
解放您的双眼,扫码听在线课堂

作者简介:

曾彬
阿里巴巴 高级技术专家
互联网老兵
,
十多年的基础架构经验
,
曾在支付宝、爱立信、魅族等担任系统架构师,从事过
Linux
内核开发,
Java
中间件、
SOA
应用框架的设计实现、云平台设计实现等工作,技术涉猎广,在非功能性基础架构与实施
,
性能调优等方面经验丰富
,
曾整体负责魅族云平台的架构设计与实现及运维工作。
前言
魅族容器云平台主要是基于
k8s
的技术。将从以下六个方面介绍魅族容器云的实践过程,分别是基本介绍、
k8s
集群、容器网络、外部访问
4/7
层负载均衡、监控
/
告警
/
日志、业务发布
/
镜像
/
多机房
。
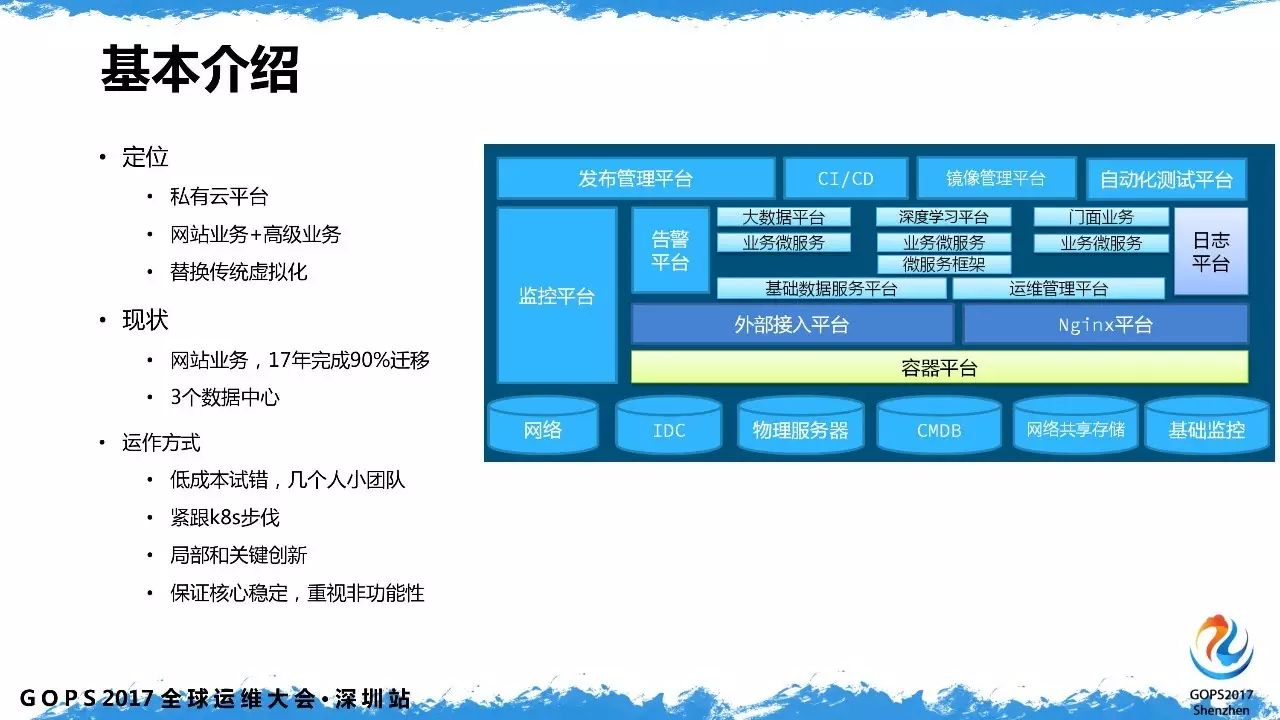
1、基本介绍
魅族云平台的定位是私有云平台,主要是用于支撑在线业务,用以替换传统的虚拟化方式。目前现状是2017年完成全国三个数据中心的建设,年内完成 90%业务的迁移。
我们是以小团队紧跟 k8s 社区步伐,快速迭代、低成本试错的方式来构建我们的平台的。同时,针对一些我们遇到的问题,做一些局部创新,在保证系统核心的随社区稳定升级的前提下,解决好非功能性问题。
