数十万互联网从业者的共同关注!
作者:KEVIN,作者授权早读课转载。
来源:Kevin改变世界的点滴(ID:Kevingbsjddd)
编辑:早读堂-刘小妹
 UGC的核心—FEED
UGC的核心—FEED
由于工作原因,近期正在负责公司产品UGC模块设计,尤其是经过需求的开发挑战、BOSS挑战,产品经过一轮评审、二轮评审之后,产品的需求逐渐落地下来。最近在负责产品UGC模块,以及FEED的相关算法
UGC社区,无论是在PC端还是移动端,其最重要的就是信息流展示,其信息流的展示方式和排序方式是我在调研的重点,这里提出广场、热门两个概念,可作为覆盖UGC模块的基本属性模块。
提到UGC模块,产品经理在进行落地设计首先需要考虑的是用户的社交关系,这一点在不同产品中,有弱、有强的倾向;
产品经理在进行UGC模块设计之前,首先搞清楚其产品用户社交关系、以及产品社交定位的强度
大多数UGC的分类,都会将UGC进行内容以用户角度与平台角度分类,推出相应内容,当然在如今的智能个性化推荐中,平台还是既能够保证平台需要曝光的内容进行展出,也需要曝光的内容是用户需要的内容。

【平台内容的分类】
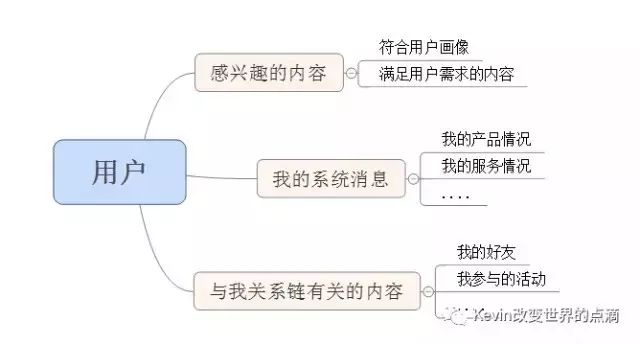
【用户内容】
平台与用户如何达到一个共节点,这是PM设计UGC中FEED流的关键,什么是FEED?做PM的朋友可以自己百度,这里我就不详细解释了。
这里提出一个内容源概念,在UGC设计中,在当前社区或论坛的模块中,其信息的来源有那些?将系统、运营人员、用户的三种角色的内容进行区分,我们可以将FEED的内容进行罗列

【FEED内容源】
为此,FEED的内容源头我们将其区分,有利于我们进行对不同的内容进行设计,其核心字段是什么?运营的每个内容源核心字段?用户内容的行为操作所产生的内容源字段是什么?
这样的最后结果可以将FEED的有效性与区分达到用户可识别的效果,这里以QQ他们将平台类不同的内容源进行设计,达到内容的有效性散播与增强用户区分性

【视频类】

【签到类】

【系统类】
QQ将系统内容、用户内容、用户签到行为的内容进行区分,毫无疑问将内容的有效性大大提供,每个FEED的核心字段进行提取,方便了运营与用户的玩法。
FEED的内容源与区分既然上面说了,下面就是FEED的集中展示了,这里我以常见的广场与热门来举例
广场:所有消息的集合,系统、运营、用户消息集合(常见的),(不排除因产品定位不同,有将系统、运营、用户消息部分过滤)
热门:根据算法将热门的内容以热门从高——低进行排序,或以用户活跃进行排序等(将特点权重的属性进行排序)
【广场舞APP中最新发布与热门】
因此FEED的分类,需要注意的是在不同的分类其涉及的算法就不同,或者以同一个算法满足所有分类,其最简单粗暴的就是目前热门的智能推荐系统,不管你是那个版块,FEED的分类是怎么样,都可以尽可能的去推荐,满足让用户看到他需要的内容。

