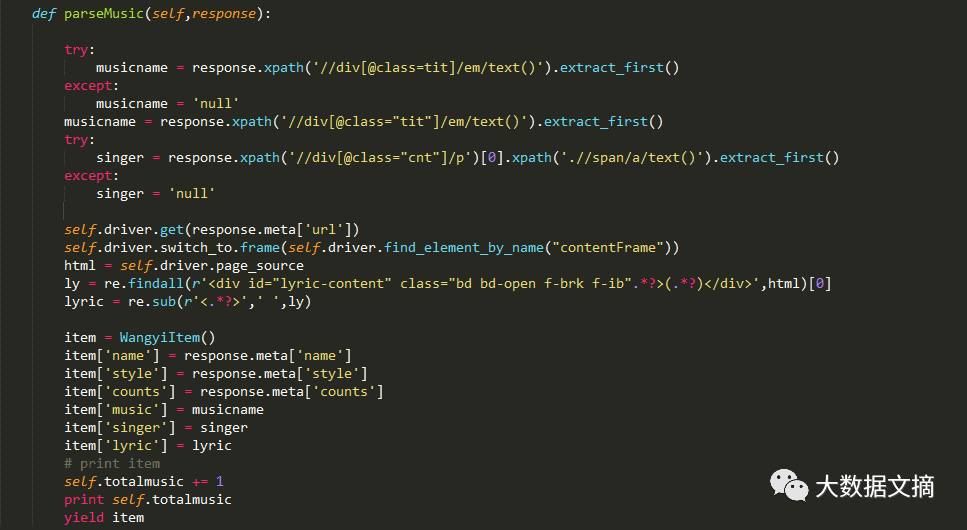
然后在解析每个music的时候,使用PhantomJS来加载歌词界面,并获得到歌词。(由于获得歌词中包含
等这样的Html元素标签,所以通过正则手段去掉)最终将获得到的全部信息通过Pipeline输出到文件。
这样我们数据提取的过程就结束了,我们得到了一个.csv格式的文件输出,其中每一行就是一首歌及该歌曲的相应信息。部分截图如下:

.csv输出文件部分截图
最后我们就可以用这些数据去进行一些可视化绘图,比如不同风格中最受欢迎的歌手,以及每个风格中的Top10歌曲,不同风格中歌单的平均长。
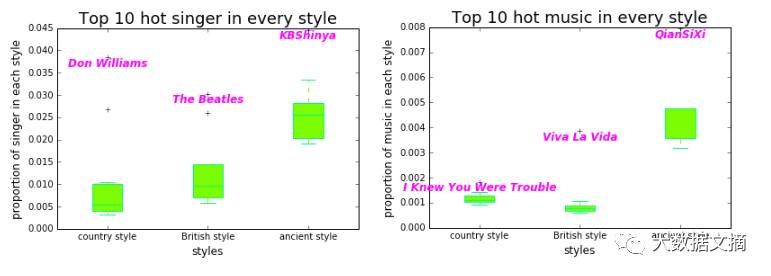
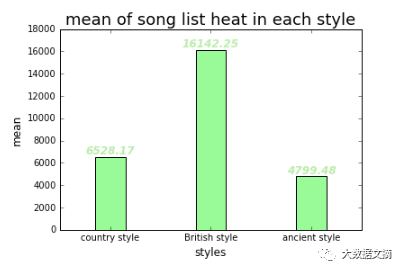
可视化部分
因为提取到数据还是相对完善,并没有出现复杂的数据清洗需求。因此只是简单的对数据做了一次去掉Nan空值的操作。因为我们做风格分类,所以我们考虑使用每一首歌曲的歌词作为特征,因此我们将爬取到的信息中的歌词和风格单提出来,其中歌词作为特征,风格作为标签。基于此构建一个牛逼的分类器,实现我们的风格分类。
通过一些复杂的正则和替换操作,拿到最终的训练数据,格式如下:

训练数据
接下来呢,我们搞个有意思的东西【词云】 我们使用WordCloud 和 jieba 来实现这个小功能。效果图如下:

古风类

英伦类
是不是还足够炫酷的样子!小插曲而已,那么接下来干点正事。我们要去构建模型了
Let us Go!!!
因为分类问题嘛,我们现在只选取其中的2类进行分类,分别为【古风、英伦】。
首先因为数量不一致,会导致分类器的偏向问题,于是我们首先要对2类样本做一个剪裁。让英伦类样本数量大致与古风类样本相同。

样本数据加载并剪裁到数量一致
然后呐,我们需要去掉一些对我们分类起不到作用甚至是有干扰的单词,也就是停用词。
停用词:在信息检索中,为节省存储空间和提高搜索效率,在处理自然语言数据(或文本)之前或之后会自动过滤掉某些字或词,这些字或词即被称为Stop Words(停用词)。这些停用词都是人工输入、非自动化生成的,生成后的停用词会形成一个停用词表。
我们接下来有好多种方法可以用来做这个分类
举个例子:
香蕉,苹果 对应的词义向量的欧氏距离更为相近,而 香蕉 , 轮胎 对应的词义向量的欧氏距离要更远。

我们这里选取了第二种方案,使用word2vec对jieba拆分的单词做词义向量构建,然后将每一首歌的歌词中所包含的单词的词义向量相加并取均值,以这个最终结果向量作为该歌曲歌词的含义向量。并重新构建训练数据和测试数据。
最终,我们使用SVM分类器实现最后的模型分类
在经过SVM拟合后的结果如下:
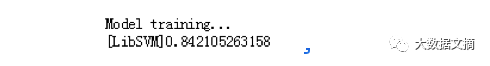
最终训练结果
模型证实我们的分类效能有84%左右。我们仍然可以通过调参的方式去改进模型,提高准确率,这里不再提及。接下来我们可是要迫不及待的去检验一下成果了!