2、k8s 集群
对于 k8s 集群构建,将从 k8s 的单一镜像、k8s 集群 master、minion 三个方面分别展开介绍。
2.1 单一镜像
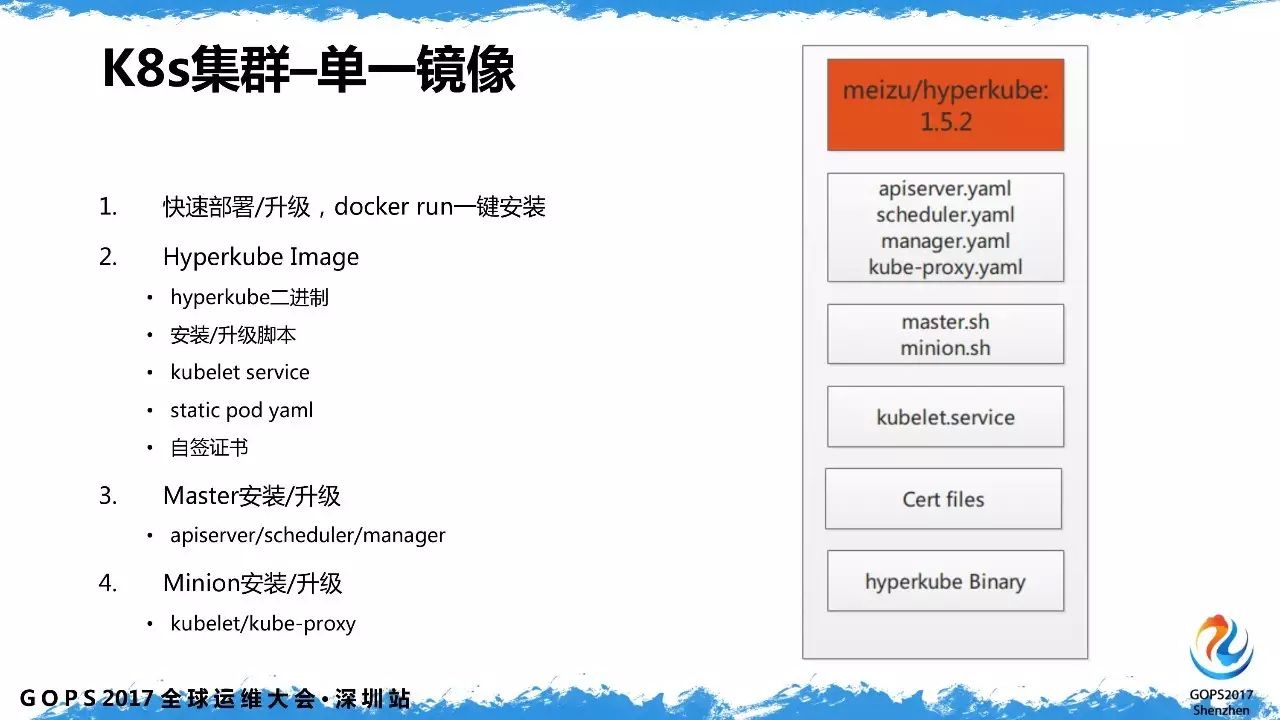
k8s
集群的安装部署是利用单一镜像
+ docker run
实现一键安装。为此将所有
k8s
相关的描述文件、脚本和二进制全部打包成镜像,目的是实现集群的快速部署和升级。
2.2 Master

为了能够实现自动加载,
k8s
集群核心组件使用了
Static Pod
方式。在自动修复方面,
kubelet probe
可以实现
Pod
的自检,配置了自动重启。如果需要对核心组件进行升级,指定统一镜像的版本号即可实现核心组件升级更新。
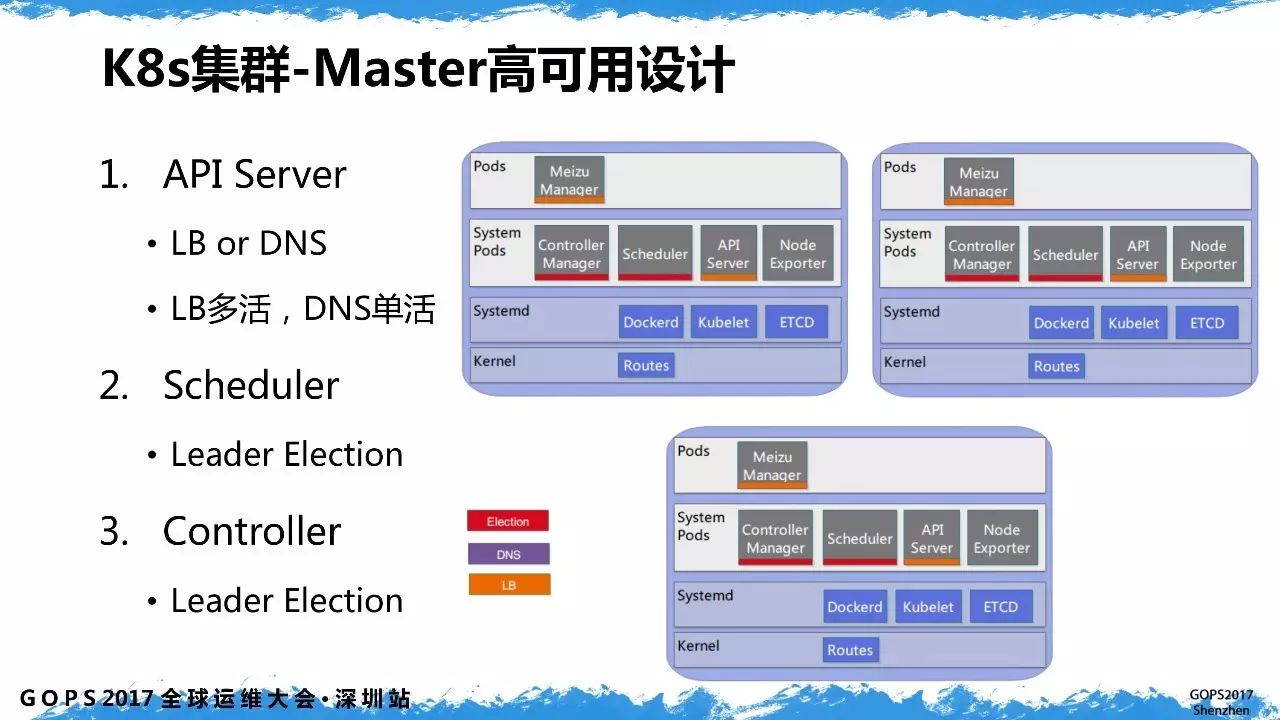
controller manager
和
scheduler
服务在三台物理机实现集群
master