【热门与关注】
这里要提出的是一个UGC中,基于用户的生态与平台生态,这一点也是FEED的推送中算考虑中权重占比高的2点思考点。
平台的生态也就是针对于产品中的模块关联性与平台中所提供的产品关联,这一点产品经理需要考虑相关的产品是什么?相关的功能模块是什么?
以UGC模块为例,其典型的案例就是群聊与社区的模块是关联的;
以证券类产品来说,其锦囊与观点的产品线是相同的;

【模块的关联与产品的关联】
这里需要重点说明的,其模块的关联与产品的关联,产品经理往往一个人没办法全局打量,建议和几个产品经理或LEADER一起脑暴一次,将所有可能会存在的关联点进行列举,这样才能保证FEED流能够流到各个地方。
每一个路径就是FEED流可能流动的地方,其能流动的地方都会有用户存在,仅能可能满足用户的所有对FEED的需求,除了依靠算法,其产品的关联与生态尤为重要。
FEED的功能关联,这里说一下,如果有数据体系支撑,建议通过将模块、产品建立在数据漏斗、热力图进行分析,用数据驱动,会帮助产品人 少走一些弯路。
之前更新过:产品数据的一些坑,可以学习
这里就是本次分享的重点,FEED流的算法和设计落地,在这里首先抛出几个FEED流典型的产品体系和算法以及2个关键词
UGC产品体系:强社交体系、弱社交体系
算法:重力排序法、时间排序法、智能推荐排序法(概述)
关键词:未读池、FEED存储区
1.强社交体系
强社交体系的UGC社区,就是目前最典型的以微信朋友圈为代表,其微信的社交关系建立在用户与朋友之间的链接,因此微信的内容为UGC的代表,微信的FEED方法就是以时间排序法,并且微信将每时每刻中,自己的好友圈所生成的FEED,都将刷新出来。关注的好友没有权重,时间线成了唯一标准。
2.若社交体系
若社交体系的UGC社区,这里我们以微博来举例。微博因内容涵盖好友与非好友,在此对于用户的社交圈中,就属于若社交体系。并不强调用户与好友之间的关系,而是强调用户与用户的关系,微博这里就涉及用了FEED存储区、FEED未读池,并且微博的UGC经历了重力排序法到目前的智能推荐排序法的一个过渡过程。
3.时间排序法外的2个算法
重力排序法
重力排序法,在做公司UGC模块中,我在网上查了不少相关的文档,其中网上对于这一块的算法参考资料较少,因此在学习以及自我建立过程中,我将重力排序法以案例的方式进行讲解
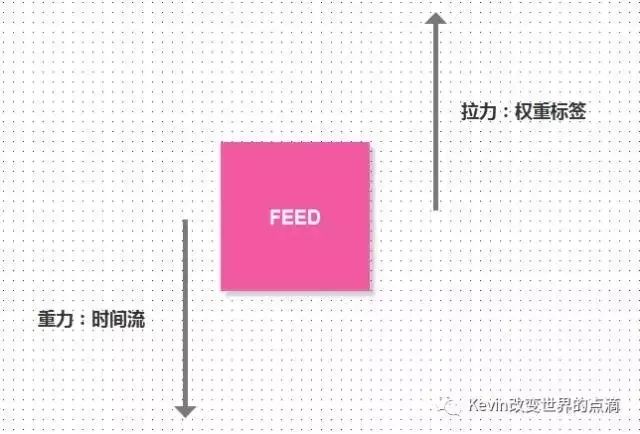
【重力排序法】
首先重力排序法还是依靠时间进行FEED拉去,在这里根据时间的从近到远,依次将FEED进行拉去展示,这就是重力;权重标签,这里可以是指的是FEED的权重标签,可以是内容的、也可以是针对产生FEED的对象;