高可用。
API Server
的高可用既可以通过负载均衡方式实现,也能通过
DNS
方式实现。

集群
controller mananger
重启可能会出现
Node
状态不同步的问题,因此对于核心组件状态,需要配置告警并及时检查有无异常状态。
2.3 minion
硬件方面并没有固定的配置,尽量利用现有的资源。在我们的集群中,常见
minion
的配置是
24
核
CPU(with ht)
、
128GB
内存以及千兆网卡。

k8s 集群中 minion 作为计算节点,其上主要是各种业务的容器和 Systempods。
对于 minion 节点做了三个方面参数的优化,中断相关、TCPbacklog 和 swap。

minion 节点操作系统使用的是 centos 7,docker storage 使用的 devicemapper driver,日志基本写到外挂的 EmptyDir volume,docker 存储使用得很少。
我们为
EmptyDir Volume
专门开辟了普通分区,没有使用
lvm
,因为日志量不好预估,遭遇过因为
lvm metadata
的事故
。

使用
Device Mapper
还遭遇过
kernel issue
,因此需要更新内核。
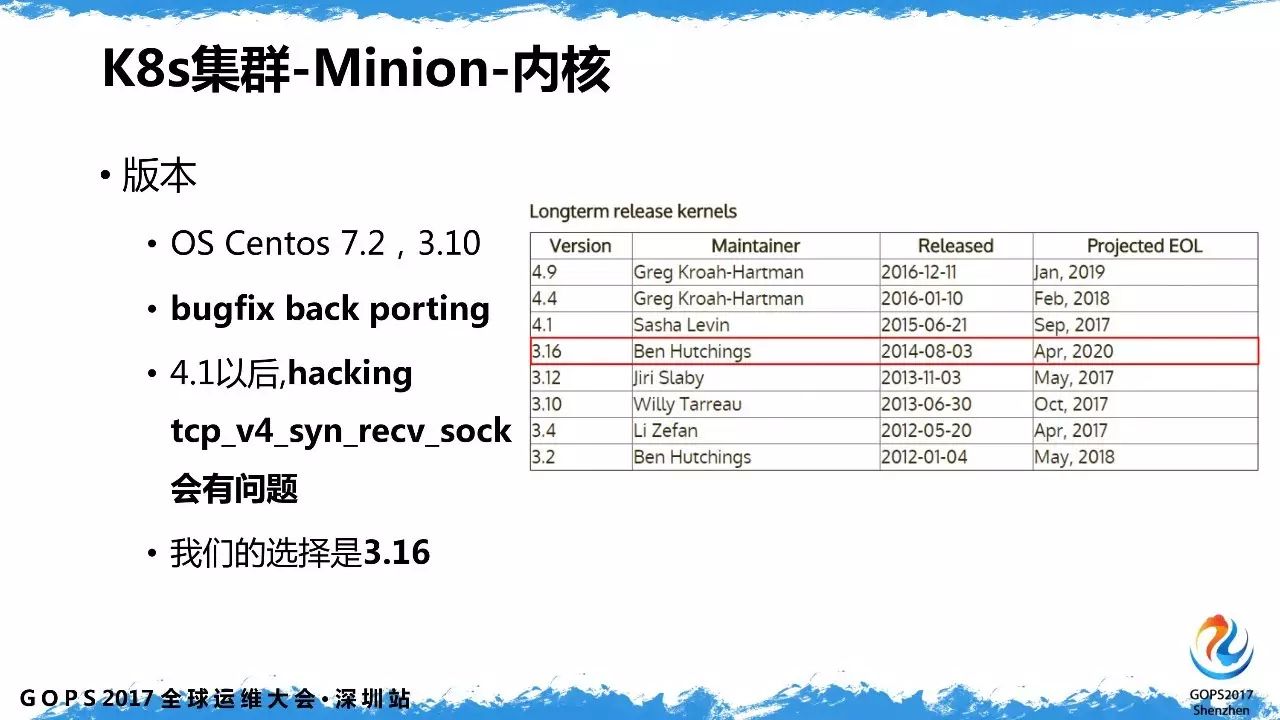
默认内核是
3.10
版本,长期维护的内核版本的是我们需要的。而且考虑到要对某些内核模块做
hacking
,
4.0
及以上变化较大,
hackingtcp_v4_syn_recv_sock
存在问题,所以我们最终选择了自行编译
3.16
内核。

考虑到和
CMDB
的结合,
minion
节点打上了
Label
,例如标记它的功能是什么,物理位置信息
,
机柜等。这些信息对于
Pod
调度非常重要。包括
Pod
的
Node
亲和性,
Pod
亲和性和反亲和性。
3、容器网络
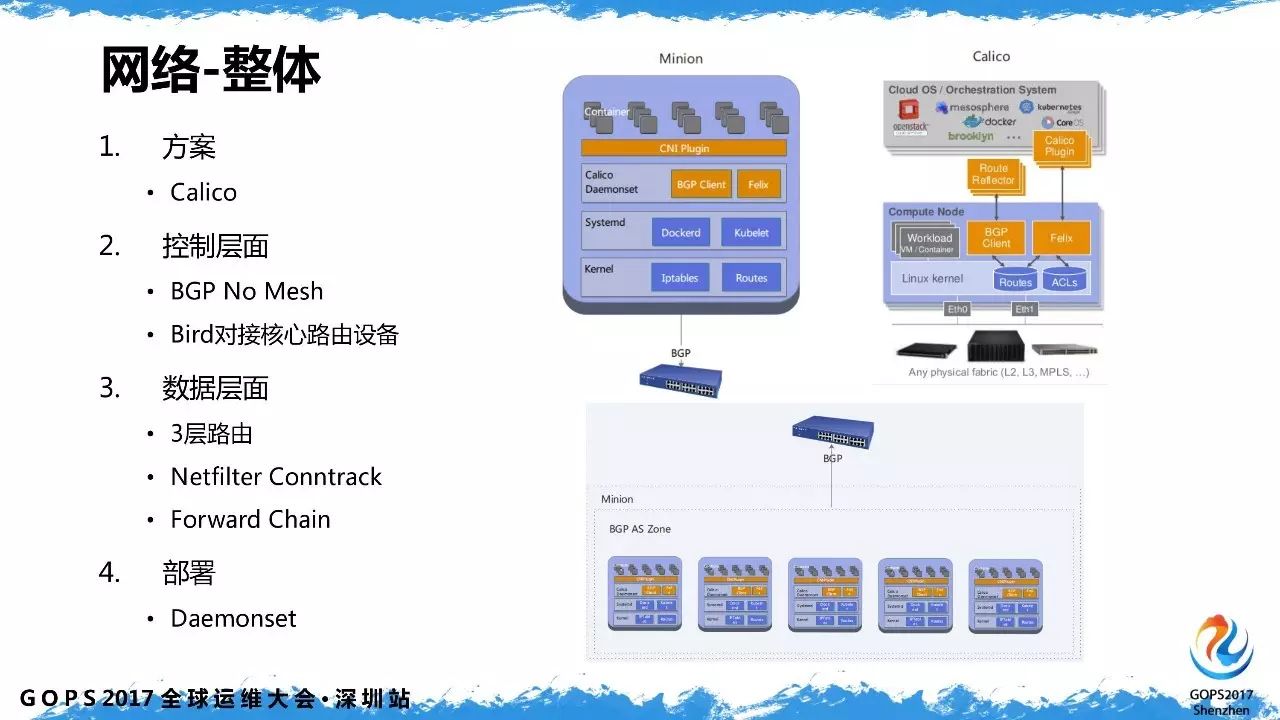
容器网络的方面我们采用的是 calico 的方案。主机通过 BGP 直接和核心路由设备对接,这里也可以用 RouteReflector 替代。
控制层面走
BGP
,数据层面走三层路由。网络封包会经过主机的
netfilter
框架
,
最后经由主机
forward chain
进入容器,默认都会被
conntrack
。部署方面,
Calico
通过
k8s
的
Daemonset
方式,部署非常方便

优化主要是针对
conntrack
,建议尽量使用
headless service
,少产生
iptables rule
。同时,对
conntrack
用量进行监控。容错方面,容器会主动去
ping
交换机,确保网络的连通性。当
calico
出现问题的时候,容器是不会加入服务的,由此来保证服务的可靠性。
 对于我们系统,绝大部分流量来自外部
LVS
,其可信任度高,默认的方式会产生大量的
conntrack
记录,所以应当把
LVS
过来的流量直接给
bypass conntrack
。
对于我们系统,绝大部分流量来自外部
LVS
,其可信任度高,默认的方式会产生大量的
conntrack
记录,所以应当把
LVS
过来的流量直接给
bypass conntrack
。
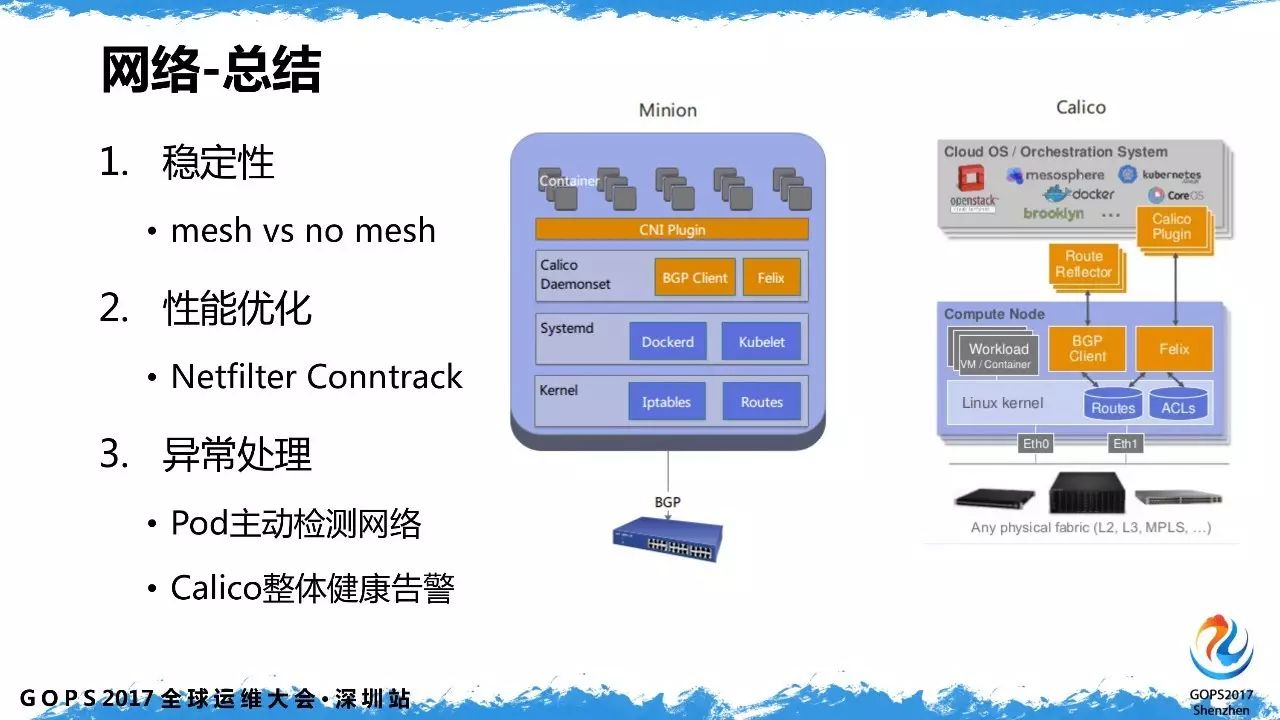
经过生产实践效果验证,
no mesh
模式的稳定性要优于
mesh
模式。异常处理主要分为
POD
主动检测网络和
calico
的整体健康监控告警。
4、外部访问4/7层负载均衡
我们做的是对外服务,大部分流量都是从外部打进来的,终端用户都是外部的客户,所以针对外部的访问做了4层和7层的负载均衡。我们做的是对外服务,大部分流量都是从外部打进来的,终端用户都是外部的客户,所以针对外部的访问做了4层和7层的负载均衡。
4.1 4层负载均衡
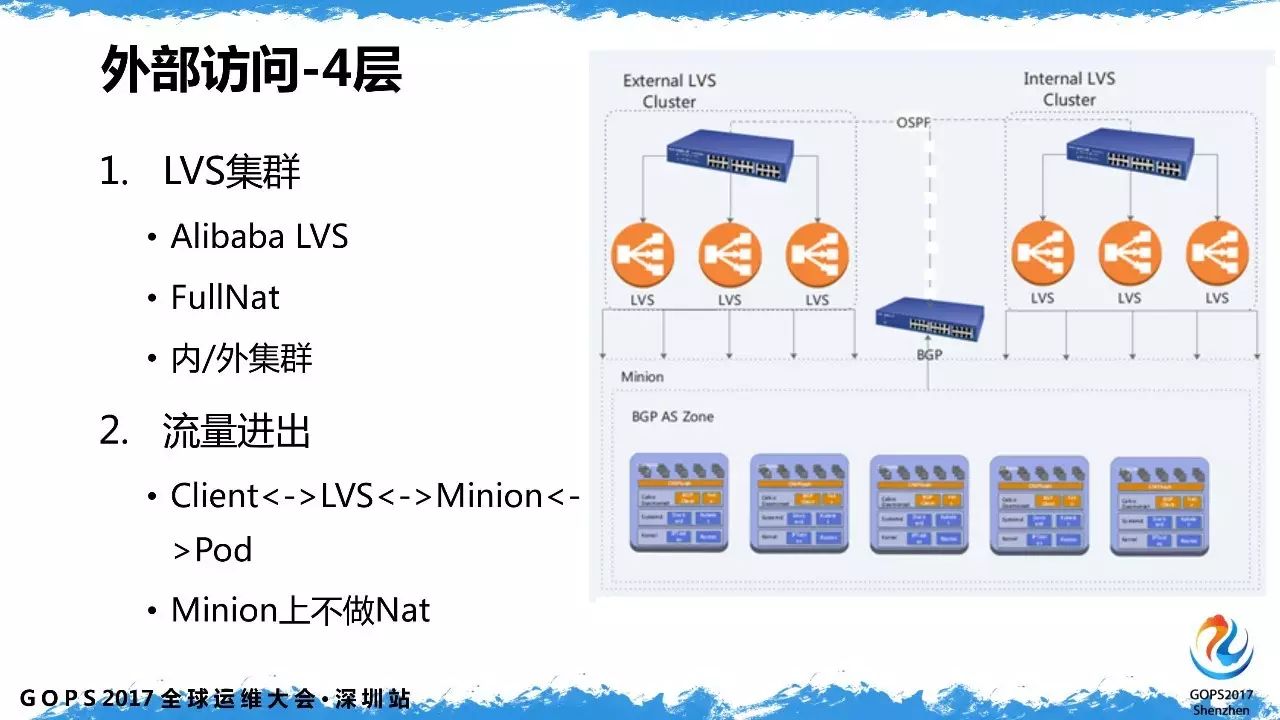
在
4
层接入上采用了是阿里开源的
Fullnat LVS
方案,看中了它运维方便、水平扩展性好。工作在
4
层的
LVS
服务既可以支持
TCP
同时也支持
UDP
,流量从
client
端经过
LVS
做
Fullnat
后到达
minion
,应答直接路由回对应的
LVS
。

对于
4
层负载均衡的配置,是通过自动化方式来实现的,无需人工配置,可以自动在路由设备宣告