比如针对内容:点赞、阅读、转发...
比如针对对象:关注好友、好友活跃度、好友粉丝度排序
重力排序法的意义:
因此重力排序法是基于时间的算法,尽可能的将有效的内容展现给予用户,让用户能够去得到需求或平台高质量的内容,并且还是依据时间流的顺序,不会让用户产生无厘头的感觉,并且不是全是系统消息、无效的消息。但重力排序法需要给予一个时间存储段,为什么要这样做?这里在下面FEED存储区我会说明。
智能推荐系统(概述)
针对于智能推荐,可以说是目前每个高用户UGC社区都想做的一块算法,其解决的核心问题是:在平台中将用户所需要的内容推荐给予用户
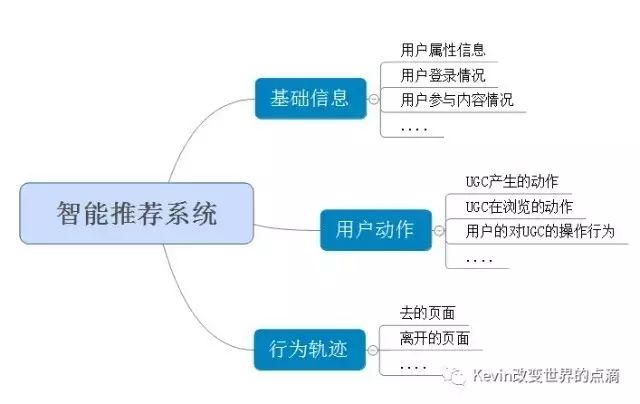
【基础信息的采集】
智能推荐系统通常会有一个智能推荐引擎,其中引擎就是各种算法的结合,系统将基础的信息采集后会分别进入相应的采集库,通过引擎将平台中的内容推荐给与相应的用户,这一点在行业中今日头条一直处于领先。
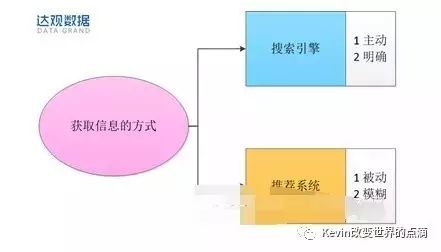
【推荐引擎】
智能推荐系统,增加了用户停留在FEED的时间长度变长的可能性,但智能推荐系统仍然是目前中小型企业所必须要去以后过渡的一种算法,比如智能推荐系统在FEED中,给予用户的就是非线性时间轴,用户会有一种,昨天球赛比赛完了,但今天刷新出FEED说,“球赛开始了”这种FEED错觉。
当然算法的精度与过滤,也是PM需要去考虑的,这里简单说明下推荐系统的大概。
4.高并发量与高用户UGC社区中,FEED的算法设计
在常规的产品线中,用户数量在百万内,根据产品的属性不同其日活跃可能在30%,也可能因为运营推广做的数据质量太差,活跃可能在1%,但存在高并发量UGC,也就是在用户的FEED产生能够在一时间轴的纬度下,会有上千、上百或更多的FEED产生,如何去踢去无效的FEED,将有效的FEED推荐给与用户,其业务流程如下:
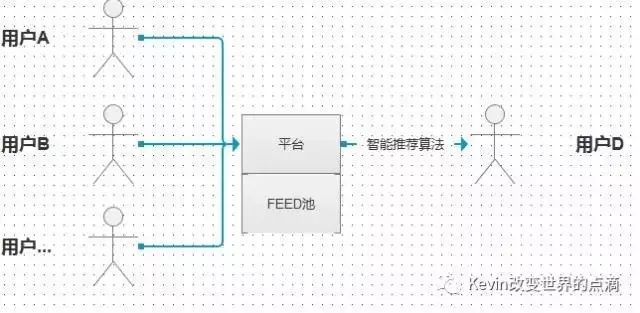
【FEED的出入流程】
这里用户在拉去FEED的过程中,这里我们常有的是三种算法,第一种是PUSH、第二种是拉、第三种是推和拉集合。
其中推类似以FACEBOOK这样的,将FEED推给用户,用户将直接接受到其FEED
【推的模式】
拉的模式恰恰相反,类似与新浪微博的形式每用户下拉其将其FEED存储区的FEED拉进来,而不是全部获得存储区的FEED。
FEED存储区
这里说到FEED存储区,就要引入未读池的概念,如何在高并发量以及高量FEED产生的情况下,保证用户能够索取到想要的内容?

【FEED存储】
这个就是FEED的存储方式,将其FEED存储在数据库中,我们以最近的FEED、近期FEED、比较长期的FEED,3个时间区进行存储。
刚才上面说的关于重力排序法中,时间段的区分,就是在这里进行时间区分,其中这个时间刷新我列举了3个小时、1天、7天,但这个时间段产品经理应该利用自己的数据分析能力,将其UGC社区中的FEED量进行统计,预算出其可行的FEED时间划分段
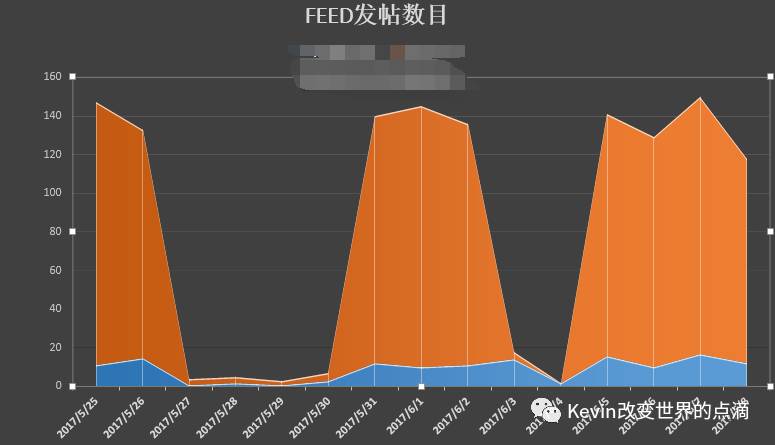
【FEED随时间的发帖数】
如以上FEED因每天产生的内容在100条FEED左右,因此建议用3小时、1天、7天作为时间点,太短了FEED也没有新的生成,太长了也没办法将FEED进行拿出
但请注意的是,这里是的FEED并发量低的时候或量不多的时候
5.那么回到刚才的问题,高并发量或高FEED量怎么办?
这个时候我们就要引入未读池的概念,这也是我猜测微博所采用的一套机制。在FEED产生高并发的情况下,用户下拉的FEED不可能把整个平台的FEED全部拉取(几千上万条,看都看不完),当然产生这么多的FEED原因是因为微博的定位并不是做好友间的社交关系链,而是以用户之间、人与人之间的社交关系
对于微博的UGC模块中,FEED其核心的就在于未读池的算法处理(这里我猜测是以智能推荐,早期可能是重力排序法)

【未读池FEED】
这样的FEED产生之后,其在未读池中,FEED可能会出现永远都不可能被用户阅读到,系统通过之前我说明智能推荐算法,将其认为的垃圾FEED或无效FEED永远不上传给予用户,因此这套机制就能够解决高并发量的情况下,给予用户有效的FEED
但这里也会存在一个问题,因为FEED的产生有时间属性,因此用户在拉去FEED是的时候会发现有一些FEED因为不具备时间轴的顺序,本来昨天发生的事情,今天才拉去出来。让用户产生摸不着头脑的感觉
对于FEED,这是一个UGC的必备属性,产品经理需要不断的学习和思考根据自己的产品业务属性、产品定位来制定相应的算法,但市面上大部分的产品对于FEED的把控依旧不够,这里的原因有很多,其中最重要的就是FEED的高并发、用户数太少,比如微博、微信这样大体量的产品,不是每天都可能诞生。
但是对于FEED的过滤,PM至少应该知道其算法,在近期产品需求调研中工作中,我希望将学习到的FEED算法共享,第一是相关资料比较少;第二是目前FEED的算法相对来说其门槛较高。
投稿邮箱:[email protected]
本文由作者授权早读课发表,转载请联系作者。